in vogue. DeepSeek-R1, Gemini-2.5-Professional, OpenAI’s O-series fashions, Anthropic’s Claude, Magistral, and Qwen3 — there’s a new one each month. While you ask these fashions a query, they go right into a chain of thought earlier than producing a solution.

I not too long ago requested myself the query, “Hmm… I’m wondering if I ought to write a Reinforcement Studying loop from scratch that teaches this ‘considering’ behaviour to actually small fashions — like solely 135 million parameters“. It needs to be simple, proper?
Nicely, it wasn’t.
Small fashions merely should not have the world data that enormous fashions do. This makes < 1B parameter mannequin lack the “widespread sense” to simply cause by means of complicated logical duties. Due to this fact, you can’t simply depend on compute to coach them to cause.
You want extra methods up your sleeve.
On this article, I gained’t simply cowl methods although. I’ll cowl the main concepts behind coaching reasoning behaviours into language fashions, share some easy code snippets, and a few sensible tricks to fine-tune Small Language Fashions (SLMs) with RL.
This text is split into 5 sections:
- Intro to RLVR (Reinforcement Studying with Verifiable Rewards) and why it’s uber cool
- A visible overview of the GRPO algorithm and the clipped surrogate PPO loss.
- A code walkthrough!
- Supervised fine-tuning and sensible tricks to practice reasoning fashions
- Outcomes!
Until in any other case talked about, all pictures used on this article are illustrations produced by the creator.
On the finish of this text, I’ll hyperlink to the 50-minute companion YouTube video of this text. You probably have any queries, that video probably has the solutions/clarification you want. You may also attain out to me on X (@neural_avb).
1. Reinforcement Studying with Verifiable Rewards (RLVR)
Earlier than diving into particular challenges with Small fashions, let’s first introduce some phrases.
Group Relative Coverage Optimization, or GRPO, is a (somewhat new) Reinforcement Studying (RL) method that researchers are utilizing to fine-tune Massive Language Fashions (LLMs) on logical and analytical duties. Since its inception, a brand new time period has been circulating within the LLM analysis house: RLVR, or Reinforcement Lincomes with Verifiable Rewards.
To grasp what makes RLVR distinctive, it’s useful to distinction it with the most typical software of RL in language fashions: RLHF (Reinforcement Lincomes with Human Feedback). In RLHF, an RL module is educated to maximise scores from a separate reward mannequin, which acts as a proxy for human preferences. This reward mannequin is educated on a dataset the place people have ranked or rated completely different mannequin responses.
In different phrases, RLHF is educated so LLMs can output responses which might be extra aligned with human preferences. It tries to make fashions observe directions extra carefully.
RLVR tries to unravel a distinct drawback. RLVR teaches a mannequin to be verifiably appropriate, usually by studying to generate it’s personal chain of thought.
The place RLHF had a subjective reward mannequin, RLVR makes use of an goal verifier. The core concept is to offer rewards primarily based on whether or not a solution is demonstrably appropriate, not on a prediction of what a human may favor.

That is precisely why this method is named ‘RL with verifiable rewards‘. Not each query’s reply may be verified simply. Particularly open-ended questions like “What iPhone ought to I purchase?” or “The place ought to I am going to school?”. Some use circumstances, nonetheless, do match simply within the “verifiable rewards” paradigm, like math, logical duties, and code-writing, to call a number of. Within the reasoning-gym part under, we’ll look into how precisely these duties may be simulated and the way the rewards may be generated.
However earlier than that, you may ask: effectively the place does “reasoning” match into all of this?
We are going to practice the LLM to generate arbitrarily lengthy chain of thought reasoning texts earlier than producing the ultimate reply. We instruct the mannequin to wrap its considering course of in
The complete language mannequin response will look one thing like this:
Consumer has requested me to depend the variety of r's in strawberry.
Let's do a cumulative depend.
s=0, t=0, r=1, a=0, w=0, b=0, e=0, r=2, r=3, y=4
It appears there are 3 r's in strawberry.
I discover that there's an r in straw and a couple of r's in berry.
Since 1+2=3 I'm extra assured there are 3 r's
3
This construction permits us to simply extract simply the ultimate reply and test if it’s appropriate. The verifier is a single supply of reality, and is usually a easy piece of code that (actually) counts alphabets.
def count_alphabets(phrase, letter):
return sum([1 for l in word if l == letter])
reward = 1 if (lm_answer == count_alphabets("strawberry", "r") else -1We are going to hold a report of the mannequin’s experiences — its responses and the corresponding rewards obtained from the verifier. The RL algorithm will then practice to advertise behaviours that improve the chance of appropriate last solutions.
By persistently rewarding appropriate solutions and good formatting, we’d improve the chance of reasoning tokens that result in appropriate solutions.
Get this: we don’t want to instantly consider the intermediate reasoning tokens. By merely rewarding the ultimate reply, we’ll not directly elicit reasoning steps into the LLM’s chain of thought that result in appropriate solutions!

2. GRPO (Group Relative Coverage Optimization)
I’m going to skip the same old Reinforcement Studying 101 intro right here, I count on most of you who learn this far to know the fundamentals of RL. There’s an agent who observes states from the setting and takes an motion — the setting rewards the agent relying on how good the motion was — the agent shops these experiences and trains to take higher actions sooner or later that result in increased rewards. RL 101 class dismissed.
However how will we switch the RL paradigm to language?
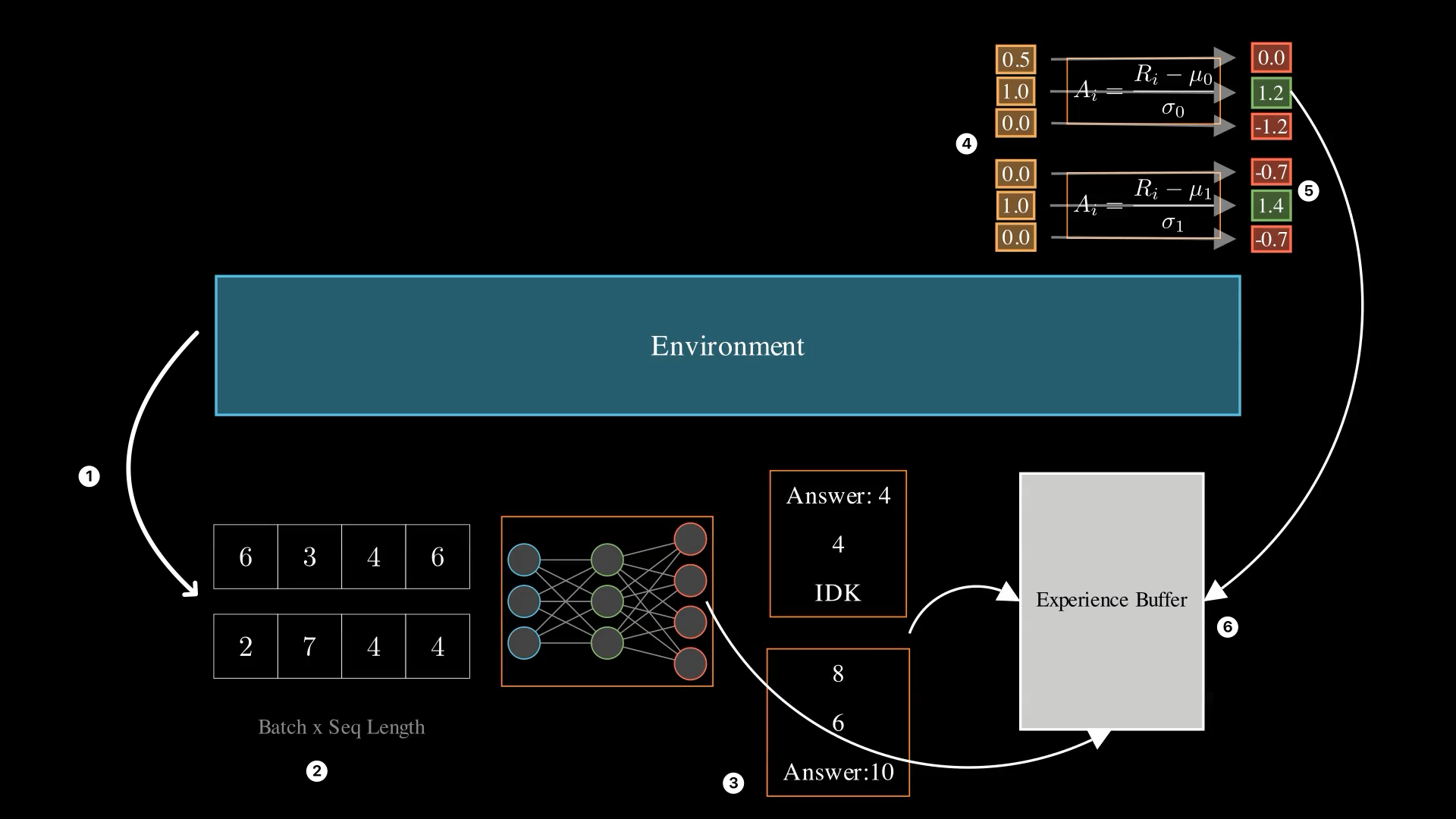
Let’s discuss our algorithm of selection — Group Relative Policy Optimization to know how. GRPO works in two iteratively self-repeating phases — an expertise assortment section the place the Language Mannequin (LM) accumulates experiences within the setting with its present weights. And a coaching section the place it makes use of the collected recollections to replace its weights to enhance. After coaching, it as soon as once more goes into an expertise assortment step with the up to date weights.
Expertise Assortment
Let’s dissect every step within the expertise assortment section now.
- Step 1: The setting is a black field that generates questions on logical or math duties. We are going to talk about this in an upcoming part with the
reasoning-gymlibrary.
- Step 2: We tokenize the enter questions right into a sequence of integer tokens.

- Step 3: The “agent” or the “coverage” is the present SLM we’re coaching. It observes the setting’s tokenized questions and generates responses. The LLM response will get transformed into textual content and returned to the setting. The setting rewards every response.

- Step 4: From the rewards, we calculate the benefit of every response. In GRPO, the benefit is the relative goodness of every response within the group. Importantly, benefits are calculated per group, i.e. we don’t standardize rewards throughout completely different questions.

(Illustrated by the Writer)
- Step 5: The unique query, the log chances for every LM-generated token, and the benefits are all amassed inside a reminiscence buffer.
- Steps 1-5 are repeated until the buffer measurement reaches the specified threshold.

Coaching Section
After the tip of the expertise assortment section, our aim is to enter the coaching section. Right here, we’ll be taught from the reward patterns the LLM noticed and use RL to enhance its weights. Right here is how that works:
- Randomly pattern a minibatch of recollections. Keep in mind, every reminiscence already contained its group-relative-advantage (Step 5 from the expertise assortment section). Randomly sampling question-answer pairs improves the robustness of the coaching because the gradients are calculated as a median of a various set of experiences, stopping over-fitting on any single query.
- For every minibatch, we need to maximize this time period following the usual PPO (Proximal Coverage Optimization) formulation. The key distinction with GRPO is that we don’t want an extra reward mannequin or a worth community to calculate benefits. As an alternative, GRPO samples a number of responses to the identical query to calculate the relative benefit of every response. The reminiscence footprint is considerably lowered since we gained’t want to coach these extra fashions!
- Repeat the above steps.

What the PPO Loss means
Let me clarify the PPO Loss in an intuitive step-by-step vogue. The PPO Loss appears to be like like this.

- Right here,
pi_oldis the old-policy neural community that we used throughout the information assortment section.
πis the present coverage neural community we’re coaching. Because the weights ofπchange after every gradient replace,πandπ_olddo not stay the identical throughout the coaching section — therefore the excellence.
Gis the variety of generated responses for a single query.|o_i|is the size of the i-th response within the group. Due to this fact, these summation and normalization operation computes a imply over all of the tokens over all responses. What does it compute the imply of? Nicely it’sπ/π_old * A_{it}. What does that imply?

A_itis the benefit of the t-th token within the i-th response. Keep in mind once we calculated the benefit of every response in Step 5 throughout expertise assortment? The best approach to assign a bonus to every token is by merely duplicating the identical benefit to every token — this implies we’re saying that each token is equally liable for producing the proper reply.
- Lastly, what’s
π(o_it | q, o_i < t)? It means what’s the likelihood of thet-thtoken within thei-thresponse? Which means, how probably was that token when it was generated? - The significance sampling ratio reweights the benefits between the present updating coverage and the previous exploration coverage.
- The clipping time period ensures that the updates to the community don’t develop into too massive and the weights don’t transfer too distant from the previous coverage. This provides extra stability to the coaching course of by preserving the mannequin updates near “a belief area” from the data-collection coverage.

After we are maximizing the PPO goal, we’re successfully asking the LLM to improve the log-probability of the tokens that led to a excessive benefit, whereas reducing the log-probability of tokens that had a low benefit.
In different phrases: make tokens that generate good benefits extra probably and tokens that generate low benefits much less probably.
Understanding the PPO Loss with an instance
Let’s overlook concerning the clipping time period and the π_old for now, and let’s simply see what maximizing 𝜋(𝑜_i) * A_i means. To remind you, this a part of the equation merely means, “the product of the likelihood of the i-th token (o_i) and the benefit of the i-th token (A_i)
Let’s say for a query, the LLM generated these two sequences: “A B C” and “D E F”, and it obtained a bonus of +1 for the previous and -1 for the latter*. Let’s say we’ve the log chances for every of the three tokens as proven under.
* really since group-relative benefits at all times have a regular deviation of 1, the proper benefits needs to be +0.707 and -0.707.
Discover what occurs once you multiply the benefits A_it by the present logprobs pi. Now actually take into consideration what it means to maximise the imply of that product matrix.

Keep in mind we will solely change the chances popping out of the LLM. The benefits come from the setting and are subsequently handled as constants. Growing this anticipated rating would subsequently imply growing the likelihood of tokens with a constructive benefit, and reducing the worth of the unfavorable benefit instance.

(Illustrated by the Writer)
Beneath, you can see an instance of how log-probs change after a number of rounds of coaching. Discover how the blue line is shifting nearer to zero when the benefit is excessive? This means that the log-probabilities elevated (or the chances elevated) after going by means of RL Coaching. Examine that to the plot on the fitting, which exhibits a distinct response with a low benefit. The blue line is shifting away from 0, changing into much less possible for choice in later rounds.

Within the subsequent part, let’s check out the reasoning-gym library and perceive how we might pattern duties.
3. Implementation
So, to do RL, we first want duties. A typical manner to do that is by utilizing an current dataset of math issues, just like the GSM-8K dataset. On this article, let’s take a look at a distinct case — producing duties procedurally with a Python library referred to as reasoning-gym.
For my experiments, I used two duties: syllogism and propositional logic. reasoning-gym accommodates a number of various repositories of various problem.
A syllogism process is a kind of logical puzzle designed to check deductive reasoning. Principally, we’ll present the LLM with two premises and ask if the conclusion is appropriate or not. The propositional logic process is a symbolic reasoning process the place the LLM is offered duties with symbols and requested to generate the conclusion. In contrast to syllogism, this isn’t a YES/NO classification response — they must generate the proper conclusion instantly. This makes this process significantly tougher.

Earlier than we start coding, I assume it’s customary to specify what I imply by “small” fashions.
The jury remains to be out on what qualifies as a “small” mannequin (some say <14B, some say <7B), however for my YouTube video, I picked even smaller fashions: SmolLM-135M-Instruct, SmolLM-360M-Instruct, and Qwen3-0.6B. These are ~135M, ~360M, and ~600M fashions, respectively.
Let’s see methods to arrange the essential coaching loop. First, we will use Huggingface’s transformers library to load in a mannequin we need to practice, let’s say the little 135M param mannequin SmolLM-135M-Instruct.
To generate some propositional logic duties, for instance, you simply name this reasoning_gym.create_dataset perform as proven under.
import re
from reasoning_gym import create_dataset, get_score_answer_fn
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
model_name = "HuggingfaceTB/SmolLM-135M-Instruct"
# load mannequin from huggingface
lm = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype=torch.bfloat16)
tokenizer = AutoTokenizer.from_pretrained(model_name)
# This units all fashions as trainable
for param in lm.parameters():
param.requires_grad = True
# In my experiments, I used a LORA adapter (extra on this later)
# specify title of the env
environment_name = "propositional_logic"
# In apply, you need to wrap this with a torch dataloader
# to pattern a minibatch of questions
dataset = create_dataset(
environment_name, seed=42, measurement=DATA_SIZE
)
for d in dataset:
query = d["question"] # Accessing the query
# We are going to use this later to confirm if reply is appropriate
validation_object = d["metadata"]["source_dataset"]
score_fn = get_score_answer_fn(validation_object)
To generate reasoning information, we wish the LM to generate considering, adopted by the response. Beneath is the system immediate we can be utilizing.
system_prompt = """A dialog between Consumer and Assistant. The consumer asks a query, and the Assistant solves it.
The assistant first thinks concerning the reasoning course of within the thoughts after which offers the consumer
with the reply. The reasoning course of and reply are enclosed inside and
tags, respectively, i.e., reasoning course of right here
reply right here .
Don't generate new code. Don't write python code.
You may additionally be given examples by the consumer telling you the anticipated response format.
Observe the format of the examples, however remedy the precise drawback requested by the consumer, not the examples.
Crucial - Keep in mind once more, your output format needs to be:
reasoning course of right here
reply right here
Your response can be scored by extracting the substring between the ... tags.
It's essential to observe the above format.
feature_extraction_utilsling to observe the response format will lead to a penalty.
"""To generate solutions, we first tokenize the system immediate and the query as proven under.
# Create messages construction
messages = [
{"role": "system", "content": system_prompt},
{"role": "user", "content": question}, # Obtained from reasoning-gym
]
# Create tokenized illustration
inputs = tokenizer.apply_chat_template(
messages,
tokenize=True,
return_tensors="pt",
add_generation_prompt=True
)Then we go it by means of the LM — generate a number of responses utilizing the num_return_sequences parameter, and detokenize it again to get a string response. No gradients are calculated throughout this stage.
generated_response = lm.generate(
input_ids=inputs["input_ids"],
attention_mask=inputs["attention_mask"],
max_new_tokens=max_new_tokens, # The max variety of tokens to generate
do_sample=True, # Probabilistic sampling
top_p=0.95, # Nucleus sampling
num_return_sequences=G, # Variety of sequences per query
temperature=1, # Enhance randomness
eos_token_id=eos_token_id,
pad_token_id=eos_token_id,
)
We additionally write the extract_answer perform, which makes use of common expressions to extract solutions between the reply tags.
def extract_answer(response):
reply = re.search(r"(.*?) ", response, re.DOTALL)
if reply will not be None:
return reply.group(1).strip()
else:
return ""
Lastly, we use the rating perform we obtained beforehand to generate a reward relying on whether or not the LM’s response was appropriate. To calculate rewards, we add a format reward and a correction reward. The correction reward comes from the setting, and the format reward is awarded if the mannequin accurately generates the
The benefits are calculated by standardizing throughout every group.
# Response is an array of string of size [B*G]
# B is the variety of questions, G is the variety of responses per query
correctness_reward = score_fn(response, validation_object)
format_reward = calculate_format_reward(response)
# Whole reward is a weighted sum of correctness and formatting rewards
reward = correctness_reward * 0.85 + format_reward * 0.15
# Convert rewards from [B*G, 1] -> [B, G]
rewards = rewards.reshape(B, G)
# Calculate benefits
benefits = (rewards - np.imply(rewards, axis=1, keepdims=True)) / (
np.std(rewards, axis=1, keepdims=True) + 1e-8
)
benefits = benefits.reshape(-1, 1)
Retailer the (previous) log probs, benefits, responses, and response masks in a reminiscence buffer.
# A perform that returns the log prob of every chosen token
log_probs = calculate_log_probs(lm, generated_response)
buffer.prolong([{
"full_response": generated_response[i],
"response_mask": response_mask[i], # A binary masks to indicate which tokens in generated response are AI generated, 0 for system immediate and questions
"old_log_probs": log_probs[i],
"benefits": benefits[i]
} for i in vary(len(generated_response))])After a number of expertise assortment step, as soon as the buffer is full, we provoke our coaching loop. Right here, we pattern minibatches from our expertise, calculate the log probs, compute loss, and backdrop.
# full_response, response_mask, old_log_probs, benefits <--- Buffer
# Recompute the brand new log_probs. Discover no torch.no_grad(), so gradients WILL BE USED right here.
logits = llm(input_ids=full_response).logits
# Extract log probs from the logits
# Does log_softmax over the vocabulary and extracts the log-prob of every chosen token
log_probs = calculate_log_probs(
logits,
full_responses
)
# Calculate the clipped surrogate loss
reasoning_loss = calculate_ppo_loss(
log_probs, # Trainable
old_log_probs, # Obtained from exploration, not trainable
benefits, # Obtained from setting, not trainable
response_mask # Obtained from exploration, not trainable
)
# Optimizaiton steps
accelerator.backward(reasoning_loss)
optimizer.step()
optimizer.zero_grad()
You should use extra entropy losses right here, or decrease KLD along with your reference mannequin as advised within the authentic Deepseek-R1 paper, however future papers have concluded that these leash the coaching course of and never a requirement.
4. Warming up with Supervised High-quality-tuning
Technically, we will attempt to run a giant RL coaching proper now and hope that the small fashions can pull by means of and conquer our duties. Nevertheless, the likelihood of that’s extremely low.
There’s one large drawback — our small fashions will not be appropriately educated to generate formatted outputs or carry out effectively on these duties. Off the field, their responses do have some logical movement to them, because of the pretraining or instruction tuning from their authentic builders, however they aren’t adequate for our goal process.

Give it some thought — RL trains by amassing experiences and updating the coverage to maximise the nice experiences. But when a lot of the experiences are fully unhealthy and the mannequin receives 0 rewards, it has no approach to optimize, as a result of it will get no sign to enhance in any respect. So the advisable method is to first train the mannequin the conduct you need to practice utilizing supervised fine-tuning. Right here is a straightforward script:
shopper = openai.AsyncClient()
ENVIRONMENT = "propositional_logic"
mannequin = "gpt-4.1-mini"
semaphore = asyncio.Semaphore(50)
num_datapoints = 200
system_prompt = (
system_prompt
+ """Additionally, you will be offered the true reply. Your considering ought to finally lead to producing the true reply."""
)
dataloader = create_dataset(title=ENVIRONMENT, measurement=num_datapoints)
@backoff.on_exception(backoff.expo, openai.RateLimitError)
async def generate_response(merchandise):
async with semaphore:
messages = [
{"role": "system", "content": system_prompt},
{
"role": "user",
"content": f"""
Question: {item['question']}
Metadata: {merchandise['metadata']}
Reply: {merchandise['answer']}
""",
},
]
response = await shopper.chat.completions.create(messages=messages, mannequin=mannequin)
return {
"query": merchandise["question"],
"metadata": merchandise["metadata"],
"reply": merchandise["answer"],
"response": response.selections[0].message.content material,
}
async def fundamental():
responses = await asyncio.collect(*[generate_response(item) for item in dataloader])
fname = f"responses_{ENVIRONMENT}_{mannequin}.json"
json.dump(responses, open(fname, "w"), indent=4)
print(f"Saved responses to {fname}")
if __name__ == "__main__":
asyncio.run(fundamental())To generate the fine-tuning dataset, I first generated the considering and reply tags with a small LLM-like GPT-4.1-mini. Doing that is extremely easy — we pattern 200 or so examples for every process, name the OpenAI API to generate a response, and reserve it on disk.
Throughout SFT, we load the bottom mannequin we need to practice, connect a trainable LORA adapter ,and do parameter-efficient fine-tuning. Listed here are the LORA configurations I used.
lora:
r: 32
lora_alpha: 64
lora_dropout: 0
target_modules: ["q_proj", "v_proj", "k_proj", "o_proj",
"up_proj", "down_proj", "gate_proj"] LORA permits the coaching course of to be extra reminiscence environment friendly and likewise reduces the chance of corrupting the unique mannequin. You’ll find the small print of parameter-efficient supervised fine-tuning in my YouTube video proper right here.
I educated a LORA adapter on 200 examples of syllogism information with the smallest language mannequin I might discover — the HuggingfaceTB/SmolLM-135M-Instruct, and it obtained us an accuracy of 46%. Roughly, because of this we generate an accurate reply 46% of the time. Extra importantly, we regularly get the formatting proper, so our regex can safely extract solutions from the responses most of the time.
Some extra optimizations for SLMs and sensible concerns
- Not all reasoning duties may be solved by all fashions. A simple approach to confirm if a process is just too arduous or too simple for the mannequin is to simply test the bottom accuracy of the mannequin in your process. Whether it is, let’s say under 10-20%, the duty is probably going very arduous and also you want extra supervised warmup fine-tuning.
- SFT, even on small datasets, can typically present huge accuracy good points on small fashions. In case you can purchase a superb dataset, chances are you’ll not even must do Reinforcement Studying in lots of eventualities. SLMs are immensely tunable.
- Papers like DAPO and Crucial Views on R1 have claimed that the unique loss normalization from DeepSeek has a size bias. They’ve proposed different normalization strategies which might be price taking a look at. For my venture, the common DeepSeek loss simply labored.
- DAPO additionally mentions eradicating the KLD time period within the authentic R1 paper. Initially, the aim of this loss was to make sure that the updating coverage isn’t too distant from the bottom coverage, however DAPO suggests not utilizing this as a result of the behaviour of the coverage can drastically change throughout reasoning, making this KLD time period an pointless regularisation time period that may prohibit the mannequin’s intelligence.
- Producing various responses IS KEY to creating RL doable. In case you solely generated appropriate responses, or should you solely generated incorrect responses, the benefit can be 0, and this may give the RL algorithm no coaching sign in any respect. We are able to generate various responses by growing the
temperature,top_p, andnum_return_sequencesparameters within thegenerate(). - You may also generate various rewards, by including extra phrases into the reward perform. For instance, a size reward that penalizes overly lengthy reasoning.
- The next parameters improve the stability of coaching at the price of extra computation: growing num generations per rollout, growing the scale of the buffer and decreasing the training price.
- Use gradient accumulation (and even gradient checkpointing) in case you have restricted assets to coach these fashions.
- There’s some positive print I skipped on this article associated to padding. When saving experiences into buffer, it’s greatest apply to take away the pad tokens altogether — and recreate them when loading a minibatch throughout coaching.
- It’s best to go away whitespace round
and (and their closing tags). This ends in constant tokenization and makes coaching barely simpler for the SLMs.
4. Outcomes
Right here is my YouTube video that explains all the pieces on this weblog put up extra pictorially and offers a hands-on tutorial on methods to code such a factor.
On the supervised-fine-tuned SmolLM-135M on the syllogism process, we obtained a bump to 60%! You’ll be able to see the reward curve right here — the wholesome normal deviation of the rewards exhibits that we have been certainly getting various responses all through, which is a wholesome factor if we need to practice with RL.

Here’s a set of hyperparameters that labored effectively for me.
config:
title: "path/to/sft_model"
max_new_tokens: 300 # reasoning + reply token finances
exploration_batchsize: 8 # variety of questions per batch throughout rollout
G: 6 # num responses per group
temperature: 0.7
batch_size: 16 # minibatch measurement throughout coaching
gradient_accumulation_steps: 12
learning_rate: 0.000001 # Advisable to maintain this low, like 1e-6 or 1e-7
top_p: 0.95
buffer_size: 500
I additionally repeated this experiment with bigger fashions — the SmolLM-360M-Instruct and the Qwen3-0.6B mannequin. Within the latter, I used to be capable of get accuracies as much as 81% which is superior! We obtained a 20% additive bump on common within the syllogism process!
Within the propositional logic process, which for my part is a tougher reasoning process, I additionally noticed comparable good points throughout all small fashions! I’m positive that with extra instruction tuning and RL fine-tuning, probably on a number of duties without delay, we will elevate the intelligence of those fashions rather a lot increased. Coaching on a single process can generate fast outcomes which is what I needed for this Youtube video, however it may additionally act as a bottleneck for the mannequin’s general intelligence.
Let’s finish this text with a GIF of the small fashions outputting reasoning information and fixing duties. Get pleasure from, and keep magnificent!

References
Writer’s YouTube channel: https://www.youtube.com/@avb_fj
Writer’s Patreon: www.patreon.com/NeuralBreakdownwithAVB
Writer’s Twitter (X) account: https://x.com/neural_avb
Deepseek Math: https://arxiv.org/pdf/2402.03300
DeepSeek R1: https://arxiv.org/abs/2501.12948
DAPO: https://arxiv.org/abs/2503.14476
Crucial Views on R1: https://arxiv.org/abs/2503.20783
Reasoning Gymnasium Library: github.com/open-thought/reasoning-gym
place to examine Reasoning: https://github.com/willccbb/verifiers
An excellent place to review code: https://github.com/huggingface/trl/blob/fundamental/trl/coach/grpo_trainer.py



{kind=link}