Every single day, enterprises course of hundreds of paperwork containing important enterprise data. From invoices and buy orders to types and contracts, precisely finding and extracting particular fields has historically been one of the vital advanced challenges in doc processing pipelines. Though optical character recognition (OCR) can inform us what textual content exists in a doc, figuring out the place particular data is situated has required subtle pc imaginative and prescient options.
The evolution of this subject illustrates the complexity of the problem. Early object detection approaches like YOLO (You Solely Look As soon as) revolutionized the sector by reformulating object detection as a regression downside, enabling real-time detection. RetinaNet superior this additional by addressing class imbalance points via Focal Loss, and DETR launched transformer-based architectures to reduce hand-designed parts. Nevertheless, these approaches shared widespread limitations: they required intensive coaching knowledge, advanced mannequin architectures, and vital experience to implement and preserve.
The emergence of multimodal massive language fashions (LLMs) represents a paradigm shift in doc processing. These fashions mix superior imaginative and prescient understanding with pure language processing capabilities, providing a number of groundbreaking benefits:
- Minimized use of specialised pc imaginative and prescient architectures
- Zero-shot capabilities with out the necessity for supervised studying
- Pure language interfaces for specifying location duties
- Versatile adaptation to completely different doc sorts
This submit demonstrates use basis fashions (FMs) in Amazon Bedrock, particularly Amazon Nova Professional, to attain high-accuracy doc subject localization whereas dramatically simplifying implementation. We present how these fashions can exactly find and interpret doc fields with minimal frontend effort, decreasing processing errors and handbook intervention. By means of complete benchmarking on the FATURA dataset, we offer benchmarking of efficiency and sensible implementation steerage.
Understanding doc data localization
Doc data localization goes past conventional textual content extraction by figuring out the exact spatial place of knowledge inside paperwork. Though OCR tells us what textual content exists, localization tells us the place particular data resides—an important distinction for contemporary doc processing workflows. This functionality permits important enterprise operations starting from automated high quality checks and delicate knowledge redaction to clever doc comparability and validation.
Conventional approaches to this problem relied on a mixture of rule-based methods and specialised pc imaginative and prescient fashions. These options typically required intensive coaching knowledge, cautious template matching, and steady upkeep to deal with doc variations. Monetary establishments, for example, would wish separate fashions and guidelines for every sort of bill or kind they processed, making scalability a major problem. Multimodal fashions with localization capabilities obtainable on Amazon Bedrock essentially change this paradigm. Reasonably than requiring advanced pc imaginative and prescient architectures or intensive coaching knowledge, these multimodal LLMs can perceive each the visible structure and semantic that means of paperwork via pure language interactions. By utilizing fashions with the potential to localize, organizations can implement sturdy doc localization with considerably lowered technical overhead and larger adaptability to new doc sorts.
Multimodal fashions with localization capabilities, equivalent to these obtainable on Amazon Bedrock, essentially change this paradigm. Reasonably than requiring advanced pc imaginative and prescient architectures or intensive coaching knowledge, these multimodal LLMs can perceive each the visible structure and semantic that means of paperwork via pure language interactions. By utilizing fashions with the potential to localize, organizations can implement sturdy doc localization with considerably lowered technical overhead and larger adaptability to new doc sorts.
Resolution overview
We designed a easy localization resolution that takes a doc picture and textual content immediate as enter, processes it via chosen FMs on Amazon Bedrock, and returns the sector areas utilizing both absolute or normalized coordinates. The answer implements two distinct prompting methods for doc subject localization:
- Picture dimension technique – Works with absolute pixel coordinates, offering express picture dimensions and requesting bounding field areas primarily based on the doc’s precise dimension
- Scaled coordinate technique – Makes use of a normalized 0–1000 coordinate system, making it extra versatile throughout completely different doc sizes and codecs
The answer has a modular design to permit for simple extension to assist customized subject schemas via configuration updates relatively than code modifications. This flexibility, mixed with the scalability of Amazon Bedrock, makes the answer appropriate for each small-scale doc processing and enterprise-wide deployment. Within the following sections, we exhibit the setup and implementation methods utilized in our resolution for doc subject localization utilizing Amazon Bedrock FMs. You may see extra particulars in our GitHub repository.
Stipulations
For this walkthrough, you must have the next stipulations:
- An AWS account with Amazon Bedrock entry
- Permissions to make use of Amazon Nova Professional
- Python 3.8+ with the boto3 library put in
Preliminary set ups
Full the next setup steps:
- Configure the Amazon Bedrock runtime consumer with acceptable retry logic and timeout settings:
import boto3
from botocore.config import Config
# Configure Bedrock consumer with retry logic
BEDROCK_CONFIG = Config(
region_name="us-west-2",
signature_version='v4',
read_timeout=500,
retries={
'max_attempts': 10,
'mode': 'adaptive'
}
)
# Initialize Bedrock runtime consumer
bedrock_runtime = boto3.consumer("bedrock-runtime", config=BEDROCK_CONFIG)- Outline your subject configuration to specify which parts to find in your paperwork:
# pattern config
field_config = {
"invoice_number": {"sort": "string", "required": True},
"total_amount": {"sort": "forex", "required": True},
"date": {"sort": "date", "required": True}
}- Initialize the
BoundingBoxExtractoralong with your chosen mannequin and technique:
extractor = BoundingBoxExtractor(
model_id=NOVA_PRO_MODEL_ID, # or different FMs on Amazon Bedrock
prompt_template_path="path/to/immediate/template",
field_config=field_config,
norm=None # Set to 1000 for scaled coordinate technique
)
# Course of a doc
bboxes, metadata = extractor.get_bboxes(
document_image=document_image,
document_key="invoice_001" # Elective monitoring key
)Implement prompting methods
We check two immediate methods on this workflow: picture dimension and scaled coordinate.
The next is a pattern immediate template for the picture dimension technique:
"""
Your activity is to detect and localize objects in photos with excessive precision.
Analyze every offered picture (width = {w} pixels, top = {h} pixels) and return solely a JSON object with bounding field knowledge for detected objects.
Output Necessities:
1. Use absolute pixel coordinates primarily based on offered width and top.
2. Guarantee excessive accuracy and tight-fitting bounding containers.
Detected Object Construction:
- "component": Use one in all these labels precisely: {parts}
- "bbox": Array with coordinates [x1, y1, x2, y2] in absolute pixel values.
JSON Construction:
```json
{schema}
```
Present solely the required JSON format with out additional data.
"""The next is a pattern immediate template for the scaled coordinate technique:
"""
Your activity is to detect and localize objects in photos with excessive precision.
Analyze every offered picture and return solely a JSON object with bounding field knowledge for detected objects.
Output Necessities:
Use (x1, y1, x2, y2) format for bounding field coordinates, scaled between 0 and 1000.
Detected Object Construction:
- "component": Use one in all these labels precisely: {parts}
- "bbox": Array [x1, y1, x2, y2] scaled between 0 and 1000.
JSON Construction:
```json
{schema}
```
Present solely the required JSON format with out additional data.
"""Consider efficiency
We implement analysis metrics to observe accuracy:
evaluator = BBoxEvaluator(field_config=field_config)
evaluator.set_iou_threshold(0.5) # Alter primarily based on necessities
evaluator.set_margin_percent(5) # Tolerance for place matching
# Consider predictions
outcomes = evaluator.consider(predictions, ground_truth)
print(f"Imply Common Precision: {outcomes['mean_ap']:.4f}")This implementation gives a strong basis for doc subject localization whereas sustaining flexibility for various use circumstances and doc sorts. The selection between picture dimension and scaled coordinate methods will depend on your particular accuracy necessities and doc variation.
Benchmarking outcomes
We carried out our benchmarking examine utilizing FATURA, a public bill dataset particularly designed for doc understanding duties. The dataset includes 10,000 single-page invoices saved as JPEG photos, representing 50 distinct structure templates with 200 invoices per template. Every doc is annotated with 24 key fields, together with bill numbers, dates, line gadgets, and complete quantities. The annotations present each the textual content values and exact bounding field coordinates in JSON format, making it splendid for evaluating subject localization duties. The dataset has the next key traits:
- Paperwork: 10,000 invoices (JPEG format)
- Templates: 50 distinct layouts (200 paperwork every)
- Fields per doc: 24 annotated fields
- Annotation format: JSON with bounding containers and textual content values
- Area sorts: Bill numbers, dates, addresses, line gadgets, quantities, taxes, totals
- Picture decision: Customary A4 dimension at 300 DPI
- Language: English
The next determine exhibits pattern bill templates showcasing structure variation.
The next determine is an instance of annotation visualization.


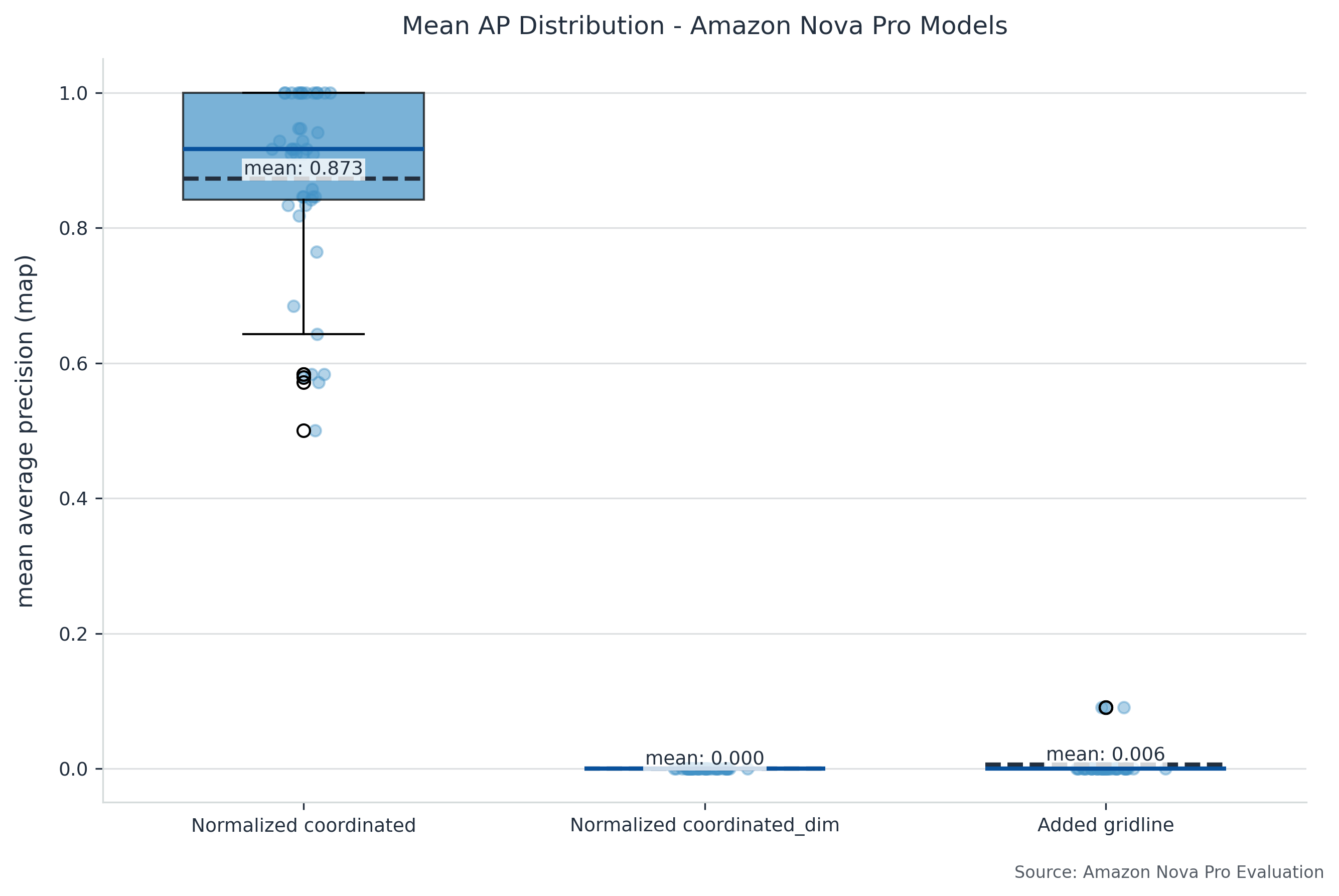
Earlier than conducting the full-scale benchmark, we carried out an preliminary experiment to find out the optimum prompting technique. We chosen a consultant subset of fifty photos, comprising 5 samples from 10 completely different templates, and evaluated three distinct approaches:
- Picture dimension:
- Technique: Gives express pixel dimensions and requests absolute coordinate bounding containers
- Enter: Picture bytes, picture dimensions, output schema
- Scaled coordinate:
- Technique: Makes use of normalized 0-1000 coordinate system
- Enter: Picture bytes, output schema
- Added gridlines:
- Technique: Enhances picture with visible gridlines at fastened intervals
- Enter: Modified picture with gridlines bytes, picture dimensions, output schema
The next determine compares efficiency for various approaches for Imply Common Precision (mAP).
Constructing on insights from our preliminary technique analysis, we carried out benchmarking utilizing the entire FATURA dataset of 10,000 paperwork. We employed the scaled coordinate strategy for Amazon Nova fashions, primarily based on their respective optimum efficiency traits from our preliminary testing. Our analysis framework assessed Amazon Nova Professional via normal metrics, together with Intersection over Union (IoU) and Common Precision (AP). The analysis spanned all 50 distinct bill templates, utilizing an IoU threshold of 0.5 and a 5% margin tolerance for subject positioning.
The next are our pattern leads to JSON:
{
"template": "template1",
"occasion": "Instance0",
"metrics": {
"mean_ap": 0.8421052631578947,
"field_scores": {
"TABLE": [0.9771107575829314, 1.0, 1.0, 1.0, 1.0],
"BUYER": [0.3842328422050217, 0.0, 0.0, 0, 0.0],
"DATE": [0.9415158516000428, 1.0, 1.0, 1.0, 1.0],
"DISCOUNT": [0.8773709977744115, 1.0, 1.0, 1.0, 1.0],
"DUE_DATE": [0.9338410331219548, 1.0, 1.0, 1.0, 1.0],
"GSTIN_BUYER": [0.8868145680064249, 1.0, 1.0, 1.0, 1.0],
"NOTE": [0.7926162009357707, 1.0, 1.0, 1.0, 1.0],
"PAYMENT_DETAILS": [0.9517931284002012, 1.0, 1.0, 1.0, 1.0],
"PO_NUMBER": [0.8454266053075804, 1.0, 1.0, 1.0, 1.0],
"SELLER_ADDRESS": [0.9687004508445741, 1.0, 1.0, 1.0, 1.0],
"SELLER_EMAIL": [0.8771026147909002, 1.0, 1.0, 1.0, 1.0],
"SELLER_SITE": [0.8715647216012751, 1.0, 1.0, 1.0, 1.0],
"SUB_TOTAL": [0.8049954543667662, 1.0, 1.0, 1.0, 1.0],
"TAX": [0.8751563641702513, 1.0, 1.0, 1.0, 1.0],
"TITLE": [0.850667327423512, 1.0, 1.0, 1.0, 1.0],
"TOTAL": [0.7226784112051814, 1.0, 1.0, 1.0, 1.0],
"TOTAL_WORDS": [0.9099353099528785, 1.0, 1.0, 1.0, 1.0],
"GSTIN_SELLER": [0.87170328009624, 1.0, 1.0, 1.0, 1.0],
"LOGO": [0.679425211111111, 1.0, 1.0, 1.0, 1.0]
}
},
"metadata": {
"utilization": {
"inputTokens": 2250,
"outputTokens": 639,
"totalTokens": 2889
},
"metrics": {
"latencyMs": 17535
}
}
}The next determine is an instance of profitable localization for Amazon Nova Professional.

The outcomes exhibit Amazon Nova Professional’s sturdy efficiency in doc subject localization. Amazon Nova Professional achieved a mAP of 0.8305. It demonstrated constant efficiency throughout varied doc layouts, reaching a mAP above 0.80 throughout 45 of fifty templates, with the bottom template-specific mAP being 0.665. Though Amazon Nova Professional confirmed comparatively excessive processing failures (170 out of 10,000 photos), it nonetheless maintained excessive general efficiency. Most low AP outcomes have been attributed to both full processing failures (notably over-refusal by its guardrail filters and malformed JSON output) or subject misclassifications (notably confusion between related fields, equivalent to purchaser vs. vendor addresses).
The next desk summarizes the general efficiency metrics.
| Imply IoU | Imply AP | |
| Amazon Nova Professional | 0.7423 | 0.8331 |
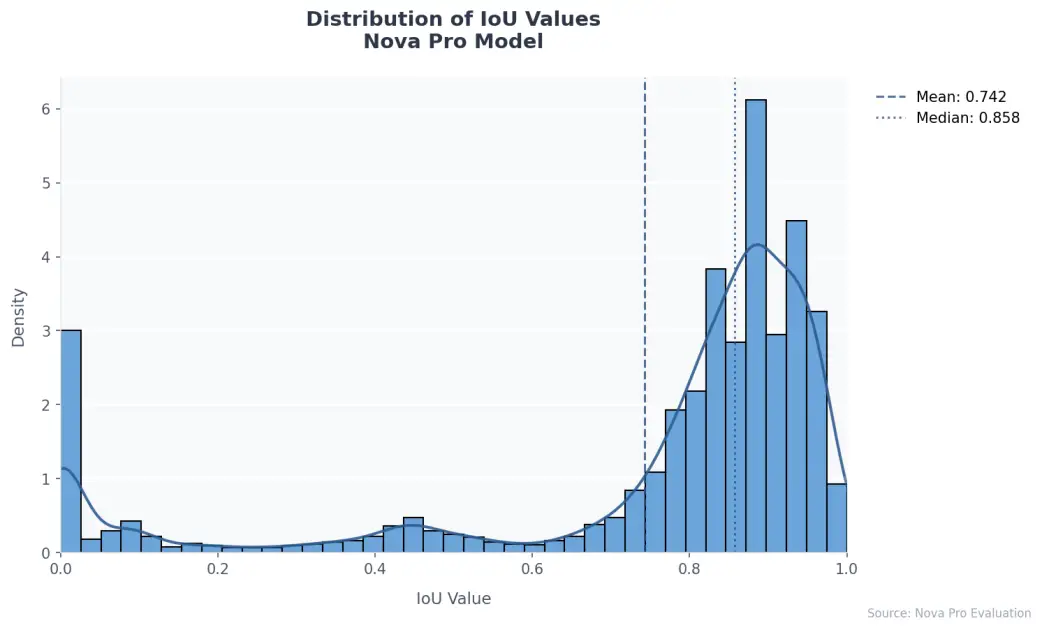
The next graph exhibits the efficiency distribution for every particular person extraction of roughly 20 labels for 10,000 paperwork.
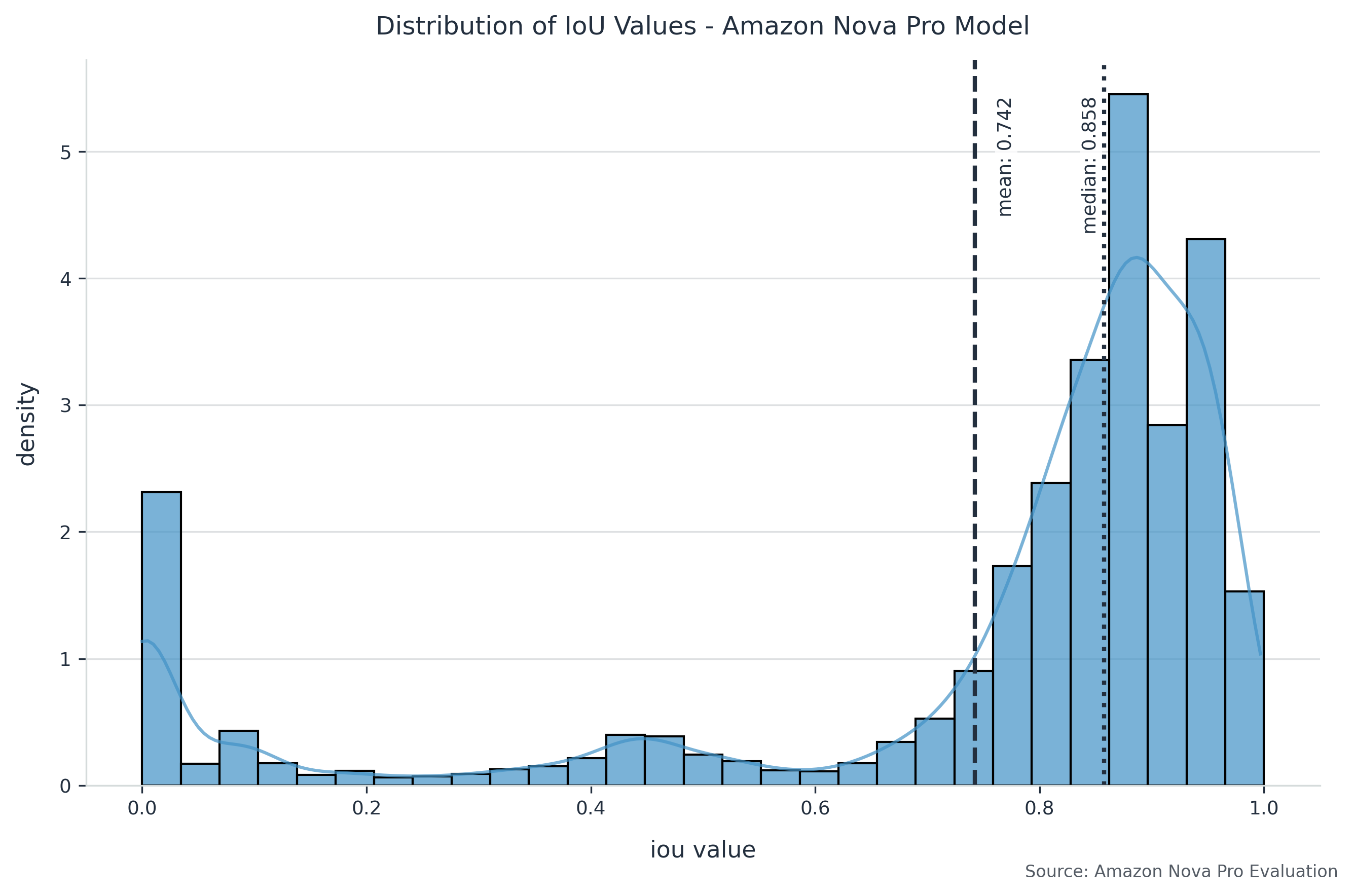
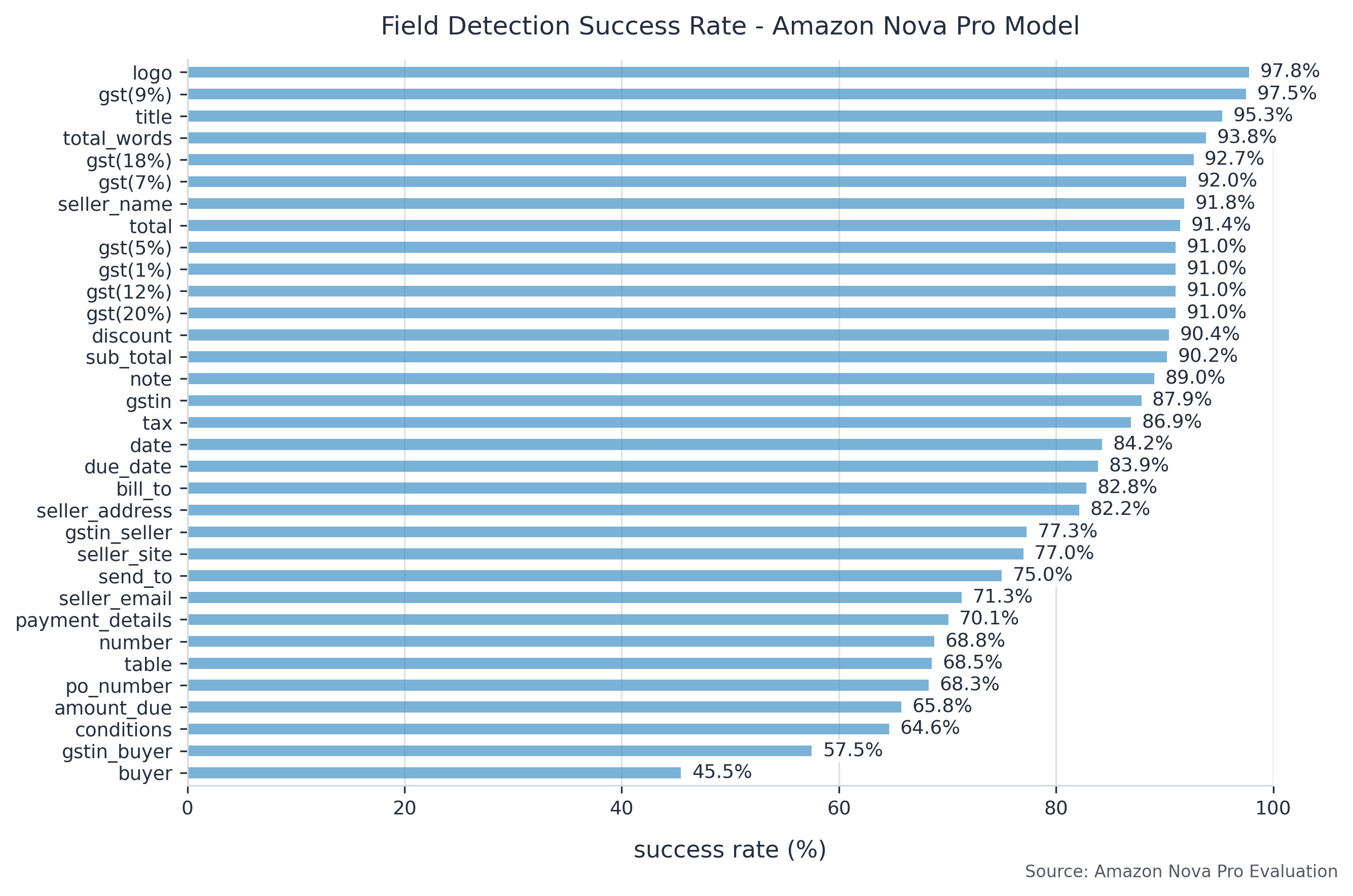
Area-specific evaluation reveals that Amazon Nova Professional excels at finding structured fields like bill numbers and dates, constantly reaching precision and recall scores above 0.85. It demonstrates notably sturdy efficiency with textual content fields, sustaining sturdy accuracy even when coping with various forex codecs and decimal representations. This resilience to format variations makes it particularly priceless for processing paperwork from a number of sources or areas.
The next graph summarizes field-specific efficiency. The graph exhibits AP success share for every label, throughout all paperwork for every mannequin. It’s sorted by highest success.
Conclusion
This benchmarking examine demonstrates the numerous advances in doc subject localization by multimodal FMs. By means of complete testing on the FATURA dataset, we’ve proven that these fashions can successfully find and extract doc fields with minimal setup effort, dramatically simplifying conventional pc imaginative and prescient workflows. Amazon Nova Professional emerges as a wonderful alternative for enterprise doc processing, delivering a mAP of 0.8305 with constant efficiency throughout numerous doc sorts. Wanting forward, we see a number of promising instructions for additional optimization. Future work may discover extending the answer in agentic workflows to assist extra advanced doc sorts and subject relationships.
To get began with your individual implementation, you’ll find the entire resolution code in our GitHub repository. We additionally advocate reviewing the Amazon Bedrock documentation for the most recent mannequin capabilities and finest practices.
In regards to the authors
 Ryan Razkenari is a Deep Studying Architect on the AWS Generative AI Innovation Heart, the place he makes use of his experience to create cutting-edge AI options. With a powerful background in AI and analytics, he’s keen about constructing progressive applied sciences that tackle real-world challenges for AWS clients.
Ryan Razkenari is a Deep Studying Architect on the AWS Generative AI Innovation Heart, the place he makes use of his experience to create cutting-edge AI options. With a powerful background in AI and analytics, he’s keen about constructing progressive applied sciences that tackle real-world challenges for AWS clients.
 Harpreet Cheema is a Deep Studying Architect on the AWS Generative AI Innovation Heart. He’s very passionate within the subject of machine studying and in tackling completely different issues within the ML area. In his position, he focuses on growing and delivering Generative AI centered options for real-world purposes.
Harpreet Cheema is a Deep Studying Architect on the AWS Generative AI Innovation Heart. He’s very passionate within the subject of machine studying and in tackling completely different issues within the ML area. In his position, he focuses on growing and delivering Generative AI centered options for real-world purposes.
 Spencer Romo is a Senior Knowledge Scientist with intensive expertise in deep studying purposes. He makes a speciality of clever doc processing whereas sustaining broad experience in pc imaginative and prescient, pure language processing, and sign processing. Spencer’s progressive work in distant sensing has resulted in a number of patents. Primarily based in Austin, Texas, Spencer loves working straight with clients to grasp their distinctive issues and establish impactful AI options. Exterior of labor, Spencer competes in 24 Hours of Lemons racing collection, embracing the problem of high-performance driving on a finances.
Spencer Romo is a Senior Knowledge Scientist with intensive expertise in deep studying purposes. He makes a speciality of clever doc processing whereas sustaining broad experience in pc imaginative and prescient, pure language processing, and sign processing. Spencer’s progressive work in distant sensing has resulted in a number of patents. Primarily based in Austin, Texas, Spencer loves working straight with clients to grasp their distinctive issues and establish impactful AI options. Exterior of labor, Spencer competes in 24 Hours of Lemons racing collection, embracing the problem of high-performance driving on a finances.
 Mun Kim is a Machine Studying Engineer on the AWS Generative AI Innovation Heart. Mun brings experience in constructing machine studying science and platform that assist clients harness the ability of generative AI applied sciences. He works intently with AWS clients to speed up their AI adoption journey and unlock new enterprise worth.
Mun Kim is a Machine Studying Engineer on the AWS Generative AI Innovation Heart. Mun brings experience in constructing machine studying science and platform that assist clients harness the ability of generative AI applied sciences. He works intently with AWS clients to speed up their AI adoption journey and unlock new enterprise worth.
 Wan Chen is an Utilized Science Supervisor on the Generative AI Innovation Heart. As a ML/AI veteran in tech business, she has wide selection of experience on conventional machine studying, recommender system, deep studying and Generative AI. She is a stronger believer of Superintelligence, and could be very passionate to push the boundary of AI analysis and utility to boost human life and drive enterprise development. She holds Ph.D in Utilized Arithmetic from College of British Columbia, and had labored as postdoctoral fellow in Oxford College.
Wan Chen is an Utilized Science Supervisor on the Generative AI Innovation Heart. As a ML/AI veteran in tech business, she has wide selection of experience on conventional machine studying, recommender system, deep studying and Generative AI. She is a stronger believer of Superintelligence, and could be very passionate to push the boundary of AI analysis and utility to boost human life and drive enterprise development. She holds Ph.D in Utilized Arithmetic from College of British Columbia, and had labored as postdoctoral fellow in Oxford College.



{kind=link}