The aim of this text IS NOT to offer the reply to the query: “Which one is ‘higher’ — Import or Direct Lake?” as a result of it’s unattainable to reply, as there isn’t a one resolution to “rule-them-all”… Whereas Import (nonetheless) must be a default alternative most often, there are specific eventualities through which you may select to take the Direct Lake path. The principle purpose of the article is to offer particulars about how Direct Lake mode works behind the scenes and shed extra mild on numerous Direct Lake ideas.
If you wish to study extra about how Import (and DirectQuery) compares to Direct Lake, and when to decide on one over the opposite, I strongly encourage you to observe the next video: https://www.youtube.com/watch?v=V4rgxmBQpk0
Now, we are able to begin…
I don’t find out about you, however after I watch motion pictures and see some breathtaking scenes, I’m at all times questioning — how did they do THIS?! What sort of methods did they pull out of their sleeves to make it work like that?
And, I’ve this sense when watching Direct Lake in motion! For these of you who might not have heard in regards to the new storage mode for Energy BI semantic fashions, or are questioning what Direct Lake and Allen Iverson have in frequent, I encourage you to begin by studying my earlier article.
The aim of this one is to demystify what occurs behind the scenes, how this “factor” truly works, and provide you with a touch about some nuances to remember when working with Direct Lake semantic fashions.
Direct Lake storage mode overcomes shortcomings of each Import and DirectQuery modes — offering a efficiency much like Import mode, with out knowledge duplication and knowledge latency — as a result of the info is being retrieved instantly from delta tables in the course of the question execution.
Appears like a dream, proper? So, let’s attempt to look at completely different ideas that allow this dream to return true…
Framing (aka Direct Lake “refresh”)
The most typical query I’m listening to today from purchasers is — how can we refresh the Direct Lake semantic mannequin? It’s a good query. Since they’ve been counting on Import mode for years, and Direct Lake guarantees an “import mode-like efficiency”… So, there needs to be an identical course of in place to maintain your knowledge updated, proper?
Effectively, ja-in… (What the heck is that this now, I hear you questioning😀). Germans have an ideal phrase (considered one of many, to be sincere) to outline one thing that may be each “Sure” and “No” (ja=YES, nein=NO). Chris Webb already wrote a nice weblog publish on the subject, so I received’t repeat issues written there (go and skim Chris’s weblog, this is among the greatest assets for studying Energy BI). My thought is as an instance the method occurring within the background and emphasize some nuances that may be impacted by your choices.
However, first issues first…
Syncing the info
When you create a Lakehouse in Microsoft Material, you’ll routinely get two further objects provisioned — SQL Analytics Endpoint for querying the info within the lakehouse (sure, you’ll be able to write T-SQL to READ the info from the lakehouse), and a default semantic mannequin, which incorporates all of the tables from the lakehouse. Now, what occurs when a brand new desk arrives within the lakehouse? Effectively, it relies upon:)
Should you open the Settings window for the SQL Analytics Endpoint, and go to the Default Energy BI semantic mannequin property, you’ll see the next choice:

This setting means that you can outline what occurs when a brand new desk arrives at a lakehouse. By default, this desk WILL NOT be routinely included within the default semantic mannequin. And, that’s the primary level related for “refreshing” the info in Direct Lake mode.
At this second, I’ve 4 delta tables in my lakehouse: DimCustomer, DimDate, DimProduct, and FactOnlineSales. Since I disabled auto-sync between the lakehouse and the semantic mannequin, there are at present no tables within the default semantic mannequin!

This implies I first want so as to add the info to my default semantic mannequin. As soon as I open the SQL Analytics Endpoint and select to create a brand new report, I’ll be prompted so as to add the info to the default semantic mannequin:

Okay, let’s look at what occurs if a brand new desk arrives within the lakehouse? I’ve added a brand new desk in lakehouse: DimCurrency.

However, after I select to create a report on high of the default semantic mannequin, there isn’t a DimCurrency desk out there:

I’ve now enabled the auto-sync choice and after a couple of minutes, the DimCurrency desk appeared within the default semantic mannequin objects view:

So, this sync choice means that you can determine if the brand new desk from the lakehouse can be routinely added to a semantic mannequin or not.
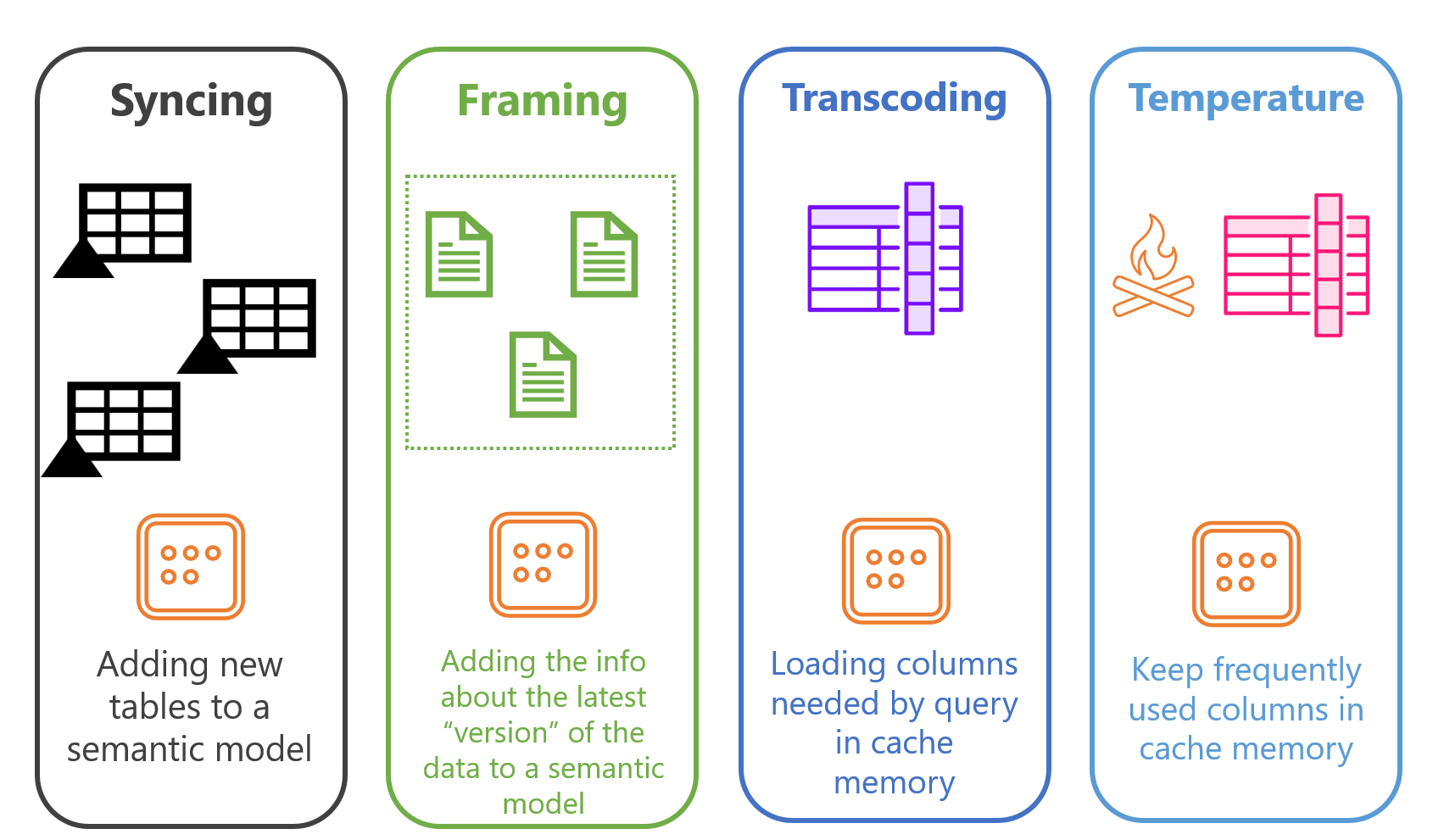
Syncing = Including new tables to a semantic mannequin
However, what occurs with the info itself? That means, if the info within the delta desk modifications, do we have to refresh a semantic mannequin, like we needed to do when utilizing Import mode to have the newest knowledge out there in our Energy BI reviews?
It’s the appropriate time to introduce the idea of framing. Earlier than that, let’s shortly look at how our knowledge is saved beneath the hood. I’ve already written in regards to the Parquet file format intimately, so right here it’s simply vital to needless to say our delta desk DimCustomer consists of a number of parquet recordsdata (on this case two parquet recordsdata), whereas delta_log allows versioning — monitoring of all of the modifications that occurred to DimCustomer desk.

I’ve created an excellent fundamental report to look at how framing works. The report exhibits the title and electronic mail handle of the shopper Aaron Adams:

I’ll now go and alter the e-mail handle within the knowledge supply, from aaron48 to aaron048:

Let’s reload the info into Material lakehouse and verify what occurred to the DimCustomer desk within the background:

A brand new parquet file appeared, whereas on the similar time in delta_log, a brand new model has been created.
As soon as I’m going again to my report and hit the Refresh button…

This occurred as a result of my default setting for semantic mannequin refresh was configured to allow change detection within the delta desk and routinely replace the semantic mannequin:

Now, what would occur if I disable this feature? Let’s verify… I’ll set the e-mail handle again to aaron48 and reload the info within the lakehouse. First, there’s a new model of the file in delta_log, the identical as within the earlier case:

And, if I question the lakehouse through the SQL Analytics Endpoint, you’ll see the newest knowledge included (aaron48):

However, if I’m going to the report and hit Refresh… I nonetheless see aaron048!

Since I disabled the automated propagation of the newest knowledge from the lakehouse (OneLake) to the semantic mannequin, I’ve solely two choices out there to maintain my semantic mannequin (and, consequentially, my report) intact:
- Allow the “Hold your Direct Lake knowledge updated” choice once more
- Manually refresh the semantic mannequin. After I say manually, it may be actually manually, by clicking on the Refresh now button, or by executing refresh programmatically (i.e. utilizing Material notebooks, or REST APIs) as a part of the orchestration pipeline
Why would you need to hold this feature disabled (like I did within the newest instance)? Effectively, your semantic mannequin normally consists of a number of tables, representing the serving layer for the tip consumer. And, you don’t essentially need to have knowledge within the report up to date in sequence (desk by desk), however most likely after all the semantic mannequin is refreshed and synced with the supply knowledge.
This strategy of holding the semantic mannequin in sync with the newest model of the delta desk is known as framing.

Within the illustration above, you see recordsdata at present “framed” within the context of the semantic mannequin. As soon as the brand new file enters the lakehouse (OneLake), here’s what ought to occur with a view to have the newest file included within the semantic mannequin.
The semantic mannequin have to be “reframed” to incorporate the newest knowledge. This course of has a number of implications that you need to be conscious of. First, and most vital, each time framing happens, all the info at present saved within the reminiscence (we’re speaking about cache reminiscence) is dumped out of the cache. That is of paramount significance for the subsequent idea that we’re going to talk about — transcoding.
Subsequent, there isn’t a “actual” knowledge refresh occurring with framing…
In contrast to with Import mode, the place kicking off the refresh course of will actually put the snapshot of the bodily knowledge within the semantic mannequin, framing refreshes metadata solely! So, knowledge stays within the delta desk in OneLake (no knowledge is loaded within the Direct Lake semantic mannequin), we’re solely telling our semantic mannequin: hey, there’s a new file down there, go and take it from right here when you want the info for the report… This is among the key variations between the Direct Lake and Import mode
For the reason that Direct Lake “refresh” is only a metadata refresh, it’s normally a low-intensive operation that shouldn’t devour an excessive amount of time and assets. Even in case you have a billion-row desk, don’t neglect — you aren’t refreshing a billion rows in your semantic mannequin — you refresh solely the data about that big desk…
Transcoding — Your on-demand cache magic
Effective, now that you understand how to sync knowledge from a lakehouse along with your semantic mannequin (syncing), and tips on how to embrace the newest “knowledge about knowledge” within the semantic mannequin (framing), it’s time to grasp what actually occurs behind the scenes as soon as you place your semantic mannequin into motion!
That is the promoting level of Direct Lake, proper? Efficiency of the Import mode, however with out copying the info. So, let’s look at the idea of Transcoding…
In plain English: transcoding represents a strategy of loading components of the delta desk (after I say components, I imply sure columns) or all the delta desk into cache reminiscence!
Let me cease right here and put the sentence above within the context of Import mode:
- Loading knowledge into reminiscence (cache) is one thing that ensures a blazing-fast efficiency of the Import mode
- In Import mode, in case you haven’t enabled a Massive Format Semantic Mannequin function, all the semantic mannequin is saved in reminiscence (it should match reminiscence limits), whereas in Direct Lake mode, solely columns wanted by the queries are saved in reminiscence!
To place it merely: bullet level one implies that as soon as Direct Lake columns are loaded into reminiscence, that is completely the identical as Import mode (the one potential distinction would be the approach knowledge is sorted by VertiPaq vs the way it’s sorted within the delta desk)! Bullet level two implies that the cache reminiscence footprint of the Direct Lake semantic mannequin may very well be considerably decrease, or within the worst case, the identical, as that of the Import mode (I promise to point out you quickly). Clearly, this decrease reminiscence footprint comes with a worth, and that’s the ready time for the primary load of the visible containing knowledge that must be “transcoded” on-demand from OneLake to the semantic mannequin.
Earlier than we dive into examples, you may be questioning: how does this factor work? How can it’s that knowledge saved within the delta desk might be learn by the Energy BI engine the identical approach because it was saved in Import mode?
The reply is: there’s a course of referred to as transcoding, which occurs on the fly when a Energy BI question requests the info. This isn’t too costly a course of, for the reason that knowledge in Parquet recordsdata is saved very equally to the way in which VertiPaq (a columnar database behind Energy BI and AAS) shops the info. On high of it, in case your knowledge is written to delta tables utilizing the v-ordering algorithm (Microsoft’s proprietary algorithm for reshuffling and sorting the info to realize higher learn efficiency), transcoding makes the info from delta tables look precisely the identical as if it have been saved within the proprietary format of AAS.
Let me now present you ways paging works in actuality. For this instance, I’ll be utilizing a healthcare dataset supplied by Greg Beaumont (MIT license. Go and go to Greg’s GitHub, it’s full of wonderful assets). The actual fact desk incorporates ca. 220 million rows, and my semantic mannequin is a well-designed star schema.
Import vs Direct Lake
The thought is the next: I’ve two an identical semantic fashions (similar knowledge, similar tables, similar relationships, and so forth.) — one is in Import mode, whereas the opposite is in Direct Lake.

I’ll now open a Energy BI Desktop and join to every of those semantic fashions to create an an identical report on high of them. I would like the Efficiency Analyzer software within the Energy BI Desktop, to seize the queries and analyze them later in DAX Studio.
I’ve created a really fundamental report web page, with just one desk visible, which exhibits the whole variety of information per 12 months. In each reviews, I’m ranging from a clean web page, as I need to be sure that nothing is retrieved from the cache, so let’s evaluate the primary run of every visible:

As you might discover, the Import mode performs barely higher in the course of the first run, most likely due to the transcoding price overhead for “paging” the info for the primary time in Direct Lake mode. I’ll now create a 12 months slicer in each reviews, swap between completely different years, and evaluate efficiency once more:

There’s principally no distinction in efficiency (numbers have been moreover examined utilizing the Benchmark function in DAX Studio)! This implies, as soon as the column from the Direct Lake semantic mannequin is paged into reminiscence, it behaves precisely the identical as within the Import mode.
Nonetheless, what occurs if we embrace the extra column within the scope? Let’s check the efficiency of each reviews as soon as I put the Whole Drug Value measure within the desk visible:

And, it is a state of affairs the place Import simply outperforms Direct Lake! Don’t neglect, in Import mode, all the semantic mannequin was loaded into reminiscence, whereas in Direct Lake, solely columns wanted by the question have been loaded in reminiscence. On this instance, since Whole Drug Value wasn’t a part of the unique question, it wasn’t loaded into reminiscence. As soon as the consumer included it within the report, Energy BI needed to spend a while to transcode this knowledge on the fly from OneLake to VertiPaq and web page it within the reminiscence.
Reminiscence footprint
Okay, we additionally talked about that the reminiscence footprint of the Import vs Direct Lake semantic fashions might fluctuate considerably. Let me shortly present you what I’m speaking about. I’ll first verify the Import mode semantic mannequin particulars, utilizing VertiPaq Analyzer in DAX Studio:

As you might even see, the dimensions of the semantic mannequin is sort of 4.3 GB! And, taking a look at the costliest columns…

“Tot_Drug_Cost” and “65 or Older Whole” columns take nearly 2 GB of all the mannequin! So, in idea, even when nobody ever makes use of these columns within the report, they are going to nonetheless take their justifiable share of RAM (until you allow a Massive Semantic Mannequin choice).
I’ll now analyze the DIrect Lake semantic mannequin utilizing the identical strategy:

Oh, wow, it’s 4x much less reminiscence footprint! Let’s shortly verify the costliest columns within the mannequin…

Let’s briefly cease right here and look at the outcomes displayed within the illustration above. The “Tot_Drug_Cst” column takes virtually all the reminiscence of this semantic mannequin — since we used it in our desk visible, it was paged into reminiscence. However, have a look at all the opposite columns, together with the “65 or Older Whole” that beforehand consumed 650 MBs in Import mode! It’s now 2.4 KBs! It’s only a metadata! So long as we don’t use this column within the report, it is not going to devour any RAM.
This suggests, if we’re speaking about reminiscence limits in Direct Lake, we’re referring to a max reminiscence restrict per question! Provided that the question exceeds the reminiscence restrict of your Material capability SKU, it can fall again to Direct Question (in fact, assuming that your configuration follows the default fallback conduct setup):

This can be a key distinction between the Import and DIrect Lake modes. Going again to our earlier instance, my Direct Lake report would work simply high-quality with the bottom F SKU (F2).
“You’re scorching then you definitely’re chilly… You’re in then you definitely’re out…”
There’s a well-known tune by Katy Perry “Scorching N Chilly”, the place the chorus says: “You’re scorching then you definitely’re chilly… You’re in then you definitely’re out…” This completely summarizes how columns are being handled in Direct Lake mode! The final idea that I need to introduce to you is the column “temperature”.
This idea is of paramount significance when working with Direct Lake mode, as a result of based mostly on the column temperature, the engine decides which column(s) keep in reminiscence and that are kicked out again to OneLake.
The extra the column is queried, the upper its temperature is! The upper the temperature of the column, the larger chances are high that it stays in reminiscence.
Marc Lelijveld already wrote a nice article on the subject, so I received’t repeat all the small print that Marc completely defined. Right here, I simply need to present you tips on how to verify the temperature of particular columns of your Direct Lake semantic mannequin, and share some ideas and methods on tips on how to hold the “fireplace” burning:)
SELECT DIMENSION_NAME
, COLUMN_ID
, DICTIONARY_SIZE
, DICTIONARY_TEMPERATURE
, DICTIONARY_LAST_ACCESSED
FROM $SYSTEM.DISCOVER_STORAGE_TABLE_COLUMNS
ORDER BY DICTIONARY_TEMPERATURE DESCThe above question towards the DMV Discover_Storage_Table_Columns may give you a fast trace of how the idea of “Scorching N Chilly” works in Direct Lake:

As you might discover, the engine retains relationship columns’ dictionaries “heat”, due to the filter propagation. There are additionally columns that we utilized in our desk visible: Yr, Tot Drug Cst and Tot Clms. If I don’t do something with my report, the temperature will slowly lower over time. However, let’s carry out some actions inside the report and verify the temperature once more:

I’ve added the Whole Claims measure (based mostly on the Tot Clms column) and altered the 12 months on the slicer. Let’s check out the temperature now:

Oh, wow, these three columns have a temperature 10x increased than the columns not used within the report. This fashion, the engine ensures that probably the most incessantly used columns will keep in cache reminiscence, in order that the report efficiency would be the very best for the tip consumer.
Now, the truthful query could be: what occurs as soon as all my finish customers go residence at 5 PM, and nobody touches Direct Lake semantic fashions till the subsequent morning?
Effectively, the primary consumer should “sacrifice” for all of the others and wait just a little bit longer for the primary run, after which everybody can profit from having “heat” columns prepared within the cache. However, what if the primary consumer is your supervisor or a CEO?! No bueno:)
I’ve excellent news — there’s a trick to pre-warm the cache, by loading probably the most incessantly used columns upfront, as quickly as your knowledge is refreshed in OneLake. My pal Sandeep Pawar wrote a step-by-step tutorial on tips on how to do it (Semantic Hyperlink to the rescue), and it is best to undoubtedly contemplate implementing this system if you wish to keep away from a foul expertise for the primary consumer.
Conclusion
Direct Lake is known as a groundbreaking function launched with Microsoft Material. Nonetheless, since it is a brand-new resolution, it depends on an entire new world of ideas. On this article, we coated a few of them that I contemplate a very powerful.
To wrap up, since I’m a visible particular person, I ready an illustration of all of the ideas we coated:

Thanks for studying!



{kind=link}