At the moment, we’re excited to announce that Mercury and Mercury Coder basis fashions (FMs) from Inception Labs can be found by means of Amazon Bedrock Market and Amazon SageMaker JumpStart. With this launch, you’ll be able to deploy the Mercury FMs to construct, experiment, and responsibly scale your generative AI functions on AWS.
On this put up, we show how you can get began with Mercury fashions on Amazon Bedrock Market and SageMaker JumpStart.
About Mercury basis fashions
Mercury is the primary household of commercial-scale diffusion-based language fashions, providing groundbreaking developments in era pace whereas sustaining high-quality outputs. Not like conventional autoregressive fashions that generate textual content one token at a time, Mercury fashions use diffusion to generate a number of tokens in parallel by means of a coarse-to-fine method, leading to dramatically quicker inference speeds. Mercury Coder fashions ship the next key options:
- Extremely-fast era speeds of as much as 1,100 tokens per second on NVIDIA H100 GPUs, as much as 10 instances quicker than comparable fashions
- Excessive-quality code era throughout a number of programming languages, together with Python, Java, JavaScript, C++, PHP, Bash, and TypeScript
- Sturdy efficiency on fill-in-the-middle duties, making them supreme for code completion and enhancing workflows
- Transformer-based structure, offering compatibility with present optimization methods and infrastructure
- Context size help of as much as 32,768 tokens out of the field and as much as 128,000 tokens with context extension approaches
About Amazon Bedrock Market
Amazon Bedrock Market performs a pivotal function in democratizing entry to superior AI capabilities by means of a number of key benefits:
- Complete mannequin choice – Amazon Bedrock Market affords an distinctive vary of fashions, from proprietary to publicly out there choices, so organizations can discover the right match for his or her particular use circumstances.
- Unified and safe expertise – By offering a single entry level for fashions by means of the Amazon Bedrock APIs, Amazon Bedrock Market considerably simplifies the mixing course of. Organizations can use these fashions securely, and for fashions which can be appropriate with the Amazon Bedrock Converse API, you should use the sturdy toolkit of Amazon Bedrock, together with Amazon Bedrock Brokers, Amazon Bedrock Data Bases, Amazon Bedrock Guardrails, and Amazon Bedrock Flows.
- Scalable infrastructure – Amazon Bedrock Market affords configurable scalability by means of managed endpoints, so organizations can choose their desired variety of cases, select acceptable occasion varieties, outline customized automated scaling insurance policies that dynamically modify to workload calls for, and optimize prices whereas sustaining efficiency.
Deploy Mercury and Mercury Coder fashions in Amazon Bedrock Market
Amazon Bedrock Market offers you entry to over 100 in style, rising, and specialised basis fashions by means of Amazon Bedrock. To entry the Mercury fashions in Amazon Bedrock, full the next steps:
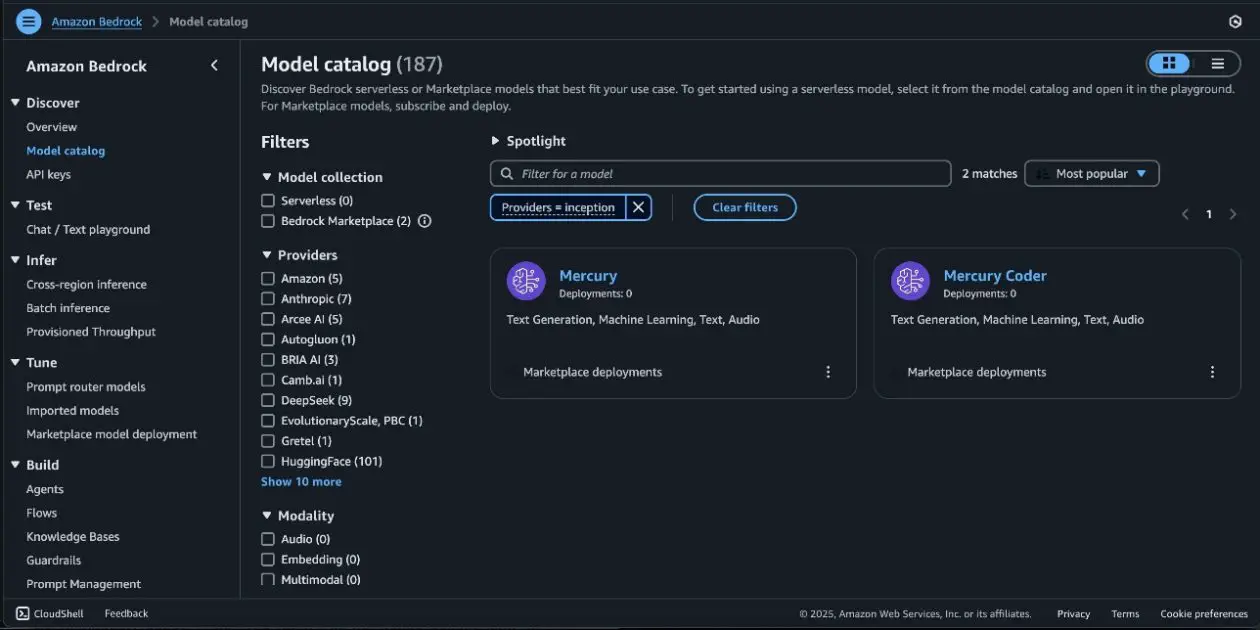
- On the Amazon Bedrock console, within the navigation pane below Basis fashions, select Mannequin catalog.
You may also use the Converse API to invoke the mannequin with Amazon Bedrock tooling.
- On the Mannequin catalog web page, filter for Inception as a supplier and select the Mercury mannequin.
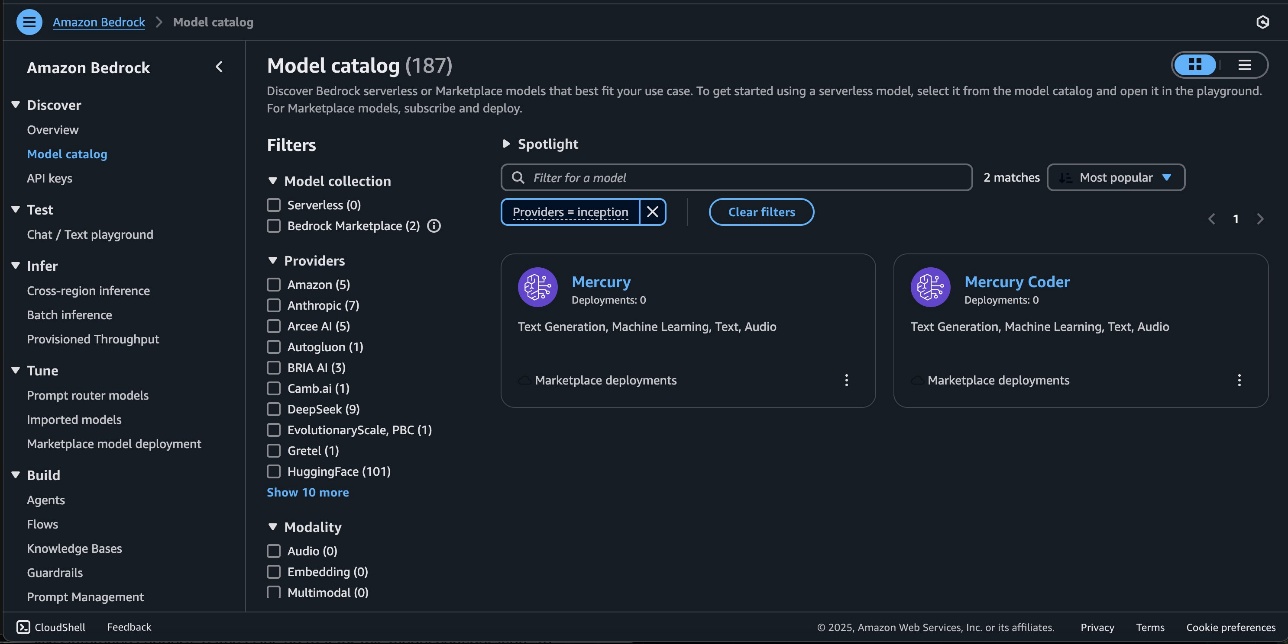
The Mannequin element web page supplies important details about the mannequin’s capabilities, pricing construction, and implementation pointers. You will discover detailed utilization directions, together with pattern API calls and code snippets for integration.
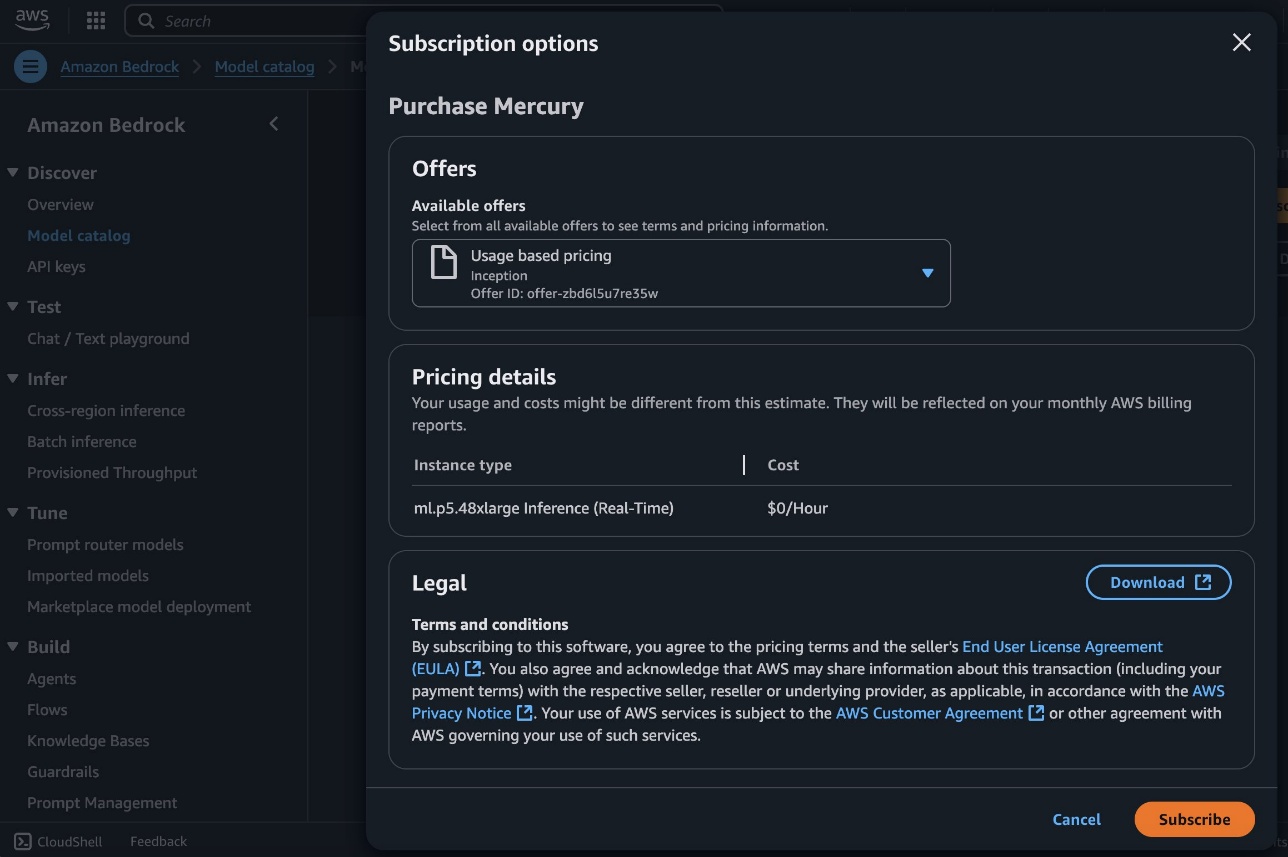
- To start utilizing the Mercury mannequin, select Subscribe.
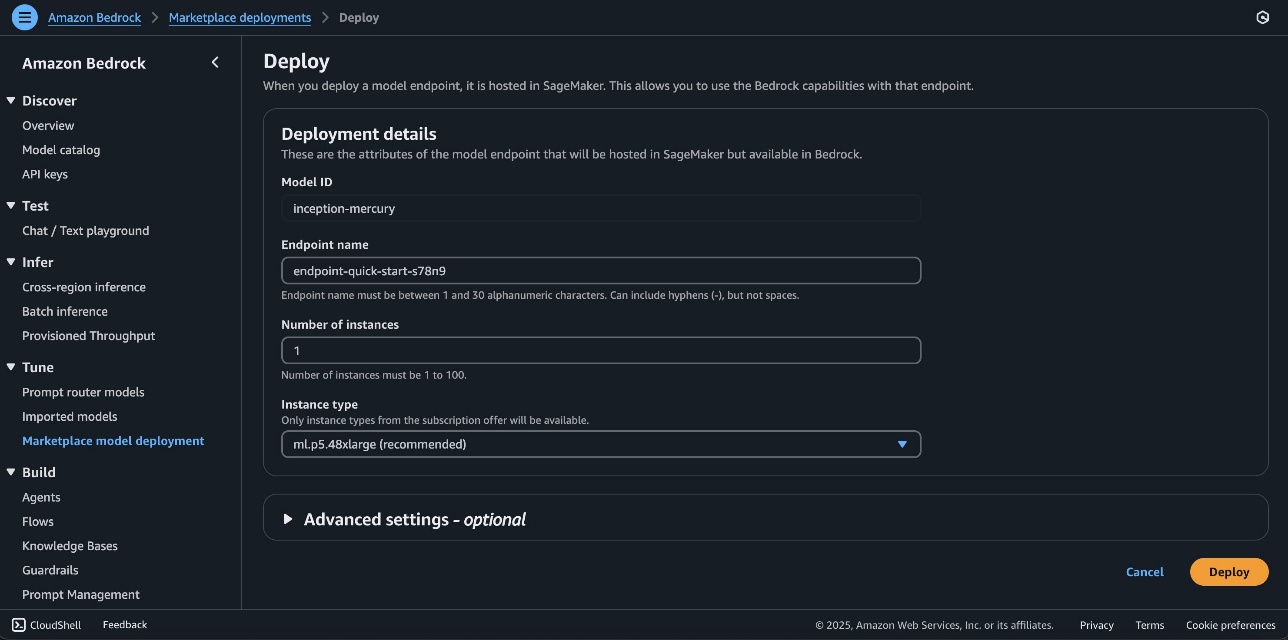
- On the mannequin element web page, select Deploy.
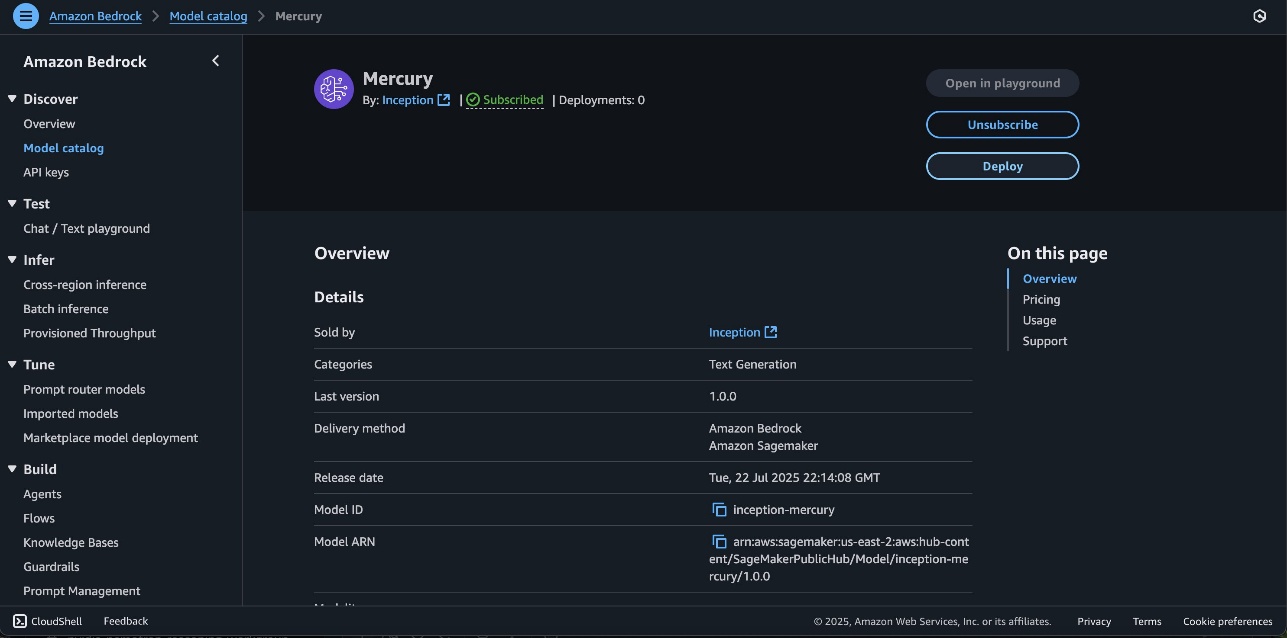
You’ll be prompted to configure the deployment particulars for the mannequin. The mannequin ID shall be prepopulated.
- For Endpoint identify, enter an endpoint identify (between 1–50 alphanumeric characters).
- For Variety of cases, enter a lot of cases (between 1–100).
- For Occasion sort, select your occasion sort. For optimum efficiency with Nemotron Tremendous, a GPU-based occasion sort like ml.p5.48xlarge is really helpful.
- Optionally, you’ll be able to configure superior safety and infrastructure settings, together with digital personal cloud (VPC) networking, service function permissions, and encryption settings. For many use circumstances, the default settings will work properly. Nevertheless, for manufacturing deployments, you would possibly wish to evaluate these settings to align together with your group’s safety and compliance necessities.
- Select Deploy to start utilizing the mannequin.
When the deployment is full, you’ll be able to take a look at its capabilities straight within the Amazon Bedrock playground.This is a wonderful technique to discover the mannequin’s reasoning and textual content era talents earlier than integrating it into your functions. The playground supplies speedy suggestions, serving to you perceive how the mannequin responds to varied inputs and letting you fine-tune your prompts for optimum outcomes. You should utilize these fashions with the Amazon Bedrock Converse API.
SageMaker JumpStart overview
SageMaker JumpStart is a totally managed service that provides state-of-the-art FMs for varied use circumstances resembling content material writing, code era, query answering, copywriting, summarization, classification, and knowledge retrieval. It supplies a group of pre-trained fashions which you can deploy shortly, accelerating the event and deployment of ML functions. One of many key parts of SageMaker JumpStart is mannequin hubs, which supply an enormous catalog of pre-trained fashions, resembling Mistral, for a wide range of duties.
Now you can uncover and deploy Mercury and Mercury Coder in Amazon SageMaker Studio or programmatically by means of the SageMaker Python SDK, and derive mannequin efficiency and MLOps controls with Amazon SageMaker AI options resembling Amazon SageMaker Pipelines, Amazon SageMaker Debugger, or container logs. The mannequin is deployed in a safe AWS surroundings and in your VPC, serving to help information safety for enterprise safety wants.
Stipulations
To deploy the Mercury fashions, be sure you have entry to the really helpful occasion varieties based mostly on the mannequin dimension. To confirm you may have the mandatory sources, full the next steps:
- On the Service Quotas console, below AWS Providers, select Amazon SageMaker.
- Verify that you’ve got enough quota for the required occasion sort for endpoint deployment.
- Ensure that not less than one among these occasion varieties is on the market in your goal AWS Area.
- If wanted, request a quota improve and get in touch with your AWS account crew for help.
Ensure that your SageMaker AWS Identification and Entry Administration (IAM) service function has the mandatory permissions to deploy the mannequin, together with the next permissions to make AWS Market subscriptions within the AWS account used:
aws-marketplace:ViewSubscriptionsaws-marketplace:Unsubscribeaws-marketplace:Subscribe
Alternatively, verify your AWS account has a subscription to the mannequin. If that’s the case, you’ll be able to skip the next deployment directions and begin with subscribing to the mannequin package deal.
Subscribe to the mannequin package deal
To subscribe to the mannequin package deal, full the next steps:
- Open the mannequin package deal itemizing web page and select Mercury or Mercury Coder.
- On the AWS Market itemizing, select Proceed to subscribe.
- On the Subscribe to this software program web page, evaluate and select Settle for Supply should you and your group agree with the EULA, pricing, and help phrases.
- Select Proceed to proceed with the configuration after which select a Area the place you may have the service quota for the specified occasion sort.
A product Amazon Useful resource Title (ARN) shall be displayed. That is the mannequin package deal ARN that it is advisable specify whereas making a deployable mannequin utilizing Boto3.
Deploy Mercury and Mercury Coder fashions on SageMaker JumpStart
For these new to SageMaker JumpStart, you should use SageMaker Studio to entry the Mercury and Mercury Coder fashions on SageMaker JumpStart.
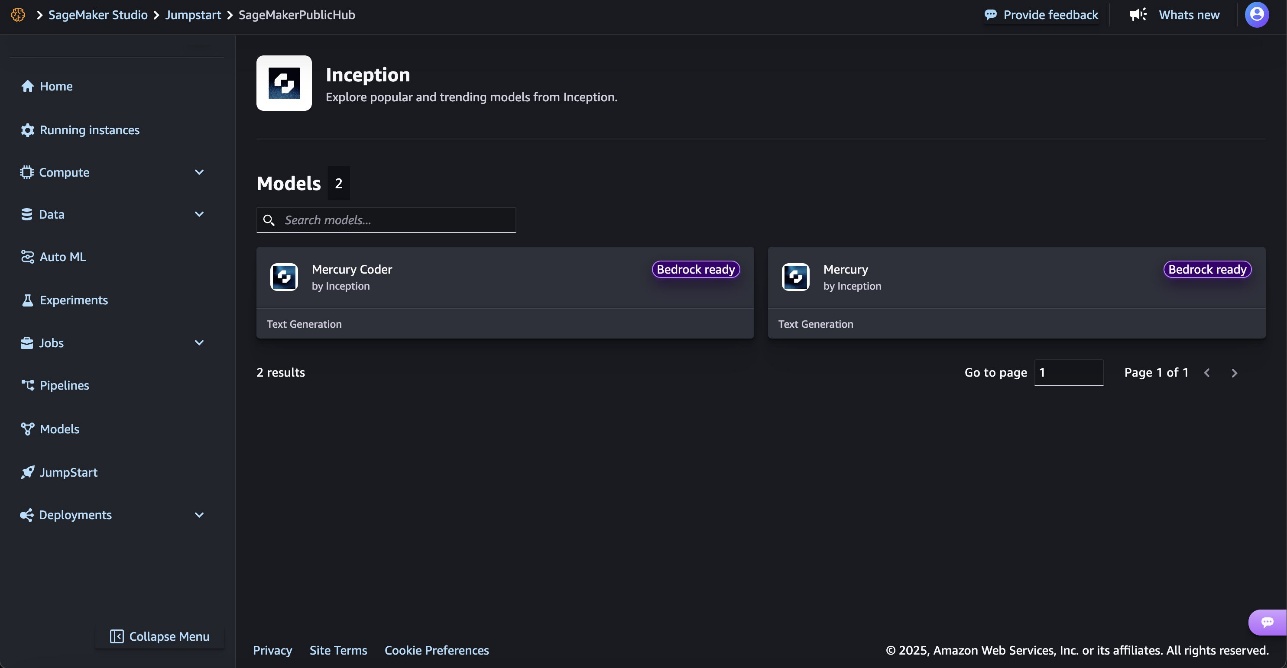
Deployment begins whenever you select the Deploy possibility. You may be prompted to subscribe to this mannequin by means of Amazon Bedrock Market. In case you are already subscribed, select Deploy. After deployment is full, you will note that an endpoint is created. You’ll be able to take a look at the endpoint by passing a pattern inference request payload or by deciding on the testing possibility utilizing the SDK.
Deploy Mercury utilizing the SageMaker SDK
On this part, we stroll by means of deploying the Mercury mannequin by means of the SageMaker SDK. You’ll be able to observe the same course of for deploying the Mercury Coder mannequin as properly.
To deploy the mannequin utilizing the SDK, copy the product ARN from the earlier step and specify it within the model_package_arn within the following code:
Deploy the mannequin:
Use Mercury for code era
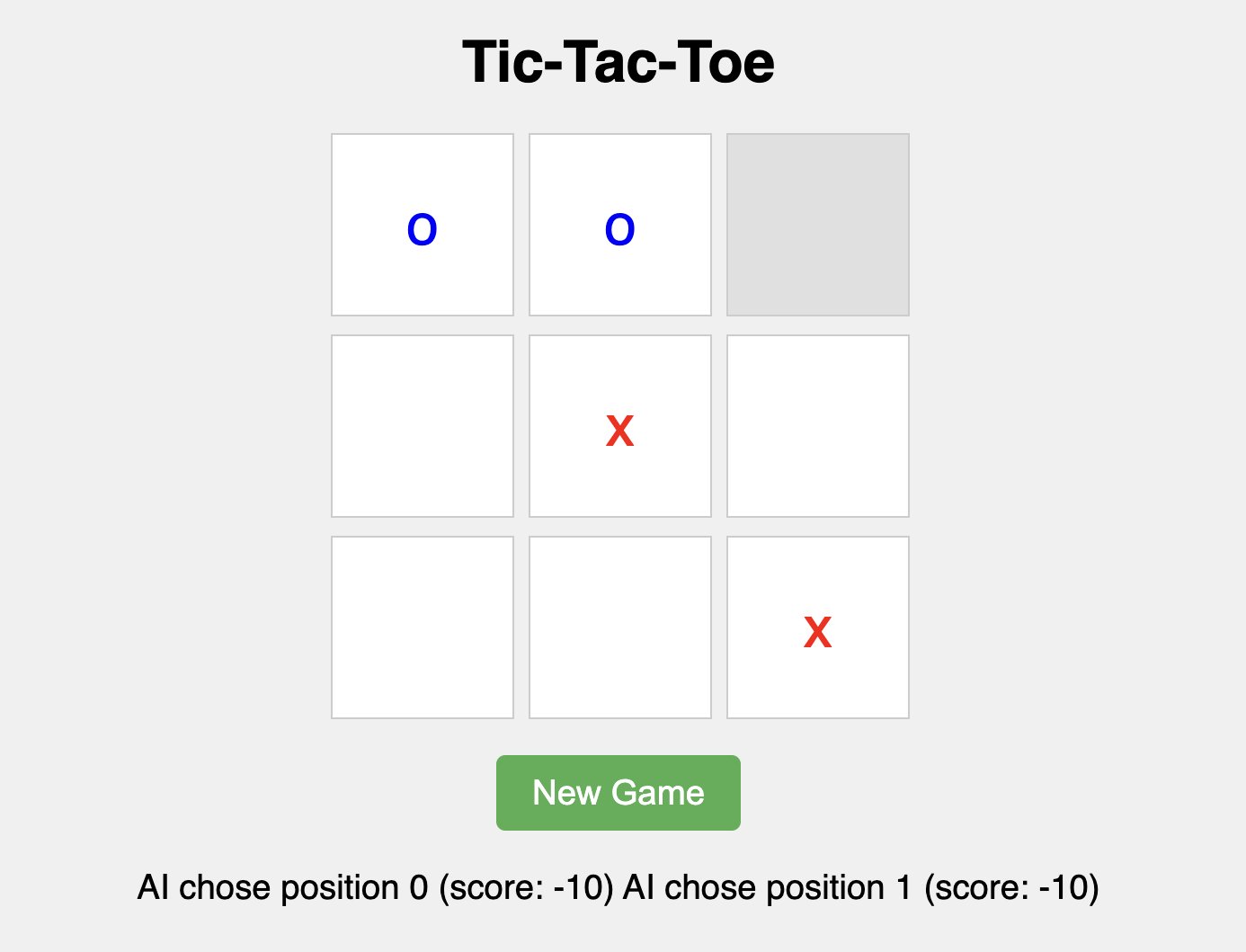
Let’s attempt asking the mannequin to generate a easy tic-tac-toe recreation:
We get the next response:
From the previous response, we will see that the Mercury mannequin generated a whole, purposeful tic-tac-toe recreation with minimax AI implementation at 528 tokens per second, delivering working HTML, CSS, and JavaScript in a single response. The code contains correct recreation logic, an unbeatable AI algorithm, and a clear UI with the required necessities appropriately carried out. This demonstrates sturdy code era capabilities with distinctive pace for a diffusion-based mannequin.
Use Mercury for instrument use and performance calling
Mercury fashions help superior instrument use capabilities, enabling them to intelligently decide when and how you can name exterior capabilities based mostly on person queries. This makes them supreme for constructing AI brokers and assistants that may work together with exterior methods, APIs, and databases.
Let’s show Mercury’s instrument use capabilities by making a journey planning assistant that may examine climate and carry out calculations:
Anticipated response:
After receiving the instrument outcomes, you’ll be able to proceed the dialog to get a pure language response:
Anticipated response:
Clear up
To keep away from undesirable expenses, full the steps on this part to wash up your sources.
Delete the Amazon Bedrock Market deployment
In case you deployed the mannequin utilizing Amazon Bedrock Market, full the next steps:
- On the Amazon Bedrock console, within the navigation pane, below Basis fashions, select Market deployments.
- Choose the endpoint you wish to delete, and on the Actions menu, select Delete.
- Confirm the endpoint particulars to be sure you’re deleting the right deployment:
- Endpoint identify
- Mannequin identify
- Endpoint standing
- Select Delete to delete the endpoint.
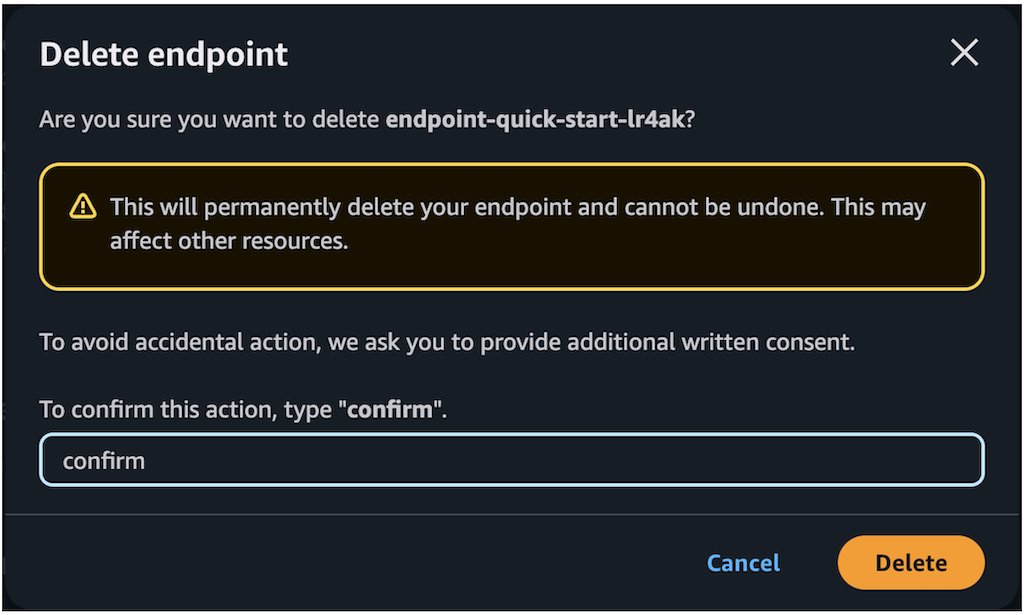
- Within the Delete endpoint affirmation dialog, evaluate the warning message, enter
verify, and select Delete to completely take away the endpoint.
Delete the SageMaker JumpStart endpoint
The SageMaker JumpStart mannequin you deployed will incur prices should you depart it operating. Use the next code to delete the endpoint if you wish to cease incurring expenses. For extra particulars, see Delete Endpoints and Assets.
Conclusion
On this put up, we explored how one can entry and deploy Mercury fashions utilizing Amazon Bedrock Market and SageMaker JumpStart. With help for each Mini and Small parameter sizes, you’ll be able to select the optimum mannequin dimension to your particular use case. Go to SageMaker JumpStart in SageMaker Studio or Amazon Bedrock Market to get began. For extra data, seek advice from Use Amazon Bedrock tooling with Amazon SageMaker JumpStart fashions, Amazon SageMaker JumpStart Basis Fashions, Getting began with Amazon SageMaker JumpStart, Amazon Bedrock Market, and SageMaker JumpStart pretrained fashions.
The Mercury household of diffusion-based giant language fashions affords distinctive pace and efficiency, making it a strong alternative to your generative AI workloads with latency-sensitive necessities.
Concerning the authors
 Niithiyn Vijeaswaran is a Generative AI Specialist Options Architect with the Third-Get together Mannequin Science crew at AWS. His space of focus is AWS AI accelerators (AWS Neuron). He holds a Bachelor’s diploma in Pc Science and Bioinformatics.
Niithiyn Vijeaswaran is a Generative AI Specialist Options Architect with the Third-Get together Mannequin Science crew at AWS. His space of focus is AWS AI accelerators (AWS Neuron). He holds a Bachelor’s diploma in Pc Science and Bioinformatics.
 John Liu has 15 years of expertise as a product government and 9 years of expertise as a portfolio supervisor. At AWS, John is a Principal Product Supervisor for Amazon Bedrock. Beforehand, he was the Head of Product for AWS Web3 / Blockchain. Previous to AWS, John held varied product management roles at public blockchain protocols, fintech firms and likewise spent 9 years as a portfolio supervisor at varied hedge funds.
John Liu has 15 years of expertise as a product government and 9 years of expertise as a portfolio supervisor. At AWS, John is a Principal Product Supervisor for Amazon Bedrock. Beforehand, he was the Head of Product for AWS Web3 / Blockchain. Previous to AWS, John held varied product management roles at public blockchain protocols, fintech firms and likewise spent 9 years as a portfolio supervisor at varied hedge funds.
 Rohit Talluri is a Generative AI GTM Specialist at Amazon Internet Providers (AWS). He’s partnering with prime generative AI mannequin builders, strategic prospects, key AI/ML companions, and AWS Service Groups to allow the following era of synthetic intelligence, machine studying, and accelerated computing on AWS. He was beforehand an Enterprise Options Architect and the International Options Lead for AWS Mergers & Acquisitions Advisory.
Rohit Talluri is a Generative AI GTM Specialist at Amazon Internet Providers (AWS). He’s partnering with prime generative AI mannequin builders, strategic prospects, key AI/ML companions, and AWS Service Groups to allow the following era of synthetic intelligence, machine studying, and accelerated computing on AWS. He was beforehand an Enterprise Options Architect and the International Options Lead for AWS Mergers & Acquisitions Advisory.
 Breanne Warner is an Enterprise Options Architect at Amazon Internet Providers supporting healthcare and life science (HCLS) prospects. She is obsessed with supporting prospects to make use of generative AI on AWS and evangelizing mannequin adoption for first- and third-party fashions. Breanne can also be Vice President of the Ladies at Amazon board with the aim of fostering inclusive and various tradition at Amazon. Breanne holds a Bachelor’s of Science in Pc Engineering from the College of Illinois Urbana-Champaign.
Breanne Warner is an Enterprise Options Architect at Amazon Internet Providers supporting healthcare and life science (HCLS) prospects. She is obsessed with supporting prospects to make use of generative AI on AWS and evangelizing mannequin adoption for first- and third-party fashions. Breanne can also be Vice President of the Ladies at Amazon board with the aim of fostering inclusive and various tradition at Amazon. Breanne holds a Bachelor’s of Science in Pc Engineering from the College of Illinois Urbana-Champaign.



{kind=link}