
In 2024, the Ministry of Economic system, Commerce and Business (METI) launched the Generative AI Accelerator Problem (GENIAC)—a Japanese nationwide program to spice up generative AI by offering firms with funding, mentorship, and large compute sources for basis mannequin (FM) improvement. AWS was chosen because the cloud supplier for GENIAC’s second cycle (cycle 2). It supplied infrastructure and technical steering for 12 taking part organizations. On paper, the problem appeared simple: give every crew entry to a whole bunch of GPUs/Trainium chips and let innovation ensue. In observe, profitable FM coaching required excess of uncooked {hardware}.
AWS found that allocating over 1,000 accelerators was merely the place to begin—the actual problem lay in architecting a dependable system and overcoming distributed coaching obstacles. Throughout GENIAC cycle 2, 12 prospects efficiently deployed 127 Amazon EC2 P5 situations (NVIDIA H100 TensorCore GPU servers) and 24 Amazon EC2 Trn1 situations (AWS Trainium1 servers) in a single day. Over the next 6 months, a number of large-scale fashions have been educated, together with notable initiatives like Stockmark-2-100B-Instruct-beta, Llama 3.1 Shisa V2 405B, and Llama-3.1-Future-Code-Ja-8B, and others.
This publish shares the important thing insights from this engagement and worthwhile classes for enterprises or nationwide initiatives aiming to construct FMs at scale.
Cross-functional engagement groups
A vital early lesson from technical engagement for the GENIAC was that working a multi-organization, national-scale machine studying (ML) initiative requires coordinated help throughout various inner groups. AWS established a digital crew that introduced collectively account groups, specialist Options Architects, and repair groups. The GENIAC engagement mannequin thrives on shut collaboration between prospects and a multi-layered AWS crew construction, as illustrated within the following determine.
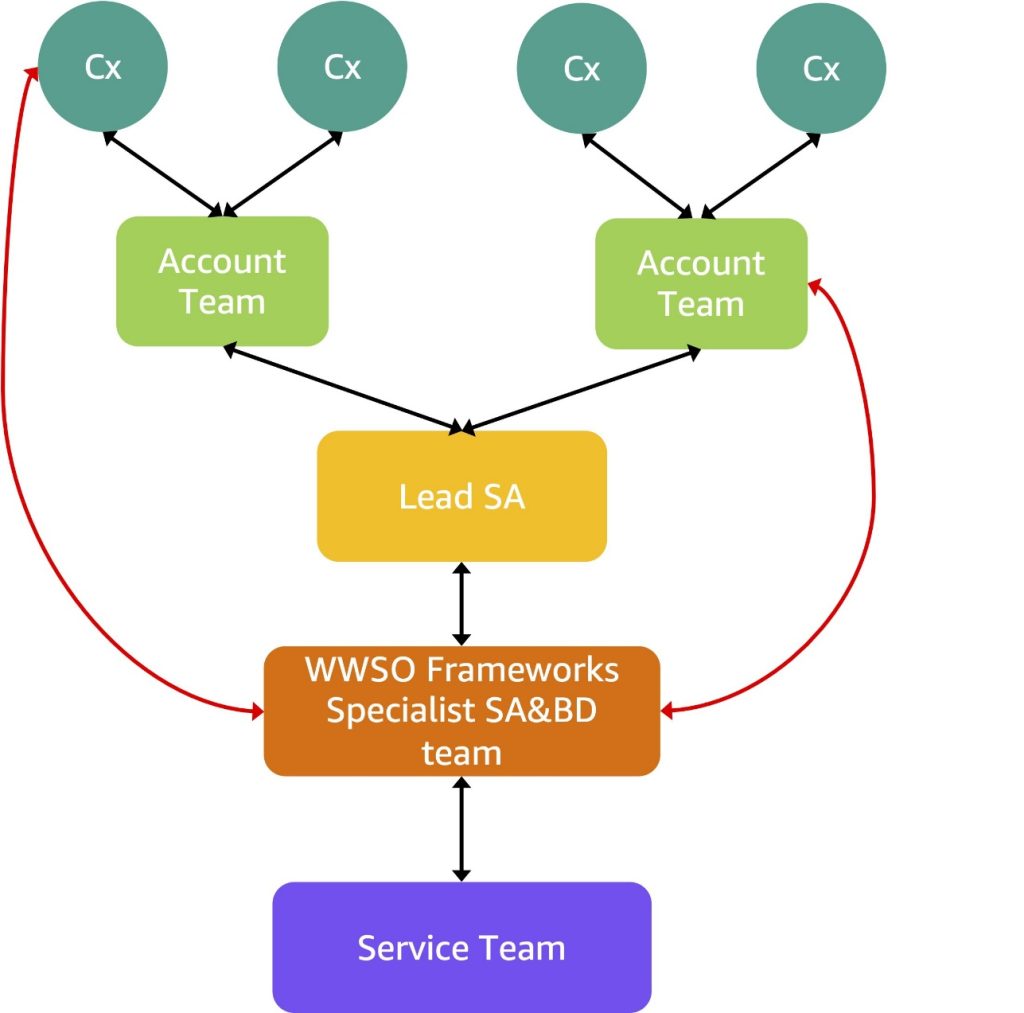
Clients (Cx) sometimes encompass enterprise and technical leads, together with ML and platform engineers, and are answerable for executing coaching workloads. AWS account groups (Options Architects and Account Managers) handle the connection, keep documentation, and keep communication flows with prospects and inner specialists. The World Large Specialist Group (WWSO) Frameworks crew makes a speciality of large-scale ML workloads, with a deal with core HPC and container companies equivalent to AWS ParallelCluster, Amazon Elastic Kubernetes Service (Amazon EKS), and Amazon SageMaker HyperPod. The WWSO Frameworks crew is answerable for establishing this engagement construction and supervising technical engagements on this program. They lead the engagement in partnership with different stakeholders and function an escalation level for different stakeholders. They work immediately with the service groups—Amazon Elastic Compute Cloud (Amazon EC2), Amazon Easy Storage Service (Amazon S3), Amazon FSx, and SageMaker HyperPod—to assist navigate engagements, escalations (enterprise and technical), and ensure the engagement framework is in working order. They supply steering on coaching and inference to prospects and educate different groups on the know-how. The WWSO Frameworks crew labored carefully with Lead Options Architects (Lead SAs), a task particularly designated to help GENIAC engagements. These Lead SAs function a cornerstone of this engagement. They’re an extension of the Frameworks specialist crew and work immediately with prospects and the account groups. They interface with prospects and interact their Framework specialist counterparts when clarification or additional experience is required for in-depth technical discussions or troubleshooting. With this layered construction, AWS can scale technical steering successfully throughout complicated FM coaching workloads.
One other important success issue for GENIAC was establishing sturdy communication channels between prospects and AWS members. The inspiration of our communication technique was a devoted inner Slack channel for GENIAC program coordination, connecting AWS account groups with lead SAs. This channel enabled real-time troubleshooting, information sharing, and fast escalation of buyer points to the suitable technical specialists and repair crew members. Complementing this was an exterior Slack channel that bridged AWS groups with prospects, making a collaborative atmosphere the place contributors may ask questions, share insights, and obtain quick help. This direct line of communication considerably lowered decision instances and fostered a neighborhood of observe amongst contributors.
AWS maintained complete workload monitoring paperwork, which clarifies every buyer’s coaching implementation particulars (mannequin structure, distributed coaching frameworks, and associated software program elements) alongside infrastructure specs (occasion varieties and portions, cluster configurations for AWS ParallelCluster or SageMaker HyperPod deployments, and storage options together with Amazon FSx for Lustre and Amazon S3). This monitoring system additionally maintained a chronological historical past of buyer interactions and help instances. As well as, the engagement crew held weekly evaluation conferences to trace excellent buyer inquiries and technical points. This common cadence made it doable for crew members to share classes discovered and apply them to their very own buyer engagements, fostering steady enchancment and information switch throughout this system.
With a structured strategy to communication and documentation, we may establish widespread challenges, equivalent to misconfigured NCCL library impacting multi-node efficiency, share options throughout groups, and repeatedly refine our engagement mannequin. The detailed monitoring system supplied worthwhile insights for future GENIAC cycles, serving to us anticipate buyer wants and proactively deal with potential bottlenecks within the FM improvement course of.
Reference architectures
One other early takeaway was the significance of stable reference architectures. Fairly than let every crew configure their very own cluster from scratch, AWS created pre-validated templates and automation for 2 essential approaches: AWS ParallelCluster (for a user-managed HPC cluster) and SageMaker HyperPod (for a managed, resilient cluster service). These reference architectures lined the complete stack—from compute, community, and storage to container environments and monitoring—and have been delivered as a GitHub repository so groups may deploy them with minimal friction.
AWS ParallelCluster proved invaluable as an open supply cluster administration device for multi-node GPU coaching. AWS ParallelCluster automates the setup of a Slurm-based HPC cluster on AWS. AWS ParallelCluster simplifies cluster provisioning based mostly on the open supply Slurm scheduler, utilizing a easy YAML config to face up the atmosphere. For the GEINIAC program, AWS additionally supplied SageMaker HyperPod as another choice for some groups. SageMaker HyperPod is a managed service that provisions GPU and Trainium clusters for large-scale ML. HyperPod integrates with orchestrators like Slurm or Kubernetes (Amazon EKS) for scheduling, offering extra managed performance round cluster resiliency. By together with reference architectures for each AWS ParallelCluster and SageMaker HyperPod, the GENIAC program gave contributors flexibility—some opted for the fine-grained management of managing their very own HPC cluster, whereas others most popular the comfort and resilience of a managed SageMaker HyperPod cluster.
The reference structure (proven within the following diagram) seamlessly combines compute, networking, storage, and monitoring into an built-in system particularly designed for large-scale FM coaching.
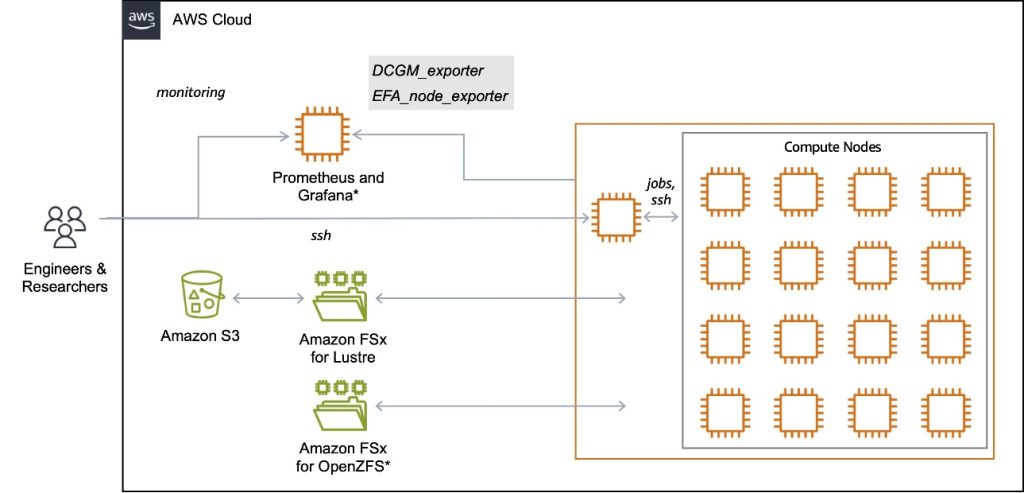
The bottom infrastructure stack is out there as an AWS CloudFormation template that provisions the whole infrastructure stack with minimal effort. This template mechanically configures a devoted digital personal cloud (VPC) with optimized networking settings and implements a high-performance FSx for Lustre file system for coaching knowledge (complemented by non-compulsory Amazon FSx for OpenZFS help for shared house directories). The structure is accomplished with an S3 bucket that gives sturdy, long-term storage for datasets and mannequin checkpoints, sustaining knowledge availability nicely past particular person coaching cycles. This reference structure employs a hierarchical storage strategy that balances efficiency and cost-effectiveness. It makes use of Amazon S3 for sturdy, long-term storage of coaching knowledge and checkpoints, and hyperlinks this bucket to the Lustre file system by means of an information repository affiliation (DRA). The DRA allows automated and clear knowledge switch between Amazon S3 and FSx for Lustre, permitting high-performance entry with out handbook copying. You should utilize the next CloudFormation template to create the S3 bucket used on this structure.
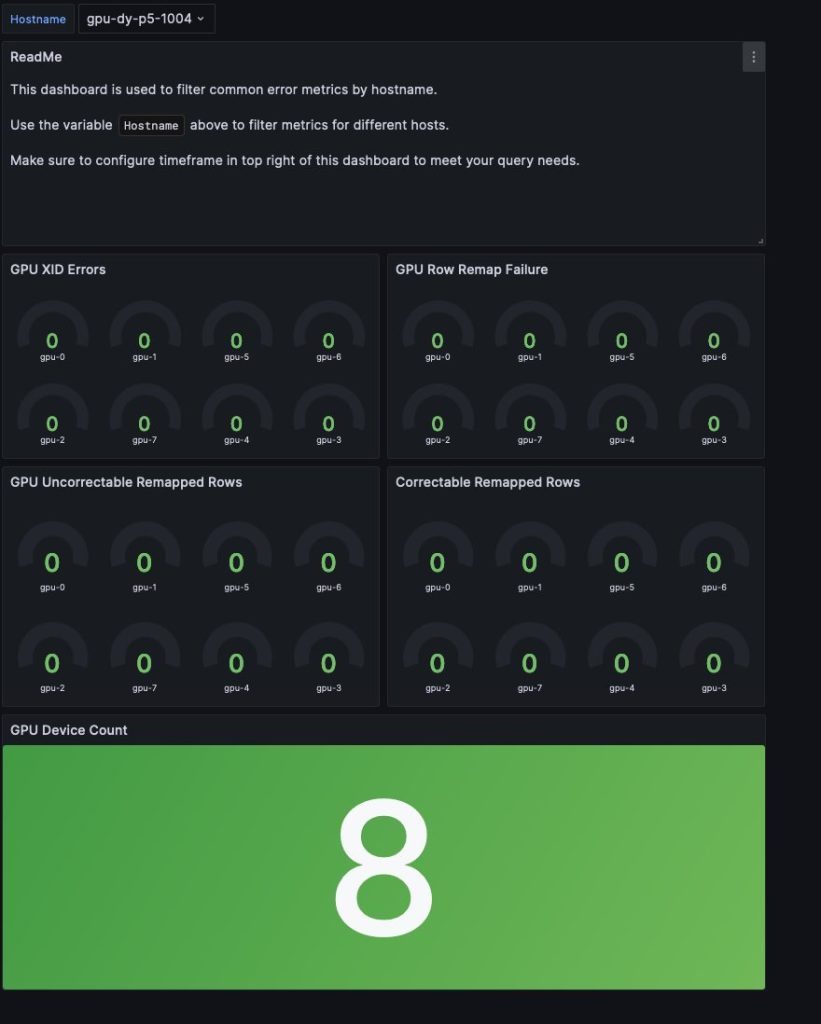
The non-compulsory monitoring infrastructure combines Amazon Managed Service for Prometheus and Amazon Managed Grafana (or self-managed Grafana service working on Amazon EC2) to offer complete observability. It built-in DCGM Exporter for GPU metrics and EFA Exporter for community metrics, enabling real-time monitoring of system well being and efficiency. This setup permits for steady monitoring of GPU well being, community efficiency, and coaching progress, with automated alerting for anomalies by means of Grafana Dashboards. For instance, the GPU Well being Dashboard (see the next screenshot) offers metrics of widespread GPU errors, together with Uncorrectable Remapped Rows, Correctable Remapped Rows, XID Error Codes, Row Remap Failure, Thermal Violations, and Lacking GPUs (from Nvidia-SMI), serving to customers establish {hardware} failures as shortly as doable.
Reproducible deployment guides and structured enablement classes
Even one of the best reference architectures are solely helpful if groups know how one can use them. A important factor of GENIAC’s success was reproducible deployment guides and structured enablement by means of workshops.On October 3, 2024, AWS Japan and the WWSO Frameworks crew carried out a mass enablement session for GENIAC Cycle 2 contributors, inviting Frameworks crew members from the USA to share finest practices for FM coaching on AWS.
The enablement session welcomed over 80 contributors and supplied a complete mixture of lectures, hands-on labs, and group discussions—incomes a CSAT rating of 4.75, reflecting its robust impression and relevance to attendees. The lecture classes lined infrastructure fundamentals, exploring orchestration choices equivalent to AWS ParallelCluster, Amazon EKS, and SageMaker HyperPod, together with the software program elements mandatory to construct and practice large-scale FMs utilizing AWS. The classes highlighted sensible challenges in FM improvement—together with large compute necessities, scalable networking, and high-throughput storage—and mapped them to applicable AWS companies and finest practices. (For extra info, see the slide deck from the lecture session.) One other session centered on finest practices, the place attendees discovered to arrange efficiency dashboards with Prometheus and Grafana, monitor EFA visitors, and troubleshoot GPU failures utilizing NVIDIA’s DCGM toolkit and customized Grafana dashboards based mostly on the Frameworks crew’s expertise managing a cluster with 2,000 P5 situations.
Moreover, the WWSO crew ready workshops for each AWS ParallelCluster (Machine Studying on AWS ParallelCluster) and SageMaker HyperPod (Amazon SageMaker HyperPod Workshop), offering detailed deployment guides for the aforementioned reference structure. Utilizing these supplies, contributors carried out hands-on workouts deploying their coaching clusters utilizing Slurm with file techniques together with FSx for Lustre and FSx for OpenZFS, working multi-node PyTorch distributed coaching. One other section of the workshop centered on observability and efficiency tuning, educating contributors how one can monitor useful resource utilization, community throughput (EFA visitors), and system well being. By the top of those enablement classes, prospects and supporting AWS engineers had established a shared baseline of information and a toolkit of finest practices. Utilizing the property and information gained through the workshops, prospects participated in onboarding classes—structured, hands-on conferences with their Lead SAs. These classes differed from the sooner workshops by specializing in customer-specific cluster deployments tailor-made to every crew’s distinctive use case. Throughout every session, Lead SAs labored immediately with groups to deploy coaching environments, validate setup utilizing NCCL assessments, and resolve technical points in actual time.
Buyer suggestions
“To essentially resolve knowledge entry challenges, we considerably improved processing accuracy and cost-efficiency by making use of two-stage reasoning and autonomous studying with SLM and LLM for normal objects, and visible studying with VLM utilizing 100,000 artificial knowledge samples for detailed objects. We additionally utilized Amazon EC2 P5 situations to boost analysis and improvement effectivity. These bold initiatives have been made doable due to the help of many individuals, together with AWS. We’re deeply grateful for his or her intensive help.”
– Takuma Inoue, Govt Officer, CTO at AI Inside
“Future selected AWS to develop large-scale language fashions specialised for Japanese and software program improvement at GENIAC. When coaching large-scale fashions utilizing a number of nodes, Future had issues about atmosphere settings equivalent to inter-node communication, however AWS had a variety of instruments, equivalent to AWS ParallelCluster, and we acquired robust help from AWS Options Architects, which enabled us to start out large-scale coaching shortly.”
– Makoto Morishita, Chief Analysis Engineer at Future
Outcomes and searching forward
GENIAC has demonstrated that coaching FMs at scale is essentially an organizational problem, not merely a {hardware} one. Via structured help, reproducible templates, and a cross-functional engagement crew (WWSO Frameworks Group, Lead SAs, and Account Groups), even small groups can efficiently execute large workloads within the cloud. Due to this construction, 12 prospects launched over 127 P5 situations and 24 Trn1 situations throughout a number of AWS Areas, together with Asia Pacific (Tokyo), in a single day. A number of massive language fashions (LLMs) and customized fashions have been educated efficiently, together with a 32B multimodal mannequin on Trainium and a 405B tourism-focused multilingual mannequin.The technical engagement framework established by means of GENIAC Cycle 2 has supplied essential insights into large-scale FM improvement. Constructing on this expertise, AWS is advancing enhancements throughout a number of dimensions: engagement fashions, technical property, and implementation steering. We’re strengthening cross-functional collaboration and systematizing information sharing to determine a extra environment friendly help construction. Reference architectures and automatic coaching templates proceed to be enhanced, and sensible technical workshops and finest practices are being codified based mostly on classes discovered.AWS has already begun preparations for the subsequent cycle of GENIAC. As a part of the onboarding course of, AWS hosted a complete technical occasion in Tokyo on April 3, 2025, to equip FM builders with hands-on expertise and architectural steering. The occasion, attended by over 50 contributors, showcased the dedication AWS has to supporting scalable, resilient generative AI infrastructure.

The occasion highlighted the technical engagement mannequin of AWS for GENIAC, alongside different help mechanisms, together with the LLM Improvement Assist Program and Generative AI Accelerator. The day featured an intensive workshop on SageMaker HyperPod and Slurm, the place contributors gained hands-on expertise with multi-node GPU clusters, distributed PyTorch coaching, and observability instruments. Classes lined important matters, together with containerized ML, distributed coaching methods, and AWS purpose-built silicon options. Classmethod Inc. shared sensible SageMaker HyperPod insights, and AWS engineers demonstrated architectural patterns for large-scale GPU workloads. The occasion showcased AWS’s end-to-end generative AI help panorama, from infrastructure to deployment instruments, setting the stage for GENIAC Cycle 3. As AWS continues to increase its help for FM improvement, the success of GENIAC serves as a blueprint for enabling organizations to construct and scale their AI capabilities successfully.
Via these initiatives, AWS will proceed to offer sturdy technical help, facilitating the graceful execution of large-scale FM coaching. We stay dedicated to contributing to the development of generative AI improvement all around the world by means of our technical experience.
This publish was contributed by AWS GENIAC Cycle 2 core members Masato Kobayashi, Kenta Ichiyanagi, and Satoshi Shirasawa, Accelerated Computing Specialist Mai Kiuchi, in addition to Lead SAs Daisuke Miyamoto, Yoshitaka Haribara, Kei Sasaki, Soh Ohara, and Hiroshi Tokoyo with Govt Sponsorship from Toshi Yasuda. Hiroshi Hata and Tatsuya Urabe additionally supplied help as core member and Lead SA throughout their time at AWS.
The authors prolong their gratitude to WWSO Frameworks members Maxime Hugues, Matthew Nightingale, Aman Shanbhag, Alex Iankoulski, Anoop Saha, Yashesh Shroff, Natarajan Chennimalai Kumar, Shubha Kumbadakone, and Sundar Ranganathan for his or her technical contributions. Pierre-Yves Aquilanti supplied in-depth help throughout his time at AWS.
Concerning the authors
 Keita Watanabe is a Senior Specialist Options Architect on the AWS WWSO Frameworks crew. His background is in machine studying analysis and improvement. Previous to becoming a member of AWS, Keita labored within the ecommerce business as a analysis scientist creating picture retrieval techniques for product search. He leads GENIAC technical engagements.
Keita Watanabe is a Senior Specialist Options Architect on the AWS WWSO Frameworks crew. His background is in machine studying analysis and improvement. Previous to becoming a member of AWS, Keita labored within the ecommerce business as a analysis scientist creating picture retrieval techniques for product search. He leads GENIAC technical engagements.
 Masaru Isaka is a Principal Enterprise Improvement on the AWS WWSO Frameworks crew, specializing in machine studying and generative AI options. Having engaged with GENIAC since its inception, he leads go-to-market methods for AWS’s generative AI choices.
Masaru Isaka is a Principal Enterprise Improvement on the AWS WWSO Frameworks crew, specializing in machine studying and generative AI options. Having engaged with GENIAC since its inception, he leads go-to-market methods for AWS’s generative AI choices.



{kind=link}