
For an AI mannequin to carry out successfully in specialised domains, it requires entry to related background data. A buyer help chat assistant, for example, wants detailed details about the enterprise it serves, and a authorized evaluation software should draw upon a complete database of previous instances.
To equip massive language fashions (LLMs) with this information, builders usually use Retrieval Augmented Era (RAG). This method retrieves pertinent data from a data base and incorporates it into the person’s immediate, considerably bettering the mannequin’s responses. Nonetheless, a key limitation of conventional RAG programs is that they usually lose contextual nuances when encoding knowledge, resulting in irrelevant or incomplete retrievals from the data base.
Challenges in conventional RAG
In conventional RAG, paperwork are sometimes divided into smaller chunks to optimize retrieval effectivity. Though this methodology performs effectively in lots of instances, it will possibly introduce challenges when particular person chunks lack the required context. For instance, if a coverage states that distant work requires “6 months of tenure” (chunk 1) and “HR approval for exceptions” (chunk 3), however omits the center chunk linking exceptions to supervisor approval, a person asking about eligibility for a 3-month tenure worker would possibly obtain a deceptive “No” as a substitute of the proper “Solely with HR approval.” This happens as a result of remoted chunks fail to protect dependencies between clauses, highlighting a key limitation of fundamental chunking methods in RAG programs.
Contextual retrieval enhances conventional RAG by including chunk-specific explanatory context to every chunk earlier than producing embeddings. This method enriches the vector illustration with related contextual data, enabling extra correct retrieval of semantically associated content material when responding to person queries. As an illustration, when requested about distant work eligibility, it fetches each the tenure requirement and the HR exception clause, enabling the LLM to offer an correct response reminiscent of “Usually no, however HR might approve exceptions.” By intelligently stitching fragmented data, contextual retrieval mitigates the pitfalls of inflexible chunking, delivering extra dependable and nuanced solutions.
On this publish, we show how one can use contextual retrieval with Anthropic and Amazon Bedrock Data Bases.
Answer overview
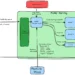
This resolution makes use of Amazon Bedrock Data Bases, incorporating a {custom} Lambda operate to remodel knowledge in the course of the data base ingestion course of. This Lambda operate processes paperwork from Amazon Easy Storage Service (Amazon S3), chunks them into smaller items, enriches every chunk with contextual data utilizing Anthropic’s Claude in Amazon Bedrock, after which saves the outcomes again to an intermediate S3 bucket. Right here’s a step-by-step clarification:
- Learn enter recordsdata from an S3 bucket specified within the occasion.
- Chunk enter knowledge into smaller chunks.
- Generate contextual data for every chunk utilizing Anthropic’s Claude 3 Haiku
- Write processed chunks with their metadata again to intermediate S3 bucket
The next diagram is the answer structure.

Stipulations
To implement the answer, full the next prerequisite steps:
Earlier than you start, you’ll be able to deploy this resolution by downloading the required recordsdata and following the directions in its corresponding GitHub repository. This structure is constructed round utilizing the proposed chunking resolution to implement contextual retrieval utilizing Amazon Bedrock Data Bases.
Implement contextual retrieval in Amazon Bedrock
On this part, we show how one can use the proposed {custom} chunking resolution to implement contextual retrieval utilizing Amazon Bedrock Data Bases. Builders can use {custom} chunking methods in Amazon Bedrock to optimize how massive paperwork or datasets are divided into smaller, extra manageable items for processing by basis fashions (FMs). This method permits extra environment friendly and efficient dealing with of long-form content material, bettering the standard of responses. By tailoring the chunking methodology to the particular traits of the information and the necessities of the duty at hand, builders can improve the efficiency of pure language processing functions constructed on Amazon Bedrock. Customized chunking can contain methods reminiscent of semantic segmentation, sliding home windows with overlap, or utilizing doc construction to create logical divisions within the textual content.
To implement contextual retrieval in Amazon Bedrock, full the next steps, which might be discovered within the pocket book within the GitHub repository.
To arrange the surroundings, observe these steps:
- Set up the required dependencies:
- Import the required libraries and arrange AWS purchasers:
- Outline data base parameters:
Create data bases with completely different chunking methods
To create data bases with completely different chunking methods, use the next code.
- Normal mounted chunking:
- Customized chunking with Lambda operate
Consider efficiency utilizing RAGAS framework
To guage efficiency utilizing the RAGAS framework, observe these steps:
- Arrange RAGAS analysis:
- Put together analysis dataset:
- Run analysis and evaluate outcomes:
Efficiency benchmarks
To guage the efficiency of the proposed contextual retrieval method, we used the AWS Determination Information: Selecting a generative AI service because the doc for RAG testing. We arrange two Amazon Bedrock data bases for the analysis:
- One data base with the default chunking technique, which makes use of 300 tokens per chunk with a 20% overlap
- One other data base with the {custom} contextual retrieval chunking method, which has a {custom} contextual retrieval Lambda transformer along with the mounted chunking technique that additionally makes use of 300 tokens per chunk with a 20% overlap
We used the RAGAS framework to evaluate the efficiency of those two approaches utilizing small datasets. Particularly, we appeared on the following metrics:
context_recall– Context recall measures how lots of the related paperwork (or items of knowledge) had been efficiently retrievedcontext_precision– Context precision is a metric that measures the proportion of related chunks within theretrieved_contextsanswer_correctness– The evaluation of reply correctness entails gauging the accuracy of the generated reply when in comparison with the bottom reality
The outcomes obtained utilizing the default chunking technique are offered within the following desk.

The outcomes obtained utilizing the contextual retrieval chunking technique are offered within the following desk. It demonstrates improved efficiency throughout the important thing metrics evaluated, together with context recall, context precision, and reply correctness.

By aggregating the outcomes, we are able to observe that the contextual chunking method outperformed the default chunking technique throughout the context_recall, context_precision, and answer_correctness metrics. This means the advantages of the extra subtle contextual retrieval methods applied.

Implementation concerns
When implementing contextual retrieval utilizing Amazon Bedrock, a number of elements want cautious consideration. First, the {custom} chunking technique have to be optimized for each efficiency and accuracy, requiring thorough testing throughout completely different doc sorts and sizes. The Lambda operate’s reminiscence allocation and timeout settings must be calibrated primarily based on the anticipated doc complexity and processing necessities, with preliminary suggestions of 1024 MB reminiscence and 900-second timeout serving as baseline configurations. Organizations should additionally configure IAM roles with the precept of least privilege whereas sustaining adequate permissions for Lambda to work together with Amazon S3 and Amazon Bedrock companies. Moreover, the vectorization course of and data base configuration must be fine-tuned to stability between retrieval accuracy and computational effectivity, significantly when scaling to bigger datasets.
Infrastructure scalability and monitoring concerns are equally essential for profitable implementation. Organizations ought to implement strong error-handling mechanisms throughout the Lambda operate to handle varied doc codecs and potential processing failures gracefully. Monitoring programs must be established to trace key metrics reminiscent of chunking efficiency, retrieval accuracy, and system latency, enabling proactive optimization and upkeep.
Utilizing Langfuse with Amazon Bedrock is an effective choice to introduce observability to this resolution. The S3 bucket construction for each supply and intermediate storage must be designed with clear lifecycle insurance policies and entry controls and think about Regional availability and knowledge residency necessities. Moreover, implementing a staged deployment method, beginning with a subset of information earlier than scaling to full manufacturing workloads, will help establish and deal with potential bottlenecks or optimization alternatives early within the implementation course of.
Cleanup
Once you’re achieved experimenting with the answer, clear up the sources you created to keep away from incurring future fees.
Conclusion
By combining Anthropic’s subtle language fashions with the strong infrastructure of Amazon Bedrock, organizations can now implement clever programs for data retrieval that ship deeply contextualized, nuanced responses. The implementation steps outlined on this publish present a transparent pathway for organizations to make use of contextual retrieval capabilities by way of Amazon Bedrock. By following the detailed configuration course of, from organising IAM permissions to deploying {custom} chunking methods, builders and organizations can unlock the total potential of context-aware AI programs.
By leveraging Anthropic’s language fashions, organizations can ship extra correct and significant outcomes to their customers whereas staying on the forefront of AI innovation. You may get began at present with contextual retrieval utilizing Anthropic’s language fashions by way of Amazon Bedrock and rework how your AI processes data with a small-scale proof of idea utilizing your current knowledge. For personalised steerage on implementation, contact your AWS account staff.
In regards to the Authors
 Suheel Farooq is a Principal Engineer in AWS Assist Engineering, specializing in Generative AI, Synthetic Intelligence, and Machine Studying. As a Topic Matter Skilled in Amazon Bedrock and SageMaker, he helps enterprise clients design, construct, modernize, and scale their AI/ML and Generative AI workloads on AWS. In his free time, Suheel enjoys figuring out and mountain climbing.
Suheel Farooq is a Principal Engineer in AWS Assist Engineering, specializing in Generative AI, Synthetic Intelligence, and Machine Studying. As a Topic Matter Skilled in Amazon Bedrock and SageMaker, he helps enterprise clients design, construct, modernize, and scale their AI/ML and Generative AI workloads on AWS. In his free time, Suheel enjoys figuring out and mountain climbing.
 Qingwei Li is a Machine Studying Specialist at Amazon Net Companies. He obtained his Ph.D. in Operations Analysis after he broke his advisor’s analysis grant account and didn’t ship the Nobel Prize he promised. At present he helps clients within the monetary service and insurance coverage trade construct machine studying options on AWS. In his spare time, he likes studying and educating.
Qingwei Li is a Machine Studying Specialist at Amazon Net Companies. He obtained his Ph.D. in Operations Analysis after he broke his advisor’s analysis grant account and didn’t ship the Nobel Prize he promised. At present he helps clients within the monetary service and insurance coverage trade construct machine studying options on AWS. In his spare time, he likes studying and educating.
 Vinita is a Senior Serverless Specialist Options Architect at AWS. She combines AWS data with sturdy enterprise acumen to architect revolutionary options that drive quantifiable worth for purchasers and has been distinctive at navigating advanced challenges. Vinita’s technical experience on software modernization, GenAI, cloud computing and skill to drive measurable enterprise influence make her present nice influence in buyer’s journey with AWS.
Vinita is a Senior Serverless Specialist Options Architect at AWS. She combines AWS data with sturdy enterprise acumen to architect revolutionary options that drive quantifiable worth for purchasers and has been distinctive at navigating advanced challenges. Vinita’s technical experience on software modernization, GenAI, cloud computing and skill to drive measurable enterprise influence make her present nice influence in buyer’s journey with AWS.
 Sharon Li is an AI/ML Specialist Options Architect at Amazon Net Companies (AWS) primarily based in Boston, Massachusetts. With a ardour for leveraging cutting-edge know-how, Sharon is on the forefront of growing and deploying revolutionary generative AI options on the AWS cloud platform.
Sharon Li is an AI/ML Specialist Options Architect at Amazon Net Companies (AWS) primarily based in Boston, Massachusetts. With a ardour for leveraging cutting-edge know-how, Sharon is on the forefront of growing and deploying revolutionary generative AI options on the AWS cloud platform.
 Venkata Moparthi is a Senior Options Architect, focuses on cloud migrations, generative AI, and safe structure for monetary companies and different industries. He combines technical experience with customer-focused methods to speed up digital transformation and drive enterprise outcomes by way of optimized cloud options.
Venkata Moparthi is a Senior Options Architect, focuses on cloud migrations, generative AI, and safe structure for monetary companies and different industries. He combines technical experience with customer-focused methods to speed up digital transformation and drive enterprise outcomes by way of optimized cloud options.


{kind=link}