This put up is cowritten with John Gilhuly from Arize AI.
With Amazon Bedrock Brokers, you may construct and configure autonomous brokers in your utility. An agent helps your end-users full actions primarily based on group information and person enter. Brokers orchestrate interactions between basis fashions (FMs), information sources, software program functions, and person conversations. As well as, brokers robotically name APIs to take actions and invoke information bases to complement info for these actions. By integrating brokers, you may speed up your improvement effort to ship generative AI functions. With brokers, you may automate duties in your prospects and reply questions for them. For instance, you may create an agent that helps prospects course of insurance coverage claims or make journey reservations. You don’t need to provision capability, handle infrastructure, or write customized code. Amazon Bedrock manages immediate engineering, reminiscence, monitoring, encryption, person permissions, and API invocation.
AI brokers characterize a elementary shift in how functions make selections and work together with customers. In contrast to conventional software program programs that comply with predetermined paths, AI brokers make use of advanced reasoning that always operates as a “black field.” Monitoring AI brokers presents distinctive challenges for organizations looking for to take care of reliability, effectivity, and optimum efficiency of their AI implementations.
Right now, we’re excited to announce a brand new integration between Arize AI and Amazon Bedrock Brokers that addresses one of the crucial vital challenges in AI improvement: observability. Agent observability is an important facet of AI operations that gives deep insights into how your Amazon Bedrock brokers carry out, work together, and execute duties. It entails monitoring and analyzing hierarchical traces of agent actions, from high-level person requests all the way down to particular person API calls and gear invocations. These traces type a structured tree of occasions, serving to builders perceive the entire journey of person interactions by way of the agent’s decision-making course of. Key metrics that demand consideration embody response latency, token utilization, runtime exceptions, and examine operate calling. As organizations scale their AI implementations from proof of idea to manufacturing, understanding and monitoring AI agent habits turns into more and more crucial.
The mixing between Arize AI and Amazon Bedrock Brokers offers builders with complete observability instruments for tracing, evaluating, and monitoring AI agent functions. This resolution delivers three main advantages:
- Complete traceability – Achieve visibility into each step of your agent’s execution path, from preliminary person question by way of information retrieval and motion execution
- Systematic analysis framework – Apply constant analysis methodologies to measure and perceive agent efficiency
- Information-driven optimization – Run structured experiments to check completely different agent configurations and establish optimum settings
The Arize AI service is accessible in two variations:
- Arize AX – An enterprise resolution providing superior monitoring capabilities
- Arize Phoenix – An open supply service making tracing and analysis accessible to builders
On this put up, we reveal the Arize Phoenix system for tracing and analysis. Phoenix can run in your native machine, a Jupyter pocket book, a containerized deployment, or within the cloud. We discover how this integration works, its key options, and how one can implement it in your Amazon Bedrock Brokers functions to reinforce observability and preserve production-grade reliability.
Answer overview
Massive language mannequin (LLM) tracing information the paths taken by requests as they propagate by way of a number of steps or parts of an LLM utility. It improves the visibility of your utility or system’s well being and makes it doable to debug habits that’s troublesome to breed regionally. For instance, when a person interacts with an LLM utility, tracing can seize the sequence of operations, comparable to doc retrieval, embedding era, language mannequin invocation, and response era, to offer an in depth timeline of the request’s execution.
For an utility to emit traces for evaluation, the applying should be instrumented. Your utility will be manually instrumented or be robotically instrumented. Arize Phoenix gives a set of plugins (instrumentors) that you may add to your utility’s startup course of that carry out automated instrumentation. These plugins acquire traces in your utility and export them (utilizing an exporter) for assortment and visualization. The Phoenix server is a collector and UI that helps you troubleshoot your utility in actual time. Whenever you run Phoenix (for instance, the px.launch_app() container), Phoenix begins receiving traces from an utility that’s exporting traces to it. For Phoenix, the instrumentors are managed by way of a single repository known as OpenInference. OpenInference offers a set of instrumentations for fashionable machine studying (ML) SDKs and frameworks in a wide range of languages. It’s a set of conventions and plugins that’s complimentary to OpenTelemetry and on-line transaction processing (OLTP) to allow tracing of AI functions. Phoenix at the moment helps OTLP over HTTP.
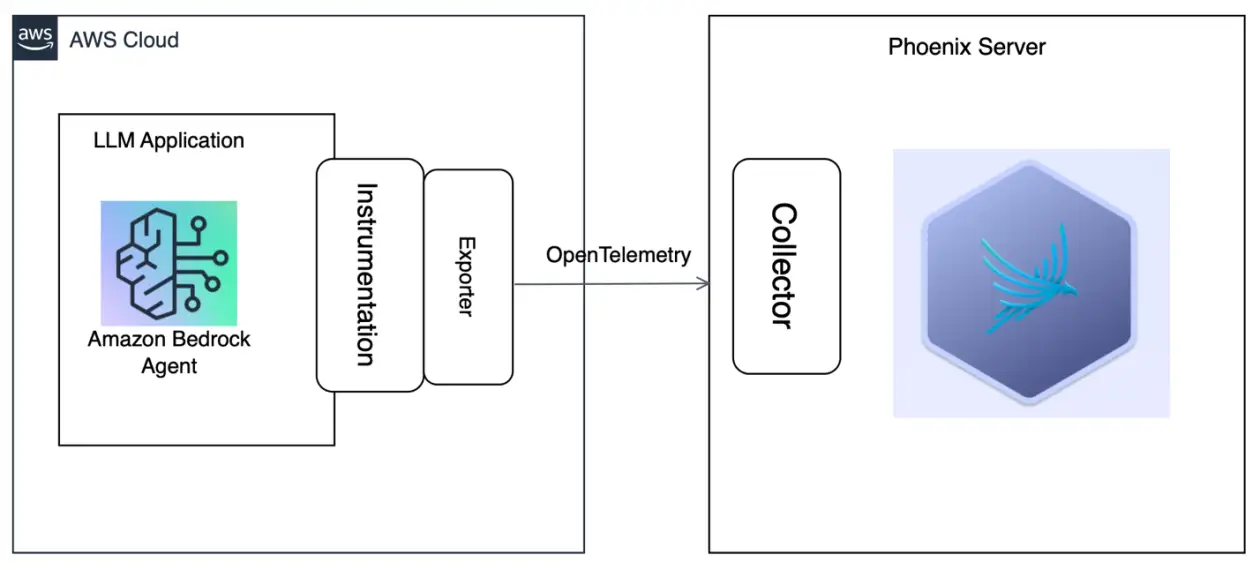
For AWS, Boto3 offers Python bindings to AWS companies, together with Amazon Bedrock, which offers entry to quite a lot of FMs. You’ll be able to instrument calls to those fashions utilizing OpenInference, enabling OpenTelemetry-aligned observability of functions constructed utilizing these fashions. You too can seize traces on invocations of Amazon Bedrock brokers utilizing OpenInference and look at them in Phoenix.The next high-level structure diagram exhibits an LLM utility created utilizing Amazon Bedrock Brokers, which has been instrumented to ship traces to the Phoenix server.

Within the following sections, we reveal how, by putting in the openinference-instrumentation-bedrock library, you may robotically instrument interactions with Amazon Bedrock or Amazon Bedrock brokers for observability, analysis, and troubleshooting functions in Phoenix.
Stipulations
To comply with this tutorial, you should have the next:
You too can clone the GitHub repo regionally to run the Jupyter pocket book your self:
git clone https://github.com/awslabs/amazon-bedrock-agent-samples.git
Set up required dependencies
Start by putting in the required libraries:
%pip set up -r necessities.txt — quiet
Subsequent, import the required modules:
The arize-phoenix-otel bundle offers a light-weight wrapper round OpenTelemetry primitives with Phoenix-aware defaults. These defaults are conscious of surroundings variables you should set to configure Phoenix within the subsequent steps, comparable to:
PHOENIX_COLLECTOR_ENDPOINTPHOENIX_PROJECT_NAMEPHOENIX_CLIENT_HEADERSPHOENIX_API_KEY
Configure the Phoenix surroundings
Arrange the Phoenix Cloud surroundings for this tutorial. Phoenix may also be self-hosted on AWS as an alternative.
Join your pocket book to Phoenix with auto-instrumentation enabled:
The auto_instrument parameter robotically locates the openinference-instrumentation-bedrock library and devices Amazon Bedrock and Amazon Bedrock Agent calls with out requiring extra configuration. Configure metadata for the span:
Arrange an Amazon Bedrock session and agent
Earlier than utilizing Amazon Bedrock, be sure that your AWS credentials are configured appropriately. You’ll be able to set them up utilizing the AWS Command Line Interface (AWS CLI) or by setting surroundings variables:
We assume you’ve already created an Amazon Bedrock agent. To configure the agent, use the next code:
Earlier than continuing to the next step, you may validate whether or not invoke agent is working appropriately. The response shouldn’t be essential; we’re merely testing the API name.
Run your agent with tracing enabled
Create a operate to run your agent and seize its output:
Check your agent with a number of pattern queries:
You need to change these queries with the queries that your utility is constructed for. After executing these instructions, it is best to see your agent’s responses within the pocket book output. The Phoenix instrumentation is robotically capturing detailed traces of those interactions, together with information base lookups, orchestration steps, and gear calls.
View captured traces in Phoenix
Navigate to your Phoenix dashboard to view the captured traces. You will notice a complete visualization of every agent invocation, together with:
- The total dialog context
- Data base queries and outcomes
- Software or motion group calls and responses
- Agent reasoning and decision-making steps
Phoenix’s tracing and span evaluation capabilities are helpful throughout the prototyping and debugging levels. By instrumenting utility code with Phoenix, groups achieve detailed insights into the execution circulate, making it easy to establish and resolve points. Builders can drill down into particular spans, analyze efficiency metrics, and entry related logs and metadata to streamline debugging efforts. With Phoenix’s tracing capabilities, you may monitor the next:
- Utility latency – Determine latency bottlenecks and handle sluggish invocations of LLMs, retrievers, and different parts inside your utility, enabling you to optimize efficiency and responsiveness.
- Token utilization – Achieve an in depth breakdown of token utilization in your LLM calls, so you may establish and optimize the most costly LLM invocations.
- Runtime exceptions – Seize and examine crucial runtime exceptions, comparable to rate-limiting occasions, that may show you how to proactively handle and mitigate potential points.
- Retrieved paperwork – Examine the paperwork retrieved throughout a retriever name, together with the rating and order by which they have been returned, to offer perception into the retrieval course of.
- Embeddings – Look at the embedding textual content used for retrieval and the underlying embedding mannequin, so you may validate and refine your embedding methods.
- LLM parameters – Examine the parameters used when calling an LLM, comparable to temperature and system prompts, to facilitate optimum configuration and debugging.
- Immediate templates – Perceive the immediate templates used throughout the prompting step and the variables that have been utilized, so you may fine-tune and enhance your prompting methods.
- Software descriptions – View the descriptions and performance signatures of the instruments your LLM has been given entry to, in an effort to higher perceive and management your LLM’s capabilities.
- LLM operate calls – For LLMs with operate name capabilities (comparable to Anthropic’s Claude, Amazon Nova, or Meta’s Llama), you may examine the operate choice and performance messages within the enter to the LLM. This will additional show you how to debug and optimize your utility.
The next screenshot exhibits the Phoenix dashboard for the Amazon Bedrock agent, displaying the latency, token utilization, whole traces.

You’ll be able to select one of many traces to drill all the way down to the extent of the complete orchestration.

Consider the agent in Phoenix
Evaluating any AI utility is a problem. Evaluating an agent is much more troublesome. Brokers current a novel set of analysis pitfalls to navigate. A standard analysis metric for brokers is their operate calling accuracy, in different phrases, how properly they do at choosing the proper software for the job. For instance, brokers can take inefficient paths and nonetheless get to the appropriate resolution. How are you aware in the event that they took an optimum path? Moreover, unhealthy responses upstream can result in unusual responses downstream. How do you pinpoint the place an issue originated? Phoenix additionally consists of built-in LLM evaluations and code-based experiment testing. An agent is characterised by what it is aware of in regards to the world, the set of actions it might probably carry out, and the pathway it took to get there. To judge an agent, you should consider every element. Phoenix has constructed analysis templates for each step, comparable to:
You’ll be able to consider the person abilities and response utilizing regular LLM analysis methods, comparable to retrieval analysis, classification with LLM judges, hallucination, or Q&A correctness. On this put up, we reveal analysis of agent operate calling. You should use the Agent Perform Name eval to find out how properly a mannequin selects a software to make use of, extracts the appropriate parameters from the person question, and generates the software name code. Now that you simply’ve traced your agent within the earlier step, the subsequent step is so as to add evaluations to measure its efficiency. A standard analysis metric for brokers is their operate calling accuracy (how properly they do at choosing the proper software for the job).Full the next steps:
- Up till now, you may have simply used the lighter-weight Phoenix OTEL tracing library. To run evals, you should to put in the complete library:
!pip set up -q arize-phoenix — quiet
- Import the required analysis parts:
The next is our agent operate calling immediate template:
- As a result of we’re solely evaluating the inputs, outputs, and performance name columns, let’s extract these right into a simpler-to-use dataframe. Phoenix offers a technique to question your span information and instantly export solely the values you care about:
- The subsequent step is to arrange these traces right into a dataframe with columns for enter, software name, and gear definitions. Parse the JSON enter and output information to create these columns:
- Apply the operate to every row of
trace_df.output.worth:
- Add software definitions for analysis:
Now together with your dataframe ready, you need to use Phoenix’s built-in LLM-as-a-Choose template for software calling to guage your utility. The next technique takes within the dataframe of traces to guage, our built-in analysis immediate, the eval mannequin to make use of, and a rails object to snap responses from our mannequin to a set of binary classification responses. We additionally instruct our mannequin to offer explanations for its responses.
- Run the software calling analysis:
We use the next parameters:
- df – A dataframe of instances to guage. The dataframe should have columns to match the default template.
- query – The question made to the mannequin. For those who exported spans from Phoenix to guage, this would be the
llm.input_messagescolumn in your exported information. - tool_call – Data on the software known as and parameters included. For those who exported spans from Phoenix to guage, this would be the
llm.function_callcolumn in your exported information.
- Lastly, log the analysis outcomes to Phoenix:
After working these instructions, you will notice your analysis outcomes on the Phoenix dashboard, offering insights into how successfully your agent is utilizing its out there instruments.
The next screenshot exhibits how the software calling analysis attribute exhibits up while you run the analysis.

Whenever you broaden the person hint, you may observe that the software calling analysis provides a rating of 1 if the label is appropriate. Which means agent has responded appropriately.

Conclusion
As AI brokers grow to be more and more prevalent in enterprise functions, efficient observability is essential for facilitating their reliability, efficiency, and steady enchancment. The mixing of Arize AI with Amazon Bedrock Brokers offers builders with the instruments they should construct, monitor, and improve AI agent functions with confidence. We’re excited to see how this integration will empower builders and organizations to push the boundaries of what’s doable with AI brokers.
Keep tuned for extra updates and enhancements to this integration within the coming months. To study extra about Amazon Bedrock Brokers and the Arize AI integration, confer with the Phoenix documentation and Integrating Arize AI and Amazon Bedrock Brokers: A Complete Information to Tracing, Analysis, and Monitoring.
In regards to the Authors
 Ishan Singh is a Sr. Generative AI Information Scientist at Amazon Internet Providers, the place he helps prospects construct revolutionary and accountable generative AI options and merchandise. With a powerful background in AI/ML, Ishan focuses on constructing generative AI options that drive enterprise worth. Outdoors of labor, he enjoys enjoying volleyball, exploring native bike trails, and spending time together with his spouse and canine, Beau.
Ishan Singh is a Sr. Generative AI Information Scientist at Amazon Internet Providers, the place he helps prospects construct revolutionary and accountable generative AI options and merchandise. With a powerful background in AI/ML, Ishan focuses on constructing generative AI options that drive enterprise worth. Outdoors of labor, he enjoys enjoying volleyball, exploring native bike trails, and spending time together with his spouse and canine, Beau.
 John Gilhuly is the Head of Developer Relations at Arize AI, centered on AI agent observability and analysis tooling. He holds an MBA from Stanford and a B.S. in C.S. from Duke. Previous to becoming a member of Arize, John led GTM actions at Slingshot AI, and served as a enterprise fellow at Omega Enterprise Companions. In his pre-AI life, John constructed out and ran technical go-to-market groups at Department Metrics.
John Gilhuly is the Head of Developer Relations at Arize AI, centered on AI agent observability and analysis tooling. He holds an MBA from Stanford and a B.S. in C.S. from Duke. Previous to becoming a member of Arize, John led GTM actions at Slingshot AI, and served as a enterprise fellow at Omega Enterprise Companions. In his pre-AI life, John constructed out and ran technical go-to-market groups at Department Metrics.
 Richa Gupta is a Sr. Options Architect at Amazon Internet Providers. She is captivated with architecting end-to-end options for purchasers. Her specialization is machine studying and the way it may be used to construct new options that result in operational excellence and drive enterprise income. Previous to becoming a member of AWS, she labored within the capability of a Software program Engineer and Options Architect, constructing options for big telecom operators. Outdoors of labor, she likes to discover new locations and loves adventurous actions.
Richa Gupta is a Sr. Options Architect at Amazon Internet Providers. She is captivated with architecting end-to-end options for purchasers. Her specialization is machine studying and the way it may be used to construct new options that result in operational excellence and drive enterprise income. Previous to becoming a member of AWS, she labored within the capability of a Software program Engineer and Options Architect, constructing options for big telecom operators. Outdoors of labor, she likes to discover new locations and loves adventurous actions.
 Aris Tsakpinis is a Specialist Options Architect for Generative AI, specializing in open weight fashions on Amazon Bedrock and the broader generative AI open supply panorama. Alongside his skilled function, he’s pursuing a PhD in Machine Studying Engineering on the College of Regensburg, the place his analysis focuses on utilized pure language processing in scientific domains.
Aris Tsakpinis is a Specialist Options Architect for Generative AI, specializing in open weight fashions on Amazon Bedrock and the broader generative AI open supply panorama. Alongside his skilled function, he’s pursuing a PhD in Machine Studying Engineering on the College of Regensburg, the place his analysis focuses on utilized pure language processing in scientific domains.
 Yanyan Zhang is a Senior Generative AI Information Scientist at Amazon Internet Providers, the place she has been engaged on cutting-edge AI/ML applied sciences as a Generative AI Specialist, serving to prospects use generative AI to attain their desired outcomes. Yanyan graduated from Texas A&M College with a PhD in Electrical Engineering. Outdoors of labor, she loves touring, figuring out, and exploring new issues.
Yanyan Zhang is a Senior Generative AI Information Scientist at Amazon Internet Providers, the place she has been engaged on cutting-edge AI/ML applied sciences as a Generative AI Specialist, serving to prospects use generative AI to attain their desired outcomes. Yanyan graduated from Texas A&M College with a PhD in Electrical Engineering. Outdoors of labor, she loves touring, figuring out, and exploring new issues.
 Mani Khanuja is a Principal Generative AI Specialist SA and creator of the ebook Utilized Machine Studying and Excessive-Efficiency Computing on AWS. She leads machine studying initiatives in varied domains comparable to pc imaginative and prescient, pure language processing, and generative AI. She speaks at inside and exterior conferences such AWS re:Invent, Ladies in Manufacturing West, YouTube webinars, and GHC 23. In her free time, she likes to go for lengthy runs alongside the seaside.
Mani Khanuja is a Principal Generative AI Specialist SA and creator of the ebook Utilized Machine Studying and Excessive-Efficiency Computing on AWS. She leads machine studying initiatives in varied domains comparable to pc imaginative and prescient, pure language processing, and generative AI. She speaks at inside and exterior conferences such AWS re:Invent, Ladies in Manufacturing West, YouTube webinars, and GHC 23. In her free time, she likes to go for lengthy runs alongside the seaside.
 Musarath Rahamathullah is an AI/ML and GenAI Options Architect at Amazon Internet Providers, specializing in media and leisure prospects. She holds a Grasp’s diploma in Analytics with a specialization in Machine Studying. She is captivated with utilizing AI options within the AWS Cloud to deal with buyer challenges and democratize know-how. Her skilled background features a function as a Analysis Assistant on the prestigious Indian Institute of Expertise, Chennai. Past her skilled endeavors, she is curious about inside structure, specializing in creating lovely areas to reside.
Musarath Rahamathullah is an AI/ML and GenAI Options Architect at Amazon Internet Providers, specializing in media and leisure prospects. She holds a Grasp’s diploma in Analytics with a specialization in Machine Studying. She is captivated with utilizing AI options within the AWS Cloud to deal with buyer challenges and democratize know-how. Her skilled background features a function as a Analysis Assistant on the prestigious Indian Institute of Expertise, Chennai. Past her skilled endeavors, she is curious about inside structure, specializing in creating lovely areas to reside.



{kind=link}