
within the subject of enormous language fashions (LLM) and their functions is very fast. Prices are coming down and basis fashions have gotten more and more succesful, in a position to deal with communication in textual content, pictures, video. Open supply options have additionally exploded in variety and functionality, with many fashions being light-weight sufficient to discover, fine-tune and iterate on with out large expense. Lastly, cloud AI coaching and inference suppliers reminiscent of Databricks and Nebius are making it more and more simple for organizations to scale up their utilized AI merchandise from POCs to manufacturing prepared programs. These advances go hand in hand with a diversification of the enterprise makes use of of LLMs and the rise of agentic functions, the place fashions plan and execute advanced multi-step workflows which will contain interplay with instruments or different brokers. These applied sciences are already making an impression in healthcare and that is projected to develop quickly [1].
All of this functionality makes it thrilling to get began, and constructing a baseline answer for a selected use case will be very quick. Nevertheless, by their nature LLMs are non-deterministic and fewer predictable than conventional software program or ML fashions. The actual problem due to this fact is available in iteration: How do we all know that our growth course of is enhancing the system? If we repair an issue, how do we all know if the change gained’t break one thing else? As soon as in manufacturing, how can we verify if efficiency is on par with what we noticed in growth? Answering these questions with programs that make single LLM calls is tough sufficient, however with agentic programs we additionally want to think about all the person steps and routing choices made between them. To deal with these points — and due to this fact achieve belief and confidence within the programs we construct — we want evaluation-driven growth. This can be a methodology that locations iterative, actionable analysis on the core of the product lifecycle from growth and deployment to monitoring.
As an information scientist at Nuna, Inc., a healthcare AI firm, I’ve been spearheading our efforts to embed evaluation-driven growth into our merchandise. With the assist of our management, we’re sharing among the key classes we’ve discovered to date. We hope these insights will likely be worthwhile not solely to these constructing AI in healthcare but in addition to anybody growing AI merchandise, particularly these simply starting their journey.
This text is damaged into the next sections, which search to elucidate our broad learnings from the literature along with tips and suggestions gained from expertise.
- In Part 1 we’ll briefly contact on Nuna’s merchandise and clarify why AI analysis is so essential for us and for healthcare-focused AI typically.
- In Part 2, we’ll discover how evaluation-driven growth brings construction to the pre-deployment section of our merchandise. This entails growing metrics utilizing each LLM-as-Decide and programmatic approaches, that are closely impressed by this glorious article. As soon as dependable judges and expert-aligned metrics have been established, we describe use them to iterate in the correct course utilizing error evaluation. On this part, we’ll additionally contact on the distinctive challenges posed by chatbot functions.
- In Part 3, we’ll focus on using model-based classification and alerting to observe functions in manufacturing and use this suggestions for additional enhancements.
- Part 4 summarizes all that we’ve discovered
Any group’s perspective on these topics is influenced by the instruments it makes use of — for instance we use MLflow and Databricks Mosaic Analysis to maintain monitor of our pre-production experiments, and AWS Agent Analysis to check our chatbot. Nevertheless, we consider that the concepts offered right here must be relevant no matter tech stack, and there are lots of glorious choices out there from the likes of Arize (Phoenix analysis suite), LangChain (LangSmith) and Assured AI (DeepEval). Right here we’ll concentrate on initiatives the place iterative growth primarily entails immediate engineering, however an identical strategy might be adopted for fine-tuned fashions too.
1.0 AI and analysis at Nuna
Nuna’s aim is to cut back the whole value of care and enhance the lives of individuals with persistent situations reminiscent of hypertension (hypertension) and diabetes, which collectively have an effect on greater than 50% of the US grownup inhabitants [2,3]. That is executed by means of a patient-focused cell app that encourages wholesome habits reminiscent of medicine adherence and blood stress monitoring, along with a care-team-focused dashboard that organizes information from the app to suppliers*. To ensure that the system to succeed, each sufferers and care groups should discover it simple to make use of, partaking and insightful. It should additionally produce measurable advantages to well being. That is essential as a result of it distinguishes healthcare expertise from most different expertise sectors, the place enterprise success is extra intently tied to engagement alone.
AI performs a essential, affected person and care-team-facing position within the product: On the affected person aspect we have now an in-app care coach chatbot, in addition to options reminiscent of medicine containers and meal photo-scanning. On the care-team aspect we’re growing summarization and information sorting capabilities to cut back time to motion and tailor the expertise for various customers. The desk under reveals the 4 AI-powered product elements whose growth served as inspiration for this text, and which will likely be referred to within the following sections.
| Product description | Distinctive traits | Most crucial analysis elements |
| Scanning of medicine containers (picture to textual content) | Multimodal with clear floor fact labels (medicine particulars extracted from container) | Consultant growth dataset, iteration and monitoring, monitoring in manufacturing |
| Scanning of meals (ingredient extraction, dietary insights and scoring) | Multimodal, combination of clear floor fact (extracted elements) and subjective judgment of LLM-generated assessments & SME enter | Consultant growth dataset, acceptable metrics, iteration and monitoring, monitoring in manufacturing |
| In-app care coach chatbot (textual content to textual content) | Multi-turn transcripts, software calling, extensive number of personas and use circumstances, subjective judgement | Consultant growth dataset, acceptable metrics, monitoring in manufacturing |
| Medical report summarization (textual content & numerical information to textual content) | Advanced enter information, slender use case, essential want for top accuracy and SME judgement | Consultant growth dataset, expert-aligned LLM-judge, iteration & monitoring |
Respect for sufferers and the delicate information they entrust us with is on the core of our enterprise. Along with safeguarding information privateness, we should make sure that our AI merchandise function in methods which can be protected, dependable, and aligned with customers’ wants. We have to anticipate how individuals would possibly use the merchandise and take a look at each normal and edge-case makes use of. The place errors are doable — reminiscent of ingredient recognition from meal images — we have to know the place to put money into constructing methods for customers to simply appropriate them. We additionally should be looking out for extra delicate failures — for instance, latest analysis means that extended chatbot use can result in elevated emotions of loneliness — so we have to establish and monitor for regarding use circumstances to make sure that our AI is aligned with the aim of enhancing lives and decreasing value of care. This aligns with suggestions from the NIST AI Threat Administration Framework, which emphasizes preemptive identification of believable misuse eventualities, together with edge circumstances and unintended penalties, particularly in high-impact domains reminiscent of healthcare.
*This technique supplies wellness assist solely and isn’t supposed for medical prognosis, therapy, or to interchange skilled healthcare judgment.
2.0 Pre-deployment: Metrics, alignment and iteration
Within the growth stage of an LLM-powered product, you will need to set up analysis metrics which can be aligned with the enterprise/product targets, a testing dataset that’s consultant sufficient to simulate manufacturing conduct and a sturdy methodology to really calculate the analysis metrics. With these items in place, we are able to enter the virtuous cycle of iteration and error evaluation (see this brief guide for particulars). The sooner we are able to iterate in the correct course, the upper our probabilities of success. It additionally goes with out saying that every time testing entails passing delicate information by means of an LLM, it have to be executed from a safe atmosphere with a trusted supplier in accordance with information privateness rules. For instance, in america, the Well being Insurance coverage Portability and Accountability Act (HIPAA) units strict requirements for safeguarding sufferers’ well being info. Any dealing with of such information should meet HIPAA’s necessities for safety and confidentiality.
2.1 Improvement dataset
On the outset of a undertaking, you will need to establish and have interaction with subject material specialists (SMEs) who will help generate instance enter information and outline what success appears to be like like. At Nuna our SMEs are advisor healthcare professionals reminiscent of physicians and nutritionists. Relying on the issue context, we’ve discovered that opinions from healthcare specialists will be practically uniform — the place the reply will be sourced from core ideas of their coaching — or fairly diverse, drawing on their particular person experiences. To mitigate this, we’ve discovered it helpful to hunt recommendation from a small panel of specialists (sometimes 2-5) who’re engaged from the start of the undertaking and whose consensus view acts as our final supply of fact.
It’s advisable to work with the SMEs to construct a consultant dataset of inputs to the system. To do that, we must always take into account the broad classes of personas who is perhaps utilizing it and the principle functionalities. The broader the use case, the extra of those there will likely be. For instance, the Nuna chatbot is accessible to all customers, helps reply any wellness-based query and in addition has entry to the person’s personal information through software calls. A few of the functionalities are due to this fact “emotional assist”, “hypertension assist”, “diet recommendation”, “app assist”, and we’d take into account splitting these additional into “new person” vs. “exiting person” or “skeptical person” vs. “energy person” personas. This segmentation is helpful for the info technology course of and error evaluation in a while, after these inputs have run by means of the system.
It’s additionally essential to think about particular eventualities — each typical and edge-case — that the system should deal with. For our chatbot these embody “person asks for a prognosis primarily based on signs” (we at all times refer them to a healthcare skilled in such conditions), “person ask is truncated or incomplete”, “person makes an attempt to jailbreak the system”. After all, it’s unlikely that every one essential eventualities will likely be accounted for, which is why later iteration (part 2.5) and monitoring in manufacturing (part 3.0) is required.
With the classes in place, the info itself is perhaps generated by filtering current proprietary or open supply datasets (e.g. Nutrition5k for meals pictures, OpenAI’s HealthBench for patient-clinician conversations). In some circumstances, each inputs and gold normal outputs is perhaps out there, for instance within the ingredient labels on every picture in Nutition5k. This makes metric design (part 2.3) simpler. Extra generally although, knowledgeable labelling will likely be required for the gold normal outputs. Certainly, even when pre-existing enter examples are usually not out there, these will be generated synthetically with an LLM after which curated by the crew — Databricks has some instruments for this, described right here.
How large ought to this growth set be? The extra examples we have now, the extra seemingly it’s to be consultant of what the mannequin will see in manufacturing however the dearer it is going to be to iterate. Our growth units sometimes begin out on the order of some hundred examples. For chatbots, the place to be consultant the inputs would possibly should be multi-step conversations with pattern affected person information in context, we suggest utilizing a testing framework like AWS Agent Analysis, the place the enter instance information will be generated manually or through LLM by prompting and curation.
2.2 Baseline mannequin pipeline
If ranging from scratch, the method of pondering by means of the use circumstances and constructing the event set will seemingly give the crew a way for the problem of this downside and therefore the structure of the baseline system to be constructed. Except made infeasible by safety or value issues, it’s advisable to maintain the preliminary structure easy and use highly effective, API-based fashions for the baseline iteration. The primary goal of the iteration course of described in subsequent sections is to enhance the prompts on this baseline model, so we sometimes preserve them easy whereas making an attempt to stick to basic immediate engineering finest practices reminiscent of these described on this information by Anthropic.
As soon as the baseline system is up and working, it must be run on the event set to generate the primary outputs. Operating the event dataset by means of the system is a batch course of which will should be repeated many occasions, so it’s value parallelizing. At Nuna we use PySpark on Databricks for this. Essentially the most easy methodology for batch parallelism of this sort is the pandas user-defined perform (UDF), which permits us to name the mannequin API in a loop over rows in Pandas dataframe, after which use Pyspark to interrupt up the enter dataset into chunks to be processed in parallel over the nodes of a cluster. Another methodology, described right here, first requires us to log a script that calls the mannequin as an mlflow PythonModel object, load that as a pandas UDF after which run inference utilizing that.

2.3 Metric design
Designing analysis metrics which can be actionable and aligned with the function’s targets is a essential a part of evaluation-driven growth. Given the context of the function you’re growing, there could also be some metrics which can be minimal necessities for ship — e.g. a minimal price of the numerical accuracy for a textual content abstract on a graph. Particularly in a healthcare context, we have now discovered that SMEs are once more important assets right here within the identification of extra supplementary metrics that will likely be essential for stakeholder buy-in and end-user interpretation. Asynchronously, SMEs ought to have the ability to securely evaluation the inputs and outputs from the event set and make feedback on them. Numerous purpose-built instruments assist this sort of evaluation and will be tailored to the undertaking’s sensitivity and maturity. For early-stage or low-volume work, light-weight strategies reminiscent of a safe spreadsheet might suffice. If doable, the suggestions ought to include a easy go/fail determination for every enter/output pair, together with critique of the LLM-generated output explaining the choice. The concept is that we are able to then use these critiques to tell our alternative of analysis metrics and supply few-shot examples to any LLM-judges that we construct. Why go/fail fairly than a likert rating or another numerical metric? This can be a developer alternative, however we discovered it’s a lot simpler to get alignment between SMEs and LLM judges within the binary case. It’s easy to mixture outcomes right into a easy accuracy measure throughout the event set. For instance, if 30% of the “90 day blood stress time collection summaries” get a zero for groundedness however not one of the 30 day summaries do, then this factors to the mannequin combating lengthy inputs.
On the preliminary evaluation stage, it’s usually additionally helpful to doc a transparent set of pointers round what constitutes success within the outputs, which permits all annotators to have a supply of fact. Disagreements between SME annotators can usually be resolved close to these pointers, and if disagreements persist this can be an indication that the rules — and therefore the aim of the AI system — shouldn’t be outlined clearly sufficient. It’s additionally essential to notice that relying in your firm’s resourcing, ship timelines, and danger degree of the function, it will not be doable to get SME feedback on your entire growth set right here — so it’s essential to decide on consultant examples.
As a concrete instance, Nuna has developed a drugs logging historical past AI abstract, to be displayed within the care team-facing portal. Early within the growth of this AI abstract, we curated a set of consultant affected person data, ran them by means of the summarization mannequin, plotted the info and shared a safe spreadsheet containing the enter graphs and output summaries with our SMEs for his or her feedback. From this train we recognized and documented the necessity for a variety of metrics together with readability, model (i.e. goal and never alarmist), formatting and groundedness (i.e. accuracy of insights towards the enter timeseries).
Some metrics will be calculated programmatically with easy assessments on the output. This contains formatting and size constraints, and readability as quantified by scores just like the F-Okay grade degree. Different metrics require an LLM-judge (see under for extra element) as a result of the definition of success is extra nuanced. That is the place we immediate an LLM to behave like a human knowledgeable, giving go/fail choices and critiques of the outputs. The concept is that if we are able to align the LLM choose’s outcomes with these of the specialists, we are able to run it robotically on our growth set and shortly compute our metrics when iterating.
We discovered it helpful to decide on a single “optimizing metric” for every undertaking, for instance the proportion of the event set that’s marked as precisely grounded within the enter information, however again it up with a number of “satisficing metrics” reminiscent of % inside size constraints, % with appropriate model, % with readability rating > 60 and so forth. Elements like latency percentile and imply token value per request additionally make preferrred satisficing metrics. If an replace makes the optimizing metric worth go up with out decreasing any of the satisficing metric values under pre-defined thresholds, then we all know we’re getting in the correct course.
2.4 Constructing the LLM choose
The aim of LLM-judge growth is to distill the recommendation of the SMEs right into a immediate that permits an LLM to attain the event set in a approach that’s aligned with their skilled judgement. The choose is often a bigger/extra highly effective mannequin than the one being judged, although this isn’t a strict requirement. We discovered that whereas it’s doable to have a single LLM choose immediate output the scores and critiques for a number of metrics, this may be complicated and incompatible with the monitoring instruments described in 2.4. We due to this fact make a single choose immediate per metric, which has the additional benefit of forcing conservatism on the variety of LLM-generated metrics.
An preliminary choose immediate, to be run on the event set, would possibly look one thing just like the block under. The directions will likely be iterated on through the alignment step, so at this stage they need to characterize a finest effort to seize the SME’s thought course of when writing their criques. It’s essential to make sure that the LLM supplies its reasoning, and that that is detailed sufficient to grasp why it made the willpower. We also needs to double verify the reasoning towards its go/fail judgement to make sure they’re logically constant. For extra element about LLM reasoning in circumstances like this, we suggest this glorious article.
You might be an knowledgeable healthcare skilled who's requested to judge a abstract of a affected person's medical information that was made by an automatic system.
Please comply with these directions for evaluating the summaries
{detailed directions}
Now rigorously examine the next enter information and output response, giving your reasoning and a go/fail judgement within the specified output format
{information to be summarized}
{formatting directions}
To maintain the choose outputs as dependable as doable, its temperature setting must be as little as doable. To validate the choose, the SMEs have to see consultant examples of enter, output, choose determination and choose critique. This could ideally be a special set of examples than those they checked out for the metric design, and given the human effort concerned on this step it may be small.
The SMEs would possibly first give their very own go/fail assessments for every instance with out seeing the choose’s model. They need to then have the ability to see every thing and have the chance to change the mannequin’s critique to develop into extra aligned with their very own ideas. The outcomes can be utilized to make modifications to the LLM choose immediate and the method repeated till the alignment between the SME assessments and mannequin assessments stops enhancing, as time constraints enable. Alignment will be measured utilizing easy accuracy or statistical measures reminiscent of Cohen’s kappa. We’ve got discovered that together with related few-shot examples within the choose immediate sometimes helps with alignment, and there’s additionally work suggesting that including grading notes for every instance to be judged can be helpful.
We’ve got sometimes used spreadsheets for such a iteration, however extra refined instruments reminiscent of Databrick’s evaluation apps additionally exist and might be tailored for LLM choose immediate growth. With knowledgeable time in brief provide, LLM judges are essential in healthcare AI and as basis fashions develop into extra refined, their capability to face in for human specialists seems to be enhancing. OpenAI’s HealthBench work, for instance, discovered that physicians have been typically unable to enhance the responses generated by April 2025’s fashions and that when GPT4.1 is used as a grader on healthcare-related issues, its scores are very properly aligned with these of human specialists [4].

2.5 Iteration and monitoring
With our LLM judges in place, we’re lastly in place to begin iterating on our foremost system. To take action, we’ll systematically replace the prompts, regenerate the event set outputs, run the judges, compute the metrics and do a comparability between the brand new and outdated outcomes. That is an iterative course of with probably many cycles, which is why it advantages from tracing, immediate logging and experiment monitoring. The method of regenerating the event dataset outputs is described in part 2.1, and instruments like MLflow make it doable to trace and model the choose iterations too. We use Databricks Mosaic AI Agent Analysis, which supplies a framework for including customized Judges (each LLM and programmatic), along with a number of built-in ones with pre-defined prompts (we sometimes flip these off). In code, the core analysis instructions appear to be this
with mlflow.start_run(
run_name=run_name,
log_system_metrics=True,
description=run_description,
) as run:
# run the programmatic assessments
results_programmatic = mlflow.consider(
predictions="response",
information=df, # df accommodates the inputs, outputs and any related context, as a pandas dataframe
model_type="textual content",
extra_metrics=programmatic_metrics, # checklist of customized mlflow metrics, every with a perform describing how the metric is calculated
)
# run the llm choose with the extra metrics we configured
# be aware that right here we additionally embody a dataframe of few-shot examples to
# assist information the LLM choose.
results_llm = mlflow.consider(
information=df,
model_type="databricks-agent",
extra_metrics=agent_metrics, # agent metrics is an inventory of customized mlflow metrics, every with its personal immediate
evaluator_config={
"databricks-agent": {
"metrics": ["safety"], # solely preserve the “security” default choose
"examples_df": pd.DataFrame(agent_eval_examples),
}
},
)
# Additionally log the prompts (choose and foremost mannequin) and another helpful artifacts reminiscent of plots the outcomes together with the run
Below the hood, MLflow will challenge parallel calls to the choose fashions (packaged within the agent metrics checklist within the code above) and in addition name the programmatic metrics with related capabilities (within the programmatic metrics checklist), saving the outcomes and related artifacts to Unity Catalog and in addition offering a pleasant person interface with which to match metrics throughout experiments, view traces and skim the LLM choose critiques. It must be famous MLflow 3.0, launched simply after this was written, and has some tooling which will simplify the code above.
To id enhancements with highest ROI, we are able to revisit the event set segmentation into personas, functionalities and conditions described in part 2.1. We will evaluate the worth of the optimizing metric between segments and select to focus our immediate iterations on the one with the bottom scores, or with probably the most regarding edge circumstances. With our analysis loop in place, we are able to catch any unintended penalties of mannequin updates. Moreover, with monitoring we are able to reproduce outcomes and revert to earlier immediate variations if wanted.
2.6 When is it prepared for manufacturing?
In AI functions, and healthcare specifically, some failures are extra consequential than others. We by no means need our chatbot to assert that it’s a healthcare skilled, for instance. However it’s inevitable that our meal scanner will make errors figuring out elements in uploaded pictures — people are usually not significantly good at figuring out elements from a photograph, and so even human-level accuracy can comprise frequent errors. It’s due to this fact essential to work with the SMEs and product stakeholders to develop practical thresholds for the optimizing metrics, above which the event work will be declared profitable to allow migration into manufacturing. Some initiatives might fail at this stage as a result of it’s not doable to push the optimizing metrics above the agreed threshold with out compromising the satisificing metrics or due to useful resource constraints.
If the thresholds are very excessive then lacking them barely is perhaps acceptable due to unavoidable error or ambiguity within the LLM choose. For instance we initially set a ship requirement of 100% of our growth set well being report summaries to be graded as “precisely grounded.” We then discovered that the LLM-judge sometimes would quibble over statements like, “the affected person has recorded their blood stress on most days of the final week”, when the precise variety of days with recordings was 4. In our judgement, an affordable end-user wouldn’t discover this assertion troubling, regardless of the LLM-as-judge classifying it as a failure. Thorough handbook evaluation of failure circumstances is essential to establish whether or not the efficiency is definitely acceptable and/or whether or not additional iteration is required.
These go/no-go choices additionally align with the NIST AI Threat Administration Framework, which inspires context-driven danger thresholds and emphasizes traceability, validity, and stakeholder-aligned governance all through the AI lifecycle.
Even with a temperature of zero, LLM judges are non-deterministic. A dependable choose ought to give the identical willpower and roughly the identical critique each time it’s on a given instance. If this isn’t occurring, it means that the choose immediate must be improved. We discovered this challenge to be significantly problematic in chatbot testing with the AWS Analysis Framework, the place every dialog to be graded has a customized rubric and the LLM producing the enter conversations has some leeway on the precise wording of the “person messages”. We due to this fact wrote a easy script to run every take a look at a number of occasions and report the typical failure price. Assessments with failure at a price that isn’t 0 or 100% will be marked as unreliable and up to date till they develop into constant.This expertise highlights the constraints of LLM judges and automatic analysis extra broadly. It reinforces the significance of incorporating human evaluation and suggestions earlier than declaring a system prepared for manufacturing. Clear documentation of efficiency thresholds, take a look at outcomes, and evaluation choices helps transparency, accountability, and knowledgeable deployment.
Along with efficiency thresholds, it’s essential to evaluate the system towards identified safety vulnerabilities. The OWASP High 10 for LLM Purposes outlines frequent dangers reminiscent of immediate injection, insecure output dealing with, and over-reliance on LLMs in high-stakes choices, all of that are extremely related for healthcare use circumstances. Evaluating the system towards this steering will help mitigate downstream dangers because the product strikes into manufacturing.
3.0 Put up-deployment: Monitoring and classification
Shifting an LLM software from growth to deployment in a scalable, sustainable and reproducible approach is a fancy endeavor and the topic of wonderful “LLMOps” articles like this one. Having a course of like this, which operationalizes every stage of the info pipeline, may be very helpful for evaluation-driven growth as a result of it permits for brand new iterations to be shortly deployed. Nevertheless, on this part we’ll focus primarily on really use the logs generated by an LLM software working in manufacturing to grasp the way it’s performing and inform additional growth.
One main aim of monitoring is to validate that the analysis metrics outlined within the growth section behave equally with manufacturing information, which is basically a take a look at of the representativeness of the event dataset. This could first ideally be executed internally in a dogfooding or “bug bashing” train, with involvement from unrelated groups and SMEs. We will re-use the metric definitions and LLM judges in-built growth right here, working them on samples of manufacturing information at periodic intervals and sustaining a breakdown of the outcomes. For information safety at Nuna, all of that is executed inside Databricks, which permits us to reap the benefits of Unity Catalog for lineage monitoring and dashboarding instruments for simple visualization.
Monitoring on LLM-powered merchandise is a broad subject, and our focus right here is on how it may be used to finish the evaluation-driven growth loop in order that the fashions will be improved and adjusted for drift. Monitoring also needs to be used to trace broader “product success” metrics reminiscent of user-provided suggestions, person engagement, token utilization, and chatbot query decision. This glorious article accommodates extra particulars, and LLM judges can be deployed on this capability — they might undergo the identical growth course of described in part 2.4.
This strategy aligns with the NIST AI Threat Administration Framework (“AI RMF”), which emphasizes steady monitoring, measurement, and documentation to handle AI danger over time. In manufacturing, the place ambiguity and edge circumstances are extra frequent, automated analysis alone is commonly inadequate. Incorporating structured human suggestions, area experience, and clear decision-making is important for constructing reliable programs, particularly in high-stakes domains like healthcare. These practices assist the AI RMF’s core ideas of governability, validity, reliability, and transparency.

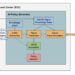
Determine 4: Excessive degree workflow displaying elements of the post-deployment information pipeline that permits for monitoring, alerting, tagging and analysis of the mannequin outputs in manufacturing. That is important for evaluation-driven growth, since insights will be fed again into the event stage. Picture generated by the writer.
3.1 Extra LLM classification
The idea of the LLM choose will be prolonged to post-deployment classification, assigning tags to mannequin outputs and giving insights about how functions are getting used “within the wild”, highlighting sudden interactions and alerting about regarding behaviors. Tagging is the method of assigning easy labels to information in order that they’re simpler to section and analyze. That is significantly helpful for chatbot functions: If customers on a sure Nuna app model begin asking our chatbot questions on our blood stress cuff, for instance, this will likely level to a cuff setup downside. Equally, if sure types of medicine container are resulting in larger than common failure charges from our medicine scanning software, this means the necessity to examine and perhaps replace that software.
In apply, LLM classification is itself a growth undertaking of the kind described in part 2. We have to construct a tag taxonomy (i.e. an outline of every tag that might be assigned) and prompts with directions about use it, then we have to use a growth set to validate tagging accuracy. Tagging usually entails producing constantly formatted output to be ingested by a downstream course of — for instance an inventory of subject ids for every chatbot dialog section — which is why implementing structured output on the LLM calls will be very useful right here, and Databricks has an instance of how that is will be executed at scale.
For lengthy chatbot transcripts, LLM classification will be tailored for summarization to enhance readability and defend privateness. Dialog summaries can then be vectorized, clustered and visualized to achieve an understanding of teams that naturally emerge from the info. That is usually step one in designing a subject classification taxonomy such because the one the Nuna makes use of to tag our chats. Anthropic has additionally constructed an inside software for related functions, which reveals fascinating insights into utilization patterns of Claude and is printed of their Clio analysis article.
Relying on the urgency of the knowledge, tagging can occur in actual time or as a batch course of. Tagging that appears for regarding conduct — for instance flagging chats for instant evaluation in the event that they describe violence, unlawful actions or extreme well being points — is perhaps finest suited to a real-time system the place notifications are despatched as quickly as conversations are tagged. Whereas extra basic summarization and classification can most likely afford to occur as a batch course of that updates a dashboard, and perhaps solely on a subset of the info to cut back prices. For chat classification, we discovered that together with an “different” tag for the LLM to assign to examples that don’t match neatly into the taxonomy may be very helpful. Knowledge tagged as “different” can then be examined in additional element for brand new matters so as to add to the taxonomy.
3.2 Updating the event set
Monitoring and tagging grant visibility into software efficiency, however they’re additionally a part of the suggestions loop that drives analysis pushed growth. As new or sudden examples are available and are tagged, they are often added to the event dataset, reviewed by the SMEs and run by means of the LLM judges. It’s doable that the choose prompts or few-shot examples might have to evolve to accommodate this new info, however the monitoring steps outlined in part 2.4 ought to allow progress with out the danger of complicated or unintended overwrites. This completes the suggestions loop of evaluation-driven growth and permits confidence in LLM merchandise not simply after they ship, but in addition as they evolve over time.
4.0 Abstract
The fast evolution of enormous language fashions (LLMs) is remodeling industries and presents nice potential to learn healthcare. Nevertheless, the non-deterministic nature of AI presents distinctive challenges, significantly in making certain reliability and security in healthcare functions.
At Nuna, Inc., we’re embracing evaluation-driven growth to handle these challenges and drive our strategy to AI merchandise. In abstract, the concept is to emphasise analysis and iteration all through the product lifecycle, from growth to deployment and monitoring.
Our methodology entails shut collaboration with subject material specialists to create consultant datasets and outline success standards. We concentrate on iterative enchancment by means of immediate engineering, supported by instruments like MLflow and Databricks, to trace and refine our fashions.
Put up-deployment, steady monitoring and LLM tagging present insights into real-world software efficiency, enabling us to adapt and enhance our programs over time. This suggestions loop is essential for sustaining excessive requirements and making certain AI merchandise proceed to align with our targets of enhancing lives and lowering value of care.
In abstract, evaluation-driven growth is important for constructing dependable, impactful AI options in healthcare and elsewhere. By sharing our insights and experiences, we hope to information others in navigating the complexities of LLM deployment and contribute to the broader aim of enhancing effectivity of AI undertaking growth in healthcare.
References
[1] Boston Consulting Group, Digital and AI Options to Reshape Well being Care (2025), https://www.bcg.com/publications/2025/digital-ai-solutions-reshape-health-care-2025
[2] Facilities for Illness Management and Prevention, Excessive Blood Strain Information (2022), https://www.cdc.gov/high-blood-pressure/data-research/facts-stats/index.html
[3] Facilities for Illness Management and Prevention, Diabetes Knowledge and Analysis (2022), https://www.cdc.gov/diabetes/php/data-research/index.html
[4] R.Okay. Arora, et al. HealthBench: Evaluating Giant Language Fashions In direction of Improved Human Well being (2025), OpenAI
Authorship
This text was written by Robert Martin-Quick, with contributions from the Nuna crew: Kate Niehaus, Michael Stephenson, Jacob Miller & Pat Alberts


{kind=link}