Generative synthetic intelligence (AI) not solely empowers innovation by means of ideation, content material creation, and enhanced customer support, but in addition streamlines operations and boosts productiveness throughout varied domains. To successfully harness this transformative know-how, Amazon Bedrock gives a completely managed service that integrates high-performing basis fashions (FMs) from main AI firms, corresponding to AI21 Labs, Anthropic, Cohere, Meta, Stability AI, Mistral AI, and Amazon. By offering entry to those superior fashions by means of a single API and supporting the event of generative AI functions with an emphasis on safety, privateness, and accountable AI, Amazon Bedrock lets you use AI to discover new avenues for innovation and enhance general choices.
Enterprise clients can unlock vital worth by harnessing the ability of clever doc processing (IDP) augmented with generative AI. By infusing IDP options with generative AI capabilities, organizations can revolutionize their doc processing workflows, attaining distinctive ranges of automation and reliability. This mixture permits superior doc understanding, extremely efficient structured knowledge extraction, automated doc classification, and seamless info retrieval from unstructured textual content. With these capabilities, organizations can obtain scalable, environment friendly, and high-value doc processing that drives enterprise transformation and competitiveness, finally resulting in improved productiveness, diminished prices, and enhanced decision-making.
On this put up, we present methods to develop an IDP answer utilizing Anthropic Claude 3 Sonnet on Amazon Bedrock. We reveal methods to extract knowledge from a scanned doc and insert it right into a database.
The Anthropic Claude 3 Sonnet mannequin is optimized for pace and effectivity, making it a wonderful selection for clever duties—notably for enterprise workloads. It additionally possesses refined imaginative and prescient capabilities, demonstrating a robust aptitude for understanding a variety of visible codecs, together with pictures, charts, graphs, and technical diagrams. Though we reveal this answer utilizing the Anthropic Claude 3 Sonnet mannequin, you possibly can alternatively use the Haiku and Opus fashions in case your use case requires them.
Resolution overview
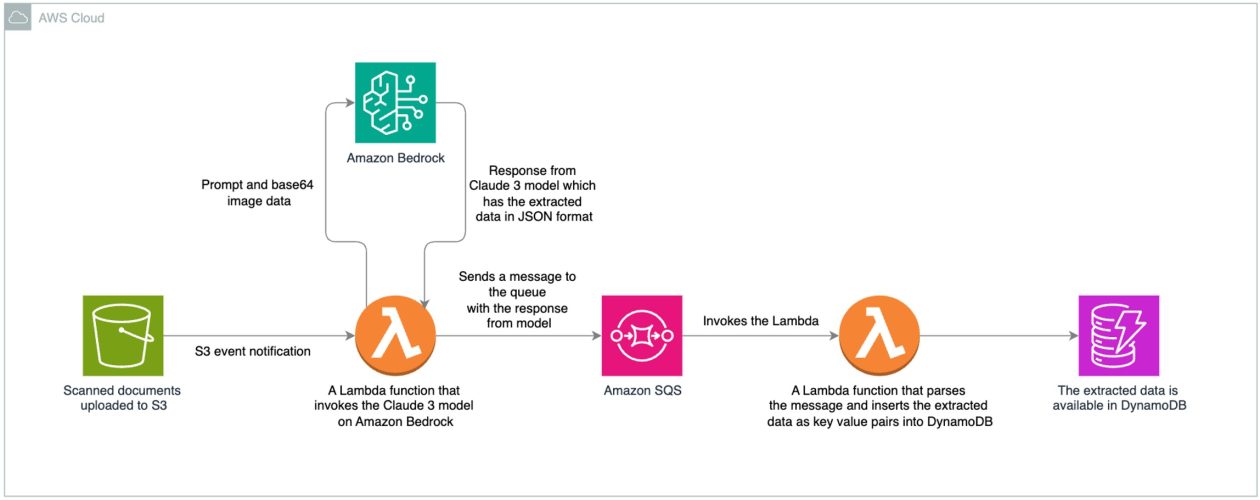
The proposed answer makes use of Amazon Bedrock and the highly effective Anthropic Claude 3 Sonnet mannequin to allow IDP capabilities. The structure consists of a number of AWS providers seamlessly built-in with the Amazon Bedrock, enabling environment friendly and correct extraction of information from scanned paperwork.
The next diagram illustrates our answer structure.

The answer consists of the next steps:
- The method begins with scanned paperwork being uploaded and saved in an Amazon Easy Storage Service (Amazon S3) bucket, which invokes an S3 Occasion Notification on object add.
- This occasion invokes an AWS Lambda operate, accountable for invoking the Anthropic Claude 3 Sonnet mannequin on Amazon Bedrock.
- The Anthropic Claude 3 Sonnet mannequin, with its superior multimodal capabilities, processes the scanned paperwork and extracts related knowledge in a structured JSON format.
- The extracted knowledge from the Anthropic Claude 3 mannequin is shipped to an Amazon Easy Queue Service (Amazon SQS) queue. Amazon SQS acts as a buffer, permitting elements to ship and obtain messages reliably with out being instantly coupled, offering scalability and fault tolerance within the system.
- One other Lambda operate consumes the messages from the SQS queue, parses the JSON knowledge, and shops the extracted key-value pairs in an Amazon DynamoDB desk for retrieval and additional processing.
This serverless structure takes benefit of the scalability and cost-effectiveness of AWS providers whereas harnessing the cutting-edge intelligence of Anthropic Claude 3 Sonnet. By combining the sturdy infrastructure of AWS with Anthropic’s FMs, this answer permits organizations to streamline their doc processing workflows, extract invaluable insights, and improve general operational effectivity.
The answer makes use of the next providers and options:
- Amazon Bedrock is a completely managed service that gives entry to massive language fashions (LLMs), permitting builders to construct and deploy their very own personalized AI functions.
- The Anthropic Claude 3 household gives a flexible vary of fashions tailor-made to fulfill numerous wants. With three choices—Opus, Sonnet, and Haiku—you possibly can select the right stability of intelligence, pace, and price. These fashions excel at understanding complicated enterprise content material, together with charts, graphs, technical diagrams, and stories.
- Amazon DynamoDB is a completely managed, serverless, NoSQL database service.
- AWS Lambda is a serverless computing service that permits you to run code with out provisioning or managing servers.
- Amazon SQS is a completely managed message queuing service.
- Amazon S3 is a extremely scalable, sturdy, and safe object storage service.
On this answer, we use the generative AI capabilities in Amazon Bedrock to effectively extract knowledge. As of writing of this put up, Anthropic Claude 3 Sonnet solely accepts photos as enter. The supported file sorts are GIF, JPEG, PNG, and WebP. You may select to avoid wasting photos in the course of the scanning course of or convert the PDF to pictures.
It’s also possible to improve this answer by implementing human-in-the-loop and mannequin analysis options. The purpose of this put up is to reveal how one can construct an IDP answer utilizing Amazon Bedrock, however to make use of this as a production-scale answer, further concerns ought to be taken under consideration, corresponding to testing for edge case situations, higher exception dealing with, making an attempt further prompting strategies, mannequin fine-tuning, mannequin analysis, throughput necessities, variety of concurrent requests to be supported, and thoroughly contemplating value and latency implications.
Stipulations
You want the next conditions earlier than you possibly can proceed with this answer. For this put up, we use the us-east-1 AWS Area. For particulars on obtainable Areas, see Amazon Bedrock endpoints and quotas.
Use case and dataset
For our instance use case, let’s take a look at a state company accountable for issuing start certificates. The company could obtain start certificates functions by means of varied strategies, corresponding to on-line functions, varieties accomplished at a bodily location, and mailed-in accomplished paper functions. At the moment, most companies spend a substantial period of time and sources to manually extract the applying particulars. The method begins with scanning the applying varieties, manually extracting the main points, after which coming into them into an software that ultimately shops the info right into a database. This course of is time-consuming, inefficient, not scalable, and error-prone. Moreover, it provides complexity if the applying type is in a unique language (corresponding to Spanish).
For this demonstration, we use pattern scanned photos of start certificates software varieties. These varieties don’t include any actual private knowledge. Two examples are offered: one in English (handwritten) and one other in Spanish (printed). Save these photos as .jpeg recordsdata to your pc. You want them later for testing the answer.
Create an S3 bucket
On the Amazon S3 console, create a brand new bucket with a novel title (for instance, bedrock-claude3-idp-{random characters to make it globally distinctive}) and depart the opposite settings as default. Throughout the bucket, create a folder named photos and a sub-folder named birth_certificates.

Create an SQS queue
On the Amazon SQS console, create a queue with the Normal queue sort, present a reputation (for instance, bedrock-idp-extracted-data), and depart the opposite settings as default.

Create a Lambda operate to invoke the Amazon Bedrock mannequin
On the Lambda console, create a operate (for instance, invoke_bedrock_claude3), select Python 3.12 for the runtime, and depart the remaining settings as default. Later, you configure this operate to be invoked each time a brand new picture is uploaded into the S3 bucket. You may obtain the whole Lambda operate code from invoke_bedrock_claude3.py. Substitute the contents of the lambda_function.py file with the code from the downloaded file. Be sure that to substitute {SQS URL} with the URL of the SQS queue you created earlier, then select Deploy.
The Lambda operate ought to carry out the next actions:
s3 = boto3.consumer('s3')
sqs = boto3.consumer('sqs')
bedrock = boto3.consumer('bedrock-runtime', region_name="us-east-1")
QUEUE_URL = {SQS URL}
MODEL_ID = "anthropic.claude-3-sonnet-20240229-v1:0"
The next code will get the picture from the S3 bucket utilizing the get_object technique and converts it to base64 knowledge:
image_data = s3.get_object(Bucket=bucket_name, Key=object_key)['Body'].learn()
base64_image = base64.b64encode(image_data).decode('utf-8')
Immediate engineering is a vital think about unlocking the complete potential of generative AI functions like IDP. Crafting well-structured prompts makes certain that the AI system’s outputs are correct, related, and aligned together with your targets, whereas mitigating potential dangers.
With the Anthropic Claude 3 mannequin built-in into the Amazon Bedrock IDP answer, you should use the mannequin’s spectacular visible understanding capabilities to effortlessly extract knowledge from paperwork. Merely present the picture or doc as enter, and Anthropic Claude 3 will comprehend its contents, seamlessly extracting the specified info and presenting it in a human-readable format. All Anthropic Claude 3 fashions are able to understanding non-English languages corresponding to Spanish, Japanese, and French. On this explicit use case, we reveal methods to translate Spanish software varieties into English by offering the suitable immediate directions.
Nevertheless, LLMs like Anthropic Claude 3 can exhibit variability of their response codecs. To attain constant and structured output, you possibly can tailor your prompts to instruct the mannequin to return the extracted knowledge in a selected format, corresponding to JSON with predefined keys. This strategy enhances the interoperability of the mannequin’s output with downstream functions and streamlines knowledge processing workflows.
The next is the immediate with the precise JSON output format:
immediate = """
This picture reveals a start certificates software type.
Please exactly copy all of the related info from the shape.
Depart the sector clean if there isn't a info in corresponding discipline.
If the picture will not be a start certificates software type, merely return an empty JSON object.
If the applying type will not be stuffed, depart the charges attributes clean.
Translate any non-English textual content to English.
Arrange and return the extracted knowledge in a JSON format with the next keys:
{
"applicantDetails":{
"applicantName": "",
"dayPhoneNumber": "",
"handle": "",
"metropolis": "",
"state": "",
"zipCode": "",
"electronic mail":""
},
"mailingAddress":{
"mailingAddressApplicantName": "",
"mailingAddress": "",
"mailingAddressCity": "",
"mailingAddressState": "",
"mailingAddressZipCode": ""
},
"relationToApplicant":[""],
"purposeOfRequest": "",
"BirthCertificateDetails":
{
"nameOnBirthCertificate": "",
"dateOfBirth": "",
"intercourse": "",
"cityOfBirth": "",
"countyOfBirth": "",
"mothersMaidenName": "",
"fathersName": "",
"mothersPlaceOfBirth": "",
"fathersPlaceOfBirth": "",
"parentsMarriedAtBirth": "",
"numberOfChildrenBornInSCToMother": "",
"diffNameAtBirth":""
},
"charges":{
"searchFee": "",
"eachAdditionalCopy": "",
"expediteFee": "",
"totalFees": ""
}
}
"""
Invoke the Anthropic Claude 3 Sonnet mannequin utilizing the Amazon Bedrock API. Go the immediate and the base64 picture knowledge as parameters:
def invoke_claude_3_multimodal(immediate, base64_image_data):
request_body = {
"anthropic_version": "bedrock-2023-05-31",
"max_tokens": 2048,
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": prompt,
},
{
"type": "image",
"source": {
"type": "base64",
"media_type": "image/png",
"data": base64_image_data,
},
},
],
}
],
}
strive:
response = bedrock.invoke_model(modelId=MODEL_ID, physique=json.dumps(request_body))
return json.hundreds(response['body'].learn())
besides bedrock.exceptions.ClientError as err:
print(f"Could not invoke Claude 3 Sonnet. This is why: {err.response['Error']['Code']}: {err.response['Error']['Message']}")
increase
Ship the Amazon Bedrock API response to the SQS queue utilizing the send_message technique:
def send_message_to_sqs(message_body):
strive:
sqs.send_message(QueueUrl=QUEUE_URL, MessageBody=json.dumps(message_body))
besides sqs.exceptions.ClientError as e:
print(f"Error sending message to SQS: {e.response['Error']['Code']}: {e.response['Error']['Message']}")
Subsequent, modify the IAM function of the Lambda operate to grant the required permissions:
- On the Lambda console, navigate to the operate.
- On the Configuration tab, select Permissions within the left pane.
- Select the IAM function (for instance,
invoke_bedrock_claude3-role-{random chars}).

It will open the function on a brand new tab.
- Within the Permissions insurance policies part, select Add permissions and Create inline coverage.
- On the Create coverage web page, change to the JSON tab within the coverage editor.
- Enter the coverage from the next code block, changing
{AWS Account ID}together with your AWS account ID and{S3 Bucket Identify}together with your S3 bucket title. - Select Subsequent.
- Enter a reputation for the coverage (for instance,
invoke_bedrock_claude3-role-policy), and select Create coverage.
{
"Model": "2012-10-17",
"Assertion": [{
"Effect": "Allow",
"Action": "bedrock:InvokeModel",
"Resource": "arn:aws:bedrock:us-east-1::foundation-model/*"
}, {
"Effect": "Allow",
"Action": "s3:GetObject",
"Resource": "arn:aws:s3:::{S3 Bucket Name}/*"
}, {
"Effect": "Allow",
"Action": "sqs:SendMessage",
"Resource": "arn:aws:sqs:us-east-1:{AWS Account ID}:bedrock-idp-extracted-data"
}]
}
The coverage will grant the next permissions:
- Invoke mannequin entry to Amazon Bedrock FMs
- Retrieve objects from the
bedrock-claude3-idp...S3 bucket - Ship messages to the
bedrock-idp-extracted-dataSQS queue for processing the extracted knowledge
Moreover, modify the Lambda operate’s timeout to 2 minutes. By default, it’s set to three seconds.
Create an S3 Occasion Notification
To create an S3 Occasion Notification, full the next steps:
- On the Amazon S3 console, open the
bedrock-claude3-idp...S3 bucket. - Navigate to Properties, and within the Occasion notifications part, create an occasion notification.
- Enter a reputation for Occasion title (for instance,
bedrock-claude3-idp-event-notification). - Enter
photos/birth_certificates/for the prefix. - For
Occasion Kind, choose Put within the Object creation part. - For Vacation spot, choose Lambda operate and select
invoke_bedrock_claude3. - Select Save modifications.
Create a DynamoDB desk
To retailer the extracted knowledge in DynamoDB, you could create a desk. On the DynamoDB console, create a desk referred to as birth_certificates with Id because the partition key, and preserve the remaining settings as default.
Create a Lambda operate to insert information into the DynamoDB desk
On the Lambda console, create a Lambda operate (for instance, insert_into_dynamodb), select Python 3.12 for the runtime, and depart the remaining settings as default. You may obtain the whole Lambda operate code from insert_into_dynamodb.py. Substitute the contents of the lambda_function.py file with the code from the downloaded file and select Deploy.
The Lambda operate ought to carry out the next actions:
Get the message from the SQS queue that comprises the response from the Anthropic Claude 3 Sonnet mannequin:
knowledge = json.hundreds(occasion['Records'][0]['body'])['content'][0]['text']
event_id = occasion['Records'][0]['messageId']
knowledge = json.hundreds(knowledge)
Create objects representing DynamoDB and its desk:
dynamodb = boto3.useful resource('dynamodb')
desk = dynamodb.Desk('birth_certificates')Get the important thing objects from the JSON knowledge:
applicant_details = knowledge.get('applicantDetails', {})
mailing_address = knowledge.get('mailingAddress', {})
relation_to_applicant = knowledge.get('relationToApplicant', [])
birth_certificate_details = knowledge.get('BirthCertificateDetails', {})
charges = knowledge.get('charges', {})
Insert the extracted knowledge into DynamoDB desk utilizing put_item() technique:
desk.put_item(Merchandise={
'Id': event_id,
'applicantName': applicant_details.get('applicantName', ''),
'dayPhoneNumber': applicant_details.get('dayPhoneNumber', ''),
'handle': applicant_details.get('handle', ''),
'metropolis': applicant_details.get('metropolis', ''),
'state': applicant_details.get('state', ''),
'zipCode': applicant_details.get('zipCode', ''),
'electronic mail': applicant_details.get('electronic mail', ''),
'mailingAddressApplicantName': mailing_address.get('mailingAddressApplicantName', ''),
'mailingAddress': mailing_address.get('mailingAddress', ''),
'mailingAddressCity': mailing_address.get('mailingAddressCity', ''),
'mailingAddressState': mailing_address.get('mailingAddressState', ''),
'mailingAddressZipCode': mailing_address.get('mailingAddressZipCode', ''),
'relationToApplicant': ', '.be part of(relation_to_applicant),
'purposeOfRequest': knowledge.get('purposeOfRequest', ''),
'nameOnBirthCertificate': birth_certificate_details.get('nameOnBirthCertificate', ''),
'dateOfBirth': birth_certificate_details.get('dateOfBirth', ''),
'intercourse': birth_certificate_details.get('intercourse', ''),
'cityOfBirth': birth_certificate_details.get('cityOfBirth', ''),
'countyOfBirth': birth_certificate_details.get('countyOfBirth', ''),
'mothersMaidenName': birth_certificate_details.get('mothersMaidenName', ''),
'fathersName': birth_certificate_details.get('fathersName', ''),
'mothersPlaceOfBirth': birth_certificate_details.get('mothersPlaceOfBirth', ''),
'fathersPlaceOfBirth': birth_certificate_details.get('fathersPlaceOfBirth', ''),
'parentsMarriedAtBirth': birth_certificate_details.get('parentsMarriedAtBirth', ''),
'numberOfChildrenBornInSCToMother': birth_certificate_details.get('numberOfChildrenBornInSCToMother', ''),
'diffNameAtBirth': birth_certificate_details.get('diffNameAtBirth', ''),
'searchFee': charges.get('searchFee', ''),
'eachAdditionalCopy': charges.get('eachAdditionalCopy', ''),
'expediteFee': charges.get('expediteFee', ''),
'totalFees': charges.get('totalFees', '')
})
Subsequent, modify the IAM function of the Lambda operate to grant the required permissions. Comply with the identical steps you used to switch the permissions for the invoke_bedrock_claude3 Lambda operate, however enter the next JSON because the inline coverage:
{
"Model": "2012-10-17",
"Assertion": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": "dynamodb:PutItem",
"Resource": "arn:aws:dynamodb:us-east-1::{AWS Account ID}:table/birth_certificates"
},
{
"Sid": "VisualEditor1",
"Effect": "Allow",
"Action": [
"sqs:DeleteMessage",
"sqs:ReceiveMessage",
"sqs:GetQueueAttributes"
],
"Useful resource": "arn:aws:sqs:us-east-1::{AWS Account ID}:bedrock-idp-extracted-data"
}
]
}
Enter a coverage title (for instance, insert_into_dynamodb-role-policy) and select Create coverage.

The coverage will grant the next permissions:
- Put information into the DynamoDB desk
- Learn and delete messages from the SQS queue
Configure the Lambda operate set off for SQS
Full the next steps to create a set off for the Lambda operate:
- On the Amazon SQS console, open the
bedrock-idp-extracted-dataqueue. - On the Lambda triggers tab, select Configure Lambda operate set off.
- Choose the
insert_into_dynamodbLambda operate and select Save.

Take a look at the answer
Now that you’ve got created all the mandatory sources, permissions, and code, it’s time to check the answer.
Within the S3 folder birth_certificates, add the 2 scanned photos that you just downloaded earlier. Then open the DynamoDB console and discover the gadgets within the birth_certificates desk.
If all the pieces is configured correctly, it is best to see two gadgets in DynamoDB in just some seconds, as proven within the following screenshots. For the Spanish type, Anthropic Claude 3 robotically translated the keys and labels from Spanish to English primarily based on the immediate.


Troubleshooting
In the event you don’t see the extracted knowledge within the DynamoDB desk, you possibly can examine the difficulty:
- Examine CloudWatch logs – Assessment the Amazon CloudWatch log streams of the Lambda features concerned within the knowledge extraction and ingestion course of. Search for any error messages or exceptions that will point out the foundation reason for the difficulty.
- Determine lacking permissions – In lots of instances, errors can happen resulting from lacking permissions. Affirm that the Lambda features have the mandatory permissions to entry the required AWS sources, corresponding to DynamoDB tables, S3 buckets, or different providers concerned within the answer.
- Implement a dead-letter queue – In a production-scale answer, it’s endorsed to implement a lifeless letter queue (DLQ) to catch and deal with any occasions or messages that fail to course of or encounter errors.
Clear up
Clear up the sources created as a part of this put up to keep away from incurring ongoing prices:
- Delete all of the objects from the
bedrock-claude3-idp...S3 bucket, then delete the bucket. - Delete the 2 Lambda features named
invoke_bedrock_claude3andinsert_into_dynamodb. - Delete the SQS queue named
bedrock-idp-extracted-data. - Delete the DynamoDB desk named
birth_certificates.
Instance use instances and enterprise worth
The generative AI-powered IDP answer demonstrated on this put up can profit organizations throughout varied industries, corresponding to:
- Authorities and public sector – Course of and extract knowledge from citizen functions, immigration paperwork, authorized contracts, and different government-related varieties, enabling sooner turnaround instances and improved service supply
- Healthcare – Extract and manage affected person info, medical information, insurance coverage claims, and different health-related paperwork, bettering knowledge accuracy and accessibility for higher affected person care
- Finance and banking – Automate the extraction and processing of economic paperwork, mortgage functions, tax varieties, and regulatory filings, lowering guide effort and rising operational effectivity
- Logistics and provide chain – Extract and manage knowledge from transport paperwork, invoices, buy orders, and stock information, streamlining operations and enhancing provide chain visibility
- Retail and ecommerce – Automate the extraction and processing of buyer orders, product catalogs, and advertising supplies, enabling personalised experiences and environment friendly order success
Through the use of the ability of generative AI and Amazon Bedrock, organizations can unlock the true potential of their knowledge, driving operational excellence, enhancing buyer experiences, and fostering steady innovation.
Conclusion
On this put up, we demonstrated methods to use Amazon Bedrock and the highly effective Anthropic Claude 3 Sonnet mannequin to develop an IDP answer. By harnessing the superior multimodal capabilities of Anthropic Claude 3, we had been in a position to precisely extract knowledge from scanned paperwork and retailer it in a structured format in a DynamoDB desk.
Though this answer showcases the potential of generative AI in IDP, it is probably not appropriate for all IDP use instances. The effectiveness of the answer could fluctuate relying on the complexity and high quality of the paperwork, the quantity of coaching knowledge obtainable, and the precise necessities of the group.
To additional improve the answer, think about implementing a human-in-the-loop workflow to evaluate and validate the extracted knowledge, particularly for mission-critical or delicate functions. It will present knowledge accuracy and compliance with regulatory necessities. It’s also possible to discover the mannequin analysis function in Amazon Bedrock to match mannequin outputs, after which select the mannequin finest suited in your downstream generative AI functions.
For additional exploration and studying, we suggest trying out the next sources:
Concerning the Authors
 Govind Palanisamy is a Options Architect at AWS, the place he helps authorities companies migrate and modernize their workloads to extend citizen expertise. He’s obsessed with know-how and transformation, and he helps clients rework their companies utilizing AI/ML and generative AI-based options.
Govind Palanisamy is a Options Architect at AWS, the place he helps authorities companies migrate and modernize their workloads to extend citizen expertise. He’s obsessed with know-how and transformation, and he helps clients rework their companies utilizing AI/ML and generative AI-based options.
 Bharath Gunapati is a Sr. Options architect at AWS, the place he helps clinicians, researchers, and workers at tutorial medical facilities to undertake and use cloud applied sciences. He’s obsessed with know-how and the affect it could possibly make on healthcare and analysis.
Bharath Gunapati is a Sr. Options architect at AWS, the place he helps clinicians, researchers, and workers at tutorial medical facilities to undertake and use cloud applied sciences. He’s obsessed with know-how and the affect it could possibly make on healthcare and analysis.



{kind=link}