
As organizations embrace generative AI powered by Amazon Bedrock, they face the problem of managing prices related to the token-based pricing mannequin. Amazon Bedrock presents a pay-as-you-go pricing construction that may doubtlessly result in surprising and extreme payments if utilization shouldn’t be rigorously monitored. Conventional strategies of value monitoring, akin to price range alerts and price anomaly detection, may help spot unexpectedly excessive utilization however are reactive in nature. To deal with prices proactively, it’s important to make use of each main and trailing indicators.
Main indicators are predictive indicators that assist you anticipate future developments or potential points earlier than they absolutely materialize. These indicators present proactive insights that permit for well timed intervention. In distinction, trailing indicators are retrospective measurements that verify what has already occurred. By understanding and monitoring each varieties of indicators, organizations can develop extra strategic and responsive decision-making processes.
On this two-part collection, we introduce a complete answer for proactively managing Amazon Bedrock inference prices. Our method contains a value sentry mechanism designed to ascertain and implement token utilization limits, offering organizations with a sturdy framework for controlling generative AI bills. On this publish, we concentrate on core structure, value sentry design, token utilization monitoring, and preliminary price range enforcement methods. In Half 2, we discover superior monitoring methods, customized tagging, reporting, and long-term value optimization finest practices. The aim is to ship a predictable, cost-effective method to Amazon Bedrock deployments that aligns with organizational monetary constraints.
Resolution overview
Amazon Bedrock is billed on a token usage-based coverage with prices primarily based on the enter and output tokens used. The speed charged depends upon the mannequin used and AWS Area the place inference is carried out. Builders should implement strong token administration methods of their functions to assist forestall runaway prices, ensuring generative AI functions embrace circuit breakers and consumption limits that align with budgetary constraints.
To deal with this, you may configure Amazon CloudWatch alarms or monitor prices with billing alerts and budgets, however these mechanisms have a look at incurred prices or utilization after the very fact. An alternative choice is the Generative AI Gateway Resolution within the AWS Options Library, which makes use of LiteLLM to implement budgetary limits for Amazon Bedrock and different mannequin suppliers.
This answer was developed to establish a proactive, centralized mechanism that might restrict the generative AI utilization to a particular price range that may be adjusted. This method makes use of serverless workflows and native Amazon Bedrock integration that gives much less operational complexity whereas offering large-scale efficiency and scaling.
When constructing functions with Amazon Bedrock, it’s common apply to entry the service by means of a developed API, both synchronously by means of a REST API or asynchronously by means of a queuing system. The next diagram compares these architectures.
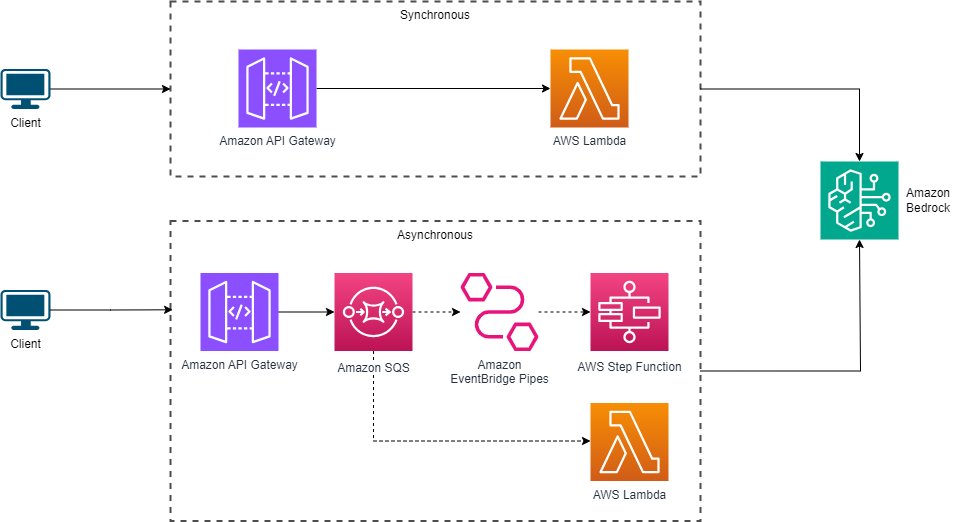
For synchronous interactions, shoppers make direct REST API calls to Amazon Bedrock, passing within the mandatory parameters. In an asynchronous structure, shoppers submit inference requests to a queue or message dealer, akin to Amazon Easy Queue Service (Amazon SQS). A backend processing system, typically carried out as a serverless perform or a containerized utility, constantly screens the queue and processes incoming requests. This method decouples the consumer from the inference processing, enabling scalability and resilience in dealing with bursts of requests.
This answer is a centralized mechanism that can be utilized to work together with Amazon Bedrock to function a proactive value sentry. It’s designed utilizing a serverless structure that makes use of AWS Step Capabilities to orchestrate a workflow that validates token utilization towards configured limits earlier than permitting Amazon Bedrock inference requests to proceed. This answer makes positive that generative AI functions keep inside predefined budgetary boundaries, offering value predictability and management.
The next diagram illustrates the structure we construct on this publish.
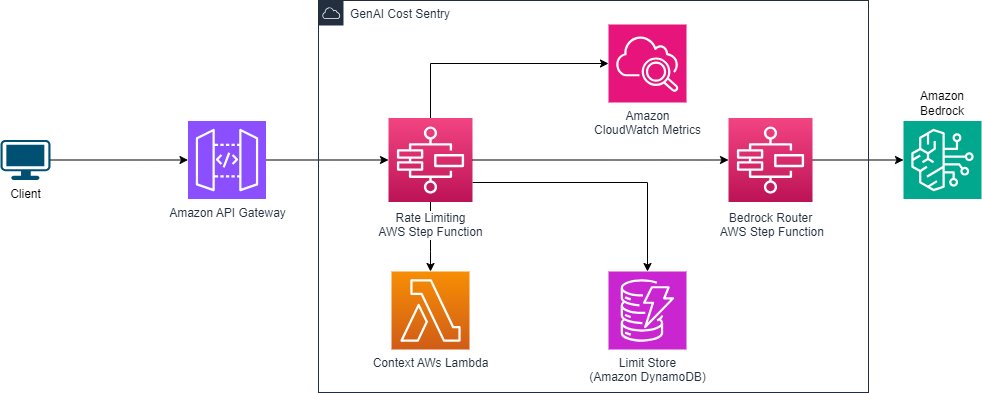
The core parts of this answer embrace:
- Fee limiter workflow – A Step Capabilities workflow that retrieves present token utilization metrics from CloudWatch, compares them towards predefined limits saved in Amazon DynamoDB, and determines whether or not to proceed with or deny the Amazon Bedrock inference request.
- Amazon Bedrock mannequin router – A separate Step Capabilities state machine that acts as a centralized gateway for invoking numerous Amazon Bedrock fashions. This element abstracts the complexity of dealing with completely different I/O parameters required by every mannequin.
- Token utilization monitoring – Makes use of CloudWatch metrics integration with Amazon Bedrock to retrieve present token utilization knowledge for enter and output tokens throughout all or particular fashions.
- Finances configuration – Permits setting token utilization limits on a per-model foundation by storing the specified price range values in DynamoDB. A default restrict will also be set to use to fashions with out particular budgets outlined.
- Price and utilization visibility – Gives visibility for AI utilization with CloudWatch dashboards and price over time reporting in AWS Price Explorer.
The answer follows a serverless structure method, utilizing managed AWS companies like Step Capabilities, AWS Lambda, DynamoDB, and CloudWatch to supply a scalable, extensible, and cost-effective implementation.
The aim is to supply a proactive technique of setting generative AI utilization limits that function as a number one indicator to restrict utilization:
- Proactive budgeting – Enforces token utilization limits earlier than permitting inference requests, serving to forestall unintended overspending
- Mannequin-specific budgets – Helps setting particular person budgets for various Amazon Bedrock fashions primarily based on their pricing and utilization patterns
- Default price range fallback – If no particular price range is outlined for a mannequin, a default restrict could be utilized to allow value management
- Monitoring – Makes use of CloudWatch metrics integration to trace token utilization, enabling correct price range enforcement
- Serverless structure – Makes use of Step Capabilities, Lambda, DynamoDB, and CloudWatch for a scalable and cost-effective answer
- Extensibility – The modular design permits for seamless integration of further Amazon Bedrock fashions or various inference strategies
Step Capabilities workflows
On this part, we discover how the answer makes use of Step Capabilities to implement charge limiting and mannequin routing workflows.
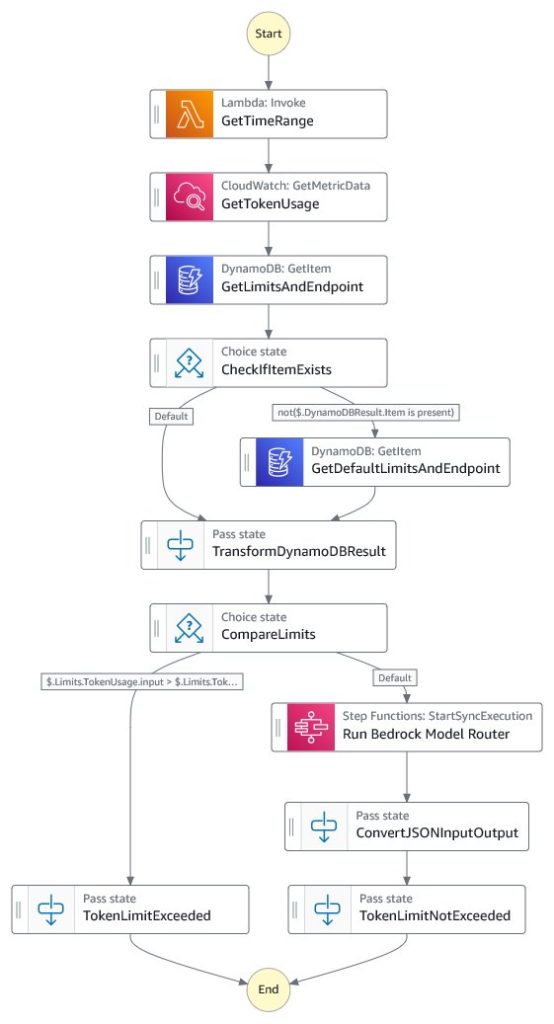
Fee limiting workflow
The speed limiting workflow is designed to take a minimal JSON doc as enter with the next format:
This workflow is the core element that enforces budgetary controls. The important thing steps are as follows:
- A Lambda perform retrieves the beginning and finish dates for the present month, which is used to question token utilization metrics for the suitable time vary.
- The workflow queries CloudWatch to retrieve the present month’s token utilization metrics for the desired Amazon Bedrock mannequin.
- The workflow retrieves the configured token utilization restrict for the desired Amazon Bedrock mannequin from DynamoDB. If no particular restrict is discovered, it falls again to retrieving the default restrict.
- The workflow compares the present token utilization towards the configured restrict to find out if the price range has been exceeded or not.
- If the token utilization is inside the price range, this step invokes the Amazon Bedrock mannequin router state machine to carry out the precise inference request.
- Relying on the result of the price range examine, the workflow returns both the formatted inference end result or an error indicating that the price range has been exceeded.
The next diagram illustrates the Step Capabilities workflow.
Amazon Bedrock mannequin router workflow
The Amazon Bedrock mannequin router workflow is a separate Step Capabilities state machine answerable for invoking the suitable Amazon Bedrock mannequin primarily based on the request parameters. It abstracts the complexity of dealing with completely different I/O codecs required by numerous Amazon Bedrock fashions and combines the end result right into a standardized format.
The important thing steps within the workflow embrace:
- Primarily based on the supplied mannequin ID, the workflow determines the particular Amazon Bedrock mannequin to be invoked.
- The workflow calls the suitable Amazon Bedrock mannequin with the required enter parameters.
- The workflow normalizes the output from the Amazon Bedrock mannequin to a constant format for additional processing or returning to the consumer.
- The workflow returns the reworked inference end result to the calling workflow (price range sentry workflow).
The next diagram illustrates the Step Capabilities workflow.
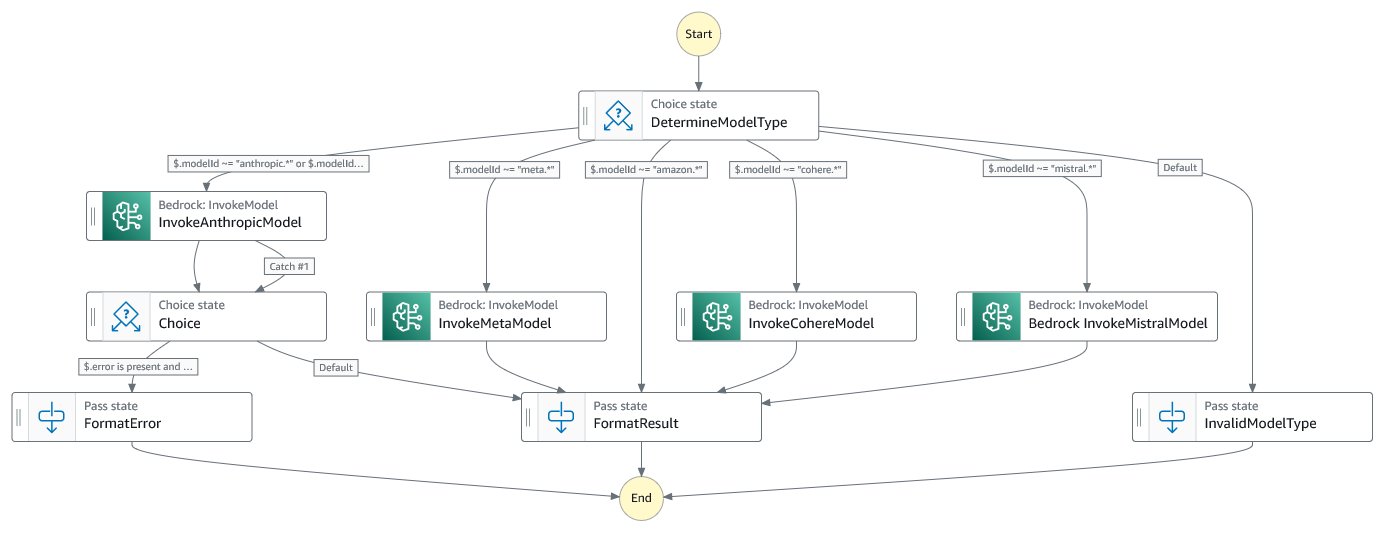
You possibly can implement further steps to deal with error situations and format the output appropriately. On this instance, the Anthropic circulate contains error processing.
Token utilization monitoring with CloudWatch metrics
The Amazon Bedrock value sentry makes use of the CloudWatch integration with Amazon Bedrock to retrieve present token utilization metrics. These metrics are used to implement budgetary limits proactively. For instance, see the next question:
This CloudWatch metric question retrieves the entire enter and output token counts for a specified time vary, permitting the speed limiter workflow to precisely implement budgets primarily based on real-time utilization knowledge.
Finances configuration with DynamoDB
The Amazon Bedrock value sentry shops token utilization limits in a DynamoDB desk, offering seamless configuration and updates to particular person mannequin budgets or the default restrict. For instance, see the next code:
On this instance, the token utilization restrict for the desired Amazon Bedrock mannequin (anthropic.claude-3-sonnet-20240229-v1:0) is about to 1,000,000 enter tokens and three,000,000 output tokens.
Directors can rapidly replace these limits by modifying the corresponding DynamoDB data, offering flexibility in adjusting budgets as wanted.
Efficiency evaluation of the speed limiter workflow
To evaluate the efficiency influence of introducing the workflow, we used an array of inference requests. Check instances included numerous prompts designed to generate responses starting from concise solutions to detailed explanations over 500 phrases, successfully testing the workflow’s efficiency throughout completely different output token sizes. The workflow demonstrated distinctive efficiency traits throughout 501 profitable executions, dealing with a various set of inference requests from transient responses to in depth content material era.
The workflow maintains constant execution patterns whereas processing requests starting from 6.76 seconds to 32.24 seconds in whole length, with the variation primarily reflecting the completely different output token necessities of every request:
- Fast responses (beneath 10 seconds) – Usually dealing with concise solutions and easy queries
- Medium-length content material (11–22 seconds) – Widespread for detailed explanations and multi-paragraph responses
- Prolonged era (as much as 32 seconds) – Dealing with complete responses requiring greater than 500 phrases
The next diagram illustrates our time distribution findings.
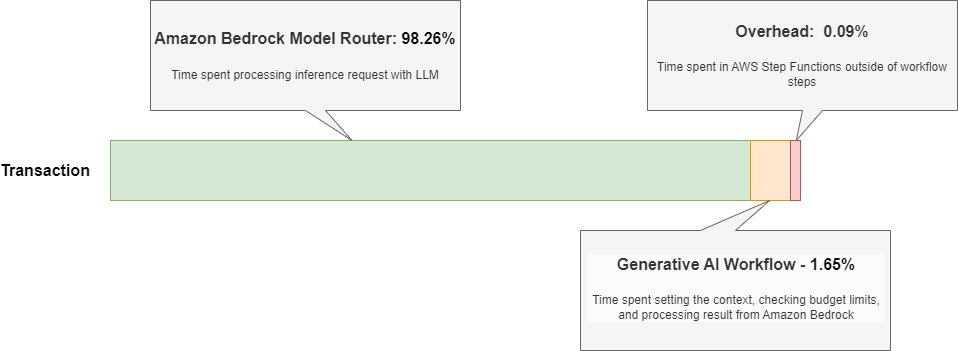
The time distribution evaluation reveals extremely optimized useful resource utilization:
- Amazon Bedrock mannequin router – 5.80–31.99 seconds (98.26% of runtime)
- Different workflow steps – 0.11–4.74 seconds (1.65% of runtime)
- System overhead – 0.02 seconds common (0.09% of runtime)
This efficiency profile aligns with finest practices for workflow orchestration, the place minimizing overhead and sustaining constant execution patterns are essential for reliability. The workflow’s effectivity is evidenced by its remarkably low system overhead of simply 0.09%, demonstrating efficient use of the built-in controls and state administration capabilities of Step Capabilities whatever the response measurement being generated.
The execution consistency is especially noteworthy, with a predictable occasion sample of 47–49 occasions per execution, whatever the inference request complexity or output measurement. This predictability is crucial for workload administration and useful resource planning, particularly when dealing with diverse request complexities and token outputs.
These metrics point out a well-architected workflow that successfully makes use of Step Capabilities Categorical workflow capabilities for high-volume occasion processing whereas sustaining minimal overhead and constant efficiency traits throughout each easy queries and sophisticated, token-intensive inference requests.
Price evaluation
To investigate the fee implications, estimates have been generated utilizing the AWS Pricing Calculator for each Customary and Categorical Step Capabilities workflows, assuming 100,000 requests per thirty days. The next desk summarizes these estimates.
| Detailed Estimate | |||||||
| Area | Description | Service | Upfront | Month-to-month | First 12 Months Whole | Forex | Configuration Abstract |
| US East (Ohio) | Step Capabilities Customary | Step Capabilities – Customary Workflows | 0 | $37.40 | $448.80 | USD | Workflow requests (100,000 per thirty days)State transitions per workflow (15) |
| US East (Ohio) | Step Capabilities Categorical | Step Capabilities – Categorical Workflows | 0 | $3.75 | $45 | USD | Period of every workflow (35,000)Reminiscence consumed by every workflow (64 MB)Workflow requests (100,000 per thirty days) |
The associated fee evaluation revealed that the Step Capabilities Categorical workflow presents a more cost effective answer in comparison with the Customary workflow, with potential value financial savings of as much as 90% for a similar workload. There’s a potential for value discount for Customary if the variety of steps could be optimized. For instance, a number of formatting move steps may doubtlessly be eliminated, however these steps assist format the downstream enter to later steps.
Seek the advice of the AWS Pricing Calculator for extra particulars on pricing and to run your personal state of affairs.
Conclusion
On this answer, we used Step Capabilities to construct a system that serves as a number one indicator as a result of it tracks charge limiting and token utilization, warning us instantly after we’re approaching our utilization limits. In Half 2, we focus on combining this with trailing indicators to remain conscious of utilization and prices.
In regards to the writer
 Jason Salcido is a Startups Senior Options Architect with practically 30 years of expertise pioneering modern options for organizations from startups to enterprises. His experience spans cloud structure, serverless computing, machine studying, generative AI, and distributed techniques. Jason combines deep technical information with a forward-thinking method to design scalable options that drive worth, whereas translating advanced ideas into actionable methods.
Jason Salcido is a Startups Senior Options Architect with practically 30 years of expertise pioneering modern options for organizations from startups to enterprises. His experience spans cloud structure, serverless computing, machine studying, generative AI, and distributed techniques. Jason combines deep technical information with a forward-thinking method to design scalable options that drive worth, whereas translating advanced ideas into actionable methods.



{kind=link}