As firms and particular person customers cope with continually rising quantities of video content material, the flexibility to carry out low-effort search to retrieve movies or video segments utilizing pure language turns into more and more invaluable. Semantic video search affords a robust answer to this downside, so customers can seek for related video content material based mostly on textual queries or descriptions. This strategy can be utilized in a variety of purposes, from private picture and video libraries to skilled video modifying, or enterprise-level content material discovery and moderation, the place it will possibly considerably enhance the way in which we work together with and handle video content material.
Giant-scale pre-training of pc imaginative and prescient fashions with self-supervision straight from pure language descriptions of pictures has made it doable to seize a large set of visible ideas, whereas additionally bypassing the necessity for labor-intensive guide annotation of coaching information. After pre-training, pure language can be utilized to both reference the discovered visible ideas or describe new ones, successfully enabling zero-shot switch to a various set of pc imaginative and prescient duties, reminiscent of picture classification, retrieval, and semantic evaluation.
On this put up, we show use giant imaginative and prescient fashions (LVMs) for semantic video search utilizing pure language and picture queries. We introduce some use case-specific strategies, reminiscent of temporal body smoothing and clustering, to boost the video search efficiency. Moreover, we show the end-to-end performance of this strategy through the use of each asynchronous and real-time internet hosting choices on Amazon SageMaker AI to carry out video, picture, and textual content processing utilizing publicly obtainable LVMs on the Hugging Face Mannequin Hub. Lastly, we use Amazon OpenSearch Serverless with its vector engine for low-latency semantic video search.
About giant imaginative and prescient fashions
On this put up, we implement video search capabilities utilizing multimodal LVMs, which combine textual and visible modalities throughout the pre-training section, utilizing strategies reminiscent of contrastive multimodal illustration studying, Transformer-based multimodal fusion, or multimodal prefix language modeling (for extra particulars, see, Evaluate of Giant Imaginative and prescient Fashions and Visible Immediate Engineering by J. Wang et al.). Such LVMs have lately emerged as foundational constructing blocks for numerous pc imaginative and prescient duties. Owing to their functionality to study all kinds of visible ideas from huge datasets, these fashions can successfully remedy numerous downstream pc imaginative and prescient duties throughout totally different picture distributions with out the necessity for fine-tuning. On this part, we briefly introduce a few of the hottest publicly obtainable LVMs (which we additionally use within the accompanying code pattern).
The CLIP (Contrastive Language-Picture Pre-training) mannequin, launched in 2021, represents a major milestone within the area of pc imaginative and prescient. Educated on a group of 400 million image-text pairs harvested from the web, CLIP showcased the exceptional potential of utilizing large-scale pure language supervision for studying wealthy visible representations. By in depth evaluations throughout over 30 pc imaginative and prescient benchmarks, CLIP demonstrated spectacular zero-shot switch capabilities, typically matching and even surpassing the efficiency of absolutely supervised, task-specific fashions. As an example, a notable achievement of CLIP is its capability to match the highest accuracy of a ResNet-50 mannequin educated on the 1.28 million pictures from the ImageNet dataset, regardless of working in a real zero-shot setting and not using a want for fine-tuning or different entry to labeled examples.
Following the success of CLIP, the open-source initiative OpenCLIP additional superior the state-of-the-art by releasing an open implementation pre-trained on the huge LAION-2B dataset, comprised of two.3 billion English image-text pairs. This substantial enhance within the scale of coaching information enabled OpenCLIP to attain even higher zero-shot efficiency throughout a variety of pc imaginative and prescient benchmarks, demonstrating additional potential of scaling up pure language supervision for studying extra expressive and generalizable visible representations.
Lastly, the set of SigLIP (Sigmoid Loss for Language-Picture Pre-training) fashions, together with one educated on a ten billion multilingual image-text dataset spanning over 100 languages, additional pushed the boundaries of large-scale multimodal studying. The fashions suggest another loss operate for the contrastive pre-training scheme employed in CLIP and have proven superior efficiency in language-image pre-training, outperforming each CLIP and OpenCLIP baselines on a wide range of pc imaginative and prescient duties.
Answer overview
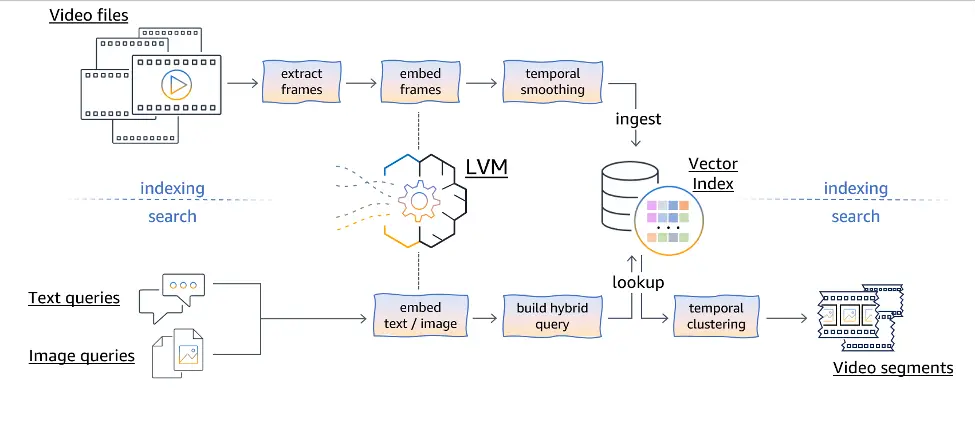
Our strategy makes use of a multimodal LVM to allow environment friendly video search and retrieval based mostly on each textual and visible queries. The strategy may be logically cut up into an indexing pipeline, which may be carried out offline, and a web based video search logic. The next diagram illustrates the pipeline workflows.

The indexing pipeline is accountable for ingesting video information and preprocessing them to assemble a searchable index. The method begins by extracting particular person frames from the video information. These extracted frames are then handed via an embedding module, which makes use of the LVM to map every body right into a high-dimensional vector illustration containing its semantic info. To account for temporal dynamics and movement info current within the video, a temporal smoothing method is utilized to the body embeddings. This step makes certain the ensuing representations seize the semantic continuity throughout a number of subsequent video frames, relatively than treating every body independently (additionally see the outcomes mentioned later on this put up, or seek the advice of the next paper for extra particulars). The temporally smoothed body embeddings are then ingested right into a vector index information construction, which is designed for environment friendly storage, retrieval, and similarity search operations. This listed illustration of the video frames serves as the muse for the next search pipeline.
The search pipeline facilitates content-based video retrieval by accepting textual queries or visible queries (pictures) from customers. Textual queries are first embedded into the shared multimodal illustration area utilizing the LVM’s textual content encoding capabilities. Equally, visible queries (pictures) are processed via the LVM’s visible encoding department to acquire their corresponding embeddings.
After the textual or visible queries are embedded, we will construct a hybrid question to account for key phrases or filter constraints supplied by the consumer (for instance, to look solely throughout sure video classes, or to look inside a selected video). This hybrid question is then used to retrieve probably the most related body embeddings based mostly on their conceptual similarity to the question, whereas adhering to any supplementary key phrase constraints.
The retrieved body embeddings are then subjected to temporal clustering (additionally see the outcomes later on this put up for extra particulars), which goals to group contiguous frames into semantically coherent video segments, thereby returning a complete video sequence (relatively than disjointed particular person frames).
Moreover, sustaining search range and high quality is essential when retrieving content material from movies. As talked about beforehand, our strategy incorporates numerous strategies to boost search outcomes. For instance, throughout the video indexing section, the next strategies are employed to manage the search outcomes (the parameters of which could must be tuned to get the most effective outcomes):
- Adjusting the sampling fee, which determines the variety of frames embedded from every second of video. Much less frequent body sampling may make sense when working with longer movies, whereas extra frequent body sampling could be wanted to catch fast-occurring occasions.
- Modifying the temporal smoothing parameters to, for instance, take away inconsistent search hits based mostly on only a single body hit, or merge repeated body hits from the identical scene.
In the course of the semantic video search section, you should utilize the next strategies:
- Making use of temporal clustering as a post-filtering step on the retrieved timestamps to group contiguous frames into semantically coherent video clips (that may be, in precept, straight performed again by the end-users). This makes certain the search outcomes preserve temporal context and continuity, avoiding disjointed particular person frames.
- Setting the search dimension, which may be successfully mixed with temporal clustering. Rising the search dimension makes certain the related frames are included within the remaining outcomes, albeit at the price of greater computational load (see, for instance, this information for extra particulars).
Our strategy goals to strike a steadiness between retrieval high quality, range, and computational effectivity by using these strategies throughout each the indexing and search phases, in the end enhancing the consumer expertise in semantic video search.
The proposed answer structure offers environment friendly semantic video search through the use of open supply LVMs and AWS providers. The structure may be logically divided into two parts: an asynchronous video indexing pipeline and on-line content material search logic. The accompanying pattern code on GitHub showcases construct, experiment regionally, in addition to host and invoke each components of the workflow utilizing a number of open supply LVMs obtainable on the Hugging Face Mannequin Hub (CLIP, OpenCLIP, and SigLIP). The next diagram illustrates this structure.

The pipeline for asynchronous video indexing is comprised of the next steps:
- The consumer uploads a video file to an Amazon Easy Storage Service (Amazon S3) bucket, which initiates the indexing course of.
- The video is distributed to a SageMaker asynchronous endpoint for processing. The processing steps contain:
- Decoding of frames from the uploaded video file.
- Technology of body embeddings by LVM.
- Software of temporal smoothing, accounting for temporal dynamics and movement info current within the video.
- The body embeddings are ingested into an OpenSearch Serverless vector index, designed for environment friendly storage, retrieval, and similarity search operations.
SageMaker asynchronous inference endpoints are well-suited for dealing with requests with giant payloads, prolonged processing occasions, and close to real-time latency necessities. This SageMaker functionality queues incoming requests and processes them asynchronously, accommodating giant payloads and lengthy processing occasions. Asynchronous inference permits price optimization by robotically scaling the occasion depend to zero when there are not any requests to course of, so computational assets are used solely when actively dealing with requests. This flexibility makes it a perfect alternative for purposes involving giant information volumes, reminiscent of video processing, whereas sustaining responsiveness and environment friendly useful resource utilization.
OpenSearch Serverless is an on-demand serverless model for Amazon OpenSearch Service. We use OpenSearch Serverless as a vector database for storing embeddings generated by the LVM. The index created within the OpenSearch Serverless assortment serves because the vector retailer, enabling environment friendly storage and speedy similarity-based retrieval of related video segments.
The net content material search then may be damaged right down to the next steps:
- The consumer offers a textual immediate or a picture (or each) representing the specified content material to be searched.
- The consumer immediate is distributed to a real-time SageMaker endpoint, which ends up in the next actions:
- An embedding is generated for the textual content or picture question.
- The question with embeddings is distributed to the OpenSearch vector index, which performs a k-nearest neighbors (k-NN) search to retrieve related body embeddings.
- The retrieved body embeddings bear temporal clustering.
- The ultimate search outcomes, comprising related video segments, are returned to the consumer.
SageMaker real-time inference fits workloads needing real-time, interactive, low-latency responses. Deploying fashions to SageMaker internet hosting providers offers absolutely managed inference endpoints with automated scaling capabilities, offering optimum efficiency for real-time necessities.
Code and surroundings
This put up is accompanied by a pattern code on GitHub that gives complete annotations and code to arrange the mandatory AWS assets, experiment regionally with pattern video information, after which deploy and run the indexing and search pipelines. The code pattern is designed to exemplify greatest practices when creating ML options on SageMaker, reminiscent of utilizing configuration information to outline versatile inference stack parameters and conducting native checks of the inference artifacts earlier than deploying them to SageMaker endpoints. It additionally accommodates guided implementation steps with explanations and reference for configuration parameters. Moreover, the pocket book automates the cleanup of all provisioned assets.
Conditions
The prerequisite to run the supplied code is to have an lively AWS account and arrange Amazon SageMaker Studio. Consult with Use fast setup for Amazon SageMaker AI to arrange SageMaker for those who’re a first-time consumer after which comply with the steps to open SageMaker Studio.
Deploy the answer
To start out the implementation to clone the repository, open the pocket book semantic_video_search_demo.ipynb, and comply with the steps within the pocket book.
In Part 2 of the pocket book, set up the required packages and dependencies, outline world variables, arrange Boto3 shoppers, and connect required permissions to the SageMaker AWS Id and Entry Administration (IAM) function to work together with Amazon S3 and OpenSearch Service from the pocket book.
In Part 3, create safety parts for OpenSearch Serverless (encryption coverage, community coverage, and information entry coverage) after which create an OpenSearch Serverless assortment. For simplicity, on this proof of idea implementation, we permit public web entry to the OpenSearch Serverless assortment useful resource. Nonetheless, for manufacturing environments, we strongly recommend utilizing non-public connections between your Digital Non-public Cloud (VPC) and OpenSearch Serverless assets via a VPC endpoint. For extra particulars, see Entry Amazon OpenSearch Serverless utilizing an interface endpoint (AWS PrivateLink).
In Part 4, import and examine the config file, and select an embeddings mannequin for video indexing and corresponding embeddings dimension. In Part 5, create a vector index throughout the OpenSearch assortment you created earlier.
To show the search outcomes, we additionally present references to some pattern movies you can experiment with in Part 6. In Part 7, you’ll be able to experiment with the proposed semantic video search strategy regionally within the pocket book, earlier than deploying the inference stacks.
In Sections 8, 9, and 10, we offer code to deploy two SageMaker endpoints: an asynchronous endpoint for video embedding and indexing and a real-time inference endpoint for video search. After these steps, we additionally take a look at our deployed sematic video search answer with just a few instance queries.
Lastly, Part 11 accommodates the code to wash up the created assets to keep away from recurring prices.
Outcomes
The answer was evaluated throughout a various vary of use instances, together with the identification of key moments in sports activities video games, particular outfit items or shade patterns on trend runways, and different duties in full-length movies on the style trade. Moreover, the answer was examined for detecting action-packed moments like explosions in motion motion pictures, figuring out when people entered video surveillance areas, and extracting particular occasions reminiscent of sports activities award ceremonies.
For our demonstration, we created a video catalog consisting of the next movies: A Look Again at New York Vogue Week: Males’s, F1 Insights powered by AWS, Amazon Air’s latest plane, the A330, is right here, and Now Go Construct with Werner Vogels – Autonomous Trucking.
To show the search functionality for figuring out particular objects throughout this video catalog, we employed 4 textual content prompts and 4 pictures. The introduced outcomes had been obtained utilizing the google/siglip-so400m-patch14-384 mannequin, with temporal clustering enabled and a timestamp filter set to 1 second. Moreover, smoothing was enabled with a kernel dimension of 11, and the search dimension was set to twenty (which had been discovered to be good default values for shorter movies). The left column within the subsequent figures specifies the search sort, both by picture or textual content, together with the corresponding picture identify or textual content immediate used.
The next determine reveals the textual content prompts we used and the corresponding outcomes.

The next determine reveals the pictures we used to carry out reverse pictures search and corresponding search outcomes for every picture.

As talked about, we applied temporal clustering within the lookup code, permitting for the grouping of frames based mostly on their ordered timestamps. The accompanying pocket book with pattern code showcases the temporal clustering performance by displaying (just a few frames from) the returned video clip and highlighting the important thing body with the best search rating inside every group, as illustrated within the following determine. This strategy facilitates a handy presentation of the search outcomes, enabling customers to return total playable video clips (even when not all frames had been really listed in a vector retailer).

To showcase the hybrid search capabilities with OpenSearch Service, we current outcomes for the textual immediate “sky,” with all different search parameters set identically to the earlier configurations. We show two distinct instances: an unconstrained semantic search throughout the whole listed video catalog, and a search confined to a selected video. The next determine illustrates the outcomes obtained from an unconstrained semantic search question.

We performed the identical seek for “sky,” however now confined to trucking movies.

As an example the consequences of temporal smoothing, we generated search sign rating charts (based mostly on cosine similarity) for the immediate F1 crews change tyres within the formulaone video, each with and with out temporal smoothing. We set a threshold of 0.315 for illustration functions and highlighted video segments with scores exceeding this threshold. With out temporal smoothing (see the next determine), we noticed two adjoining episodes round t=35 seconds and two extra episodes after t=65 seconds. Notably, the third and fourth episodes had been considerably shorter than the primary two, regardless of exhibiting greater scores. Nonetheless, we will do higher, if our goal is to prioritize longer semantically cohesive video episodes within the search.

To deal with this, we apply temporal smoothing. As proven within the following determine, now the primary two episodes seem like merged right into a single, prolonged episode with the best rating. The third episode skilled a slight rating discount, and the fourth episode grew to become irrelevant resulting from its brevity. Temporal smoothing facilitated the prioritization of longer and extra coherent video moments related to the search question by consolidating adjoining high-scoring segments and suppressing remoted, transient occurrences.

Clear up
To wash up the assets created as a part of this answer, seek advice from the cleanup part within the supplied pocket book and execute the cells on this part. This can delete the created IAM insurance policies, OpenSearch Serverless assets, and SageMaker endpoints to keep away from recurring prices.
Limitations
All through our work on this venture, we additionally recognized a number of potential limitations that might be addressed via future work:
- Video high quality and backbone may influence search efficiency, as a result of blurred or low-resolution movies could make it difficult for the mannequin to precisely establish objects and complicated particulars.
- Small objects inside movies, reminiscent of a hockey puck or a soccer, could be tough for LVMs to persistently acknowledge resulting from their diminutive dimension and visibility constraints.
- LVMs may wrestle to understand scenes that signify a temporally extended contextual state of affairs, reminiscent of detecting a point-winning shot in tennis or a automobile overtaking one other car.
- Correct automated measurement of answer efficiency is hindered with out the provision of manually labeled floor reality information for comparability and analysis.
Abstract
On this put up, we demonstrated some great benefits of the zero-shot strategy to implementing semantic video search utilizing both textual content prompts or pictures as enter. This strategy readily adapts to numerous use instances with out the necessity for retraining or fine-tuning fashions particularly for video search duties. Moreover, we launched strategies reminiscent of temporal smoothing and temporal clustering, which considerably improve the standard and coherence of video search outcomes.
The proposed structure is designed to facilitate an economical manufacturing surroundings with minimal effort, eliminating the requirement for in depth experience in machine studying. Moreover, the present structure seamlessly accommodates the mixing of open supply LVMs, enabling the implementation of customized preprocessing or postprocessing logic throughout each the indexing and search phases. This flexibility is made doable through the use of SageMaker asynchronous and real-time deployment choices, offering a robust and versatile answer.
You possibly can implement semantic video search utilizing totally different approaches or AWS providers. For associated content material, seek advice from the next AWS weblog posts as examples on semantic search utilizing proprietary ML fashions: Implement serverless semantic search of picture and reside video with Amazon Titan Multimodal Embeddings or Construct multimodal search with Amazon OpenSearch Service.
In regards to the Authors
 Dr. Alexander Arzhanov is an AI/ML Specialist Options Architect based mostly in Frankfurt, Germany. He helps AWS prospects design and deploy their ML options throughout the EMEA area. Previous to becoming a member of AWS, Alexander was researching origins of heavy parts in our universe and grew keen about ML after utilizing it in his large-scale scientific calculations.
Dr. Alexander Arzhanov is an AI/ML Specialist Options Architect based mostly in Frankfurt, Germany. He helps AWS prospects design and deploy their ML options throughout the EMEA area. Previous to becoming a member of AWS, Alexander was researching origins of heavy parts in our universe and grew keen about ML after utilizing it in his large-scale scientific calculations.
 Dr. Ivan Sosnovik is an Utilized Scientist within the AWS Machine Studying Options Lab. He develops ML options to assist prospects to attain their enterprise targets.
Dr. Ivan Sosnovik is an Utilized Scientist within the AWS Machine Studying Options Lab. He develops ML options to assist prospects to attain their enterprise targets.
 Nikita Bubentsov is a Cloud Gross sales Consultant based mostly in Munich, Germany, and a part of Technical Area Neighborhood (TFC) in pc imaginative and prescient and machine studying. He helps enterprise prospects drive enterprise worth by adopting cloud options and helps AWS EMEA organizations within the pc imaginative and prescient space. Nikita is keen about pc imaginative and prescient and the longer term potential that it holds.
Nikita Bubentsov is a Cloud Gross sales Consultant based mostly in Munich, Germany, and a part of Technical Area Neighborhood (TFC) in pc imaginative and prescient and machine studying. He helps enterprise prospects drive enterprise worth by adopting cloud options and helps AWS EMEA organizations within the pc imaginative and prescient space. Nikita is keen about pc imaginative and prescient and the longer term potential that it holds.



{kind=link}