When ingesting information into Amazon OpenSearch, prospects typically want to reinforce information earlier than placing it into their indexes. As an example, you is likely to be ingesting log information with an IP deal with and need to get a geographic location for the IP deal with, otherwise you is likely to be ingesting buyer feedback and need to establish the language they’re in. Historically, this requires an exterior course of that complicates information ingest pipelines and might trigger a pipeline to fail. OpenSearch affords a variety of third-party machine studying (ML) connectors to assist this augmentation.
This publish highlights two of those third-party ML connectors. The primary connector we reveal is the Amazon Comprehend connector. On this publish, we present you use this connector to invoke the LangDetect API to detect the languages of ingested paperwork.
The second connector we reveal is the Amazon Bedrock connector to invoke the Amazon Titan Textual content Embeddings v2 mannequin with the intention to create embeddings from ingested paperwork and carry out semantic search.
Answer overview
We use Amazon OpenSearch with Amazon Comprehend to reveal the language detection function. That will help you replicate this setup, we’ve offered the required supply code, an Amazon SageMaker pocket book, and an AWS CloudFormation template. You will discover these sources within the sample-opensearch-ml-rest-api GitHub repo.

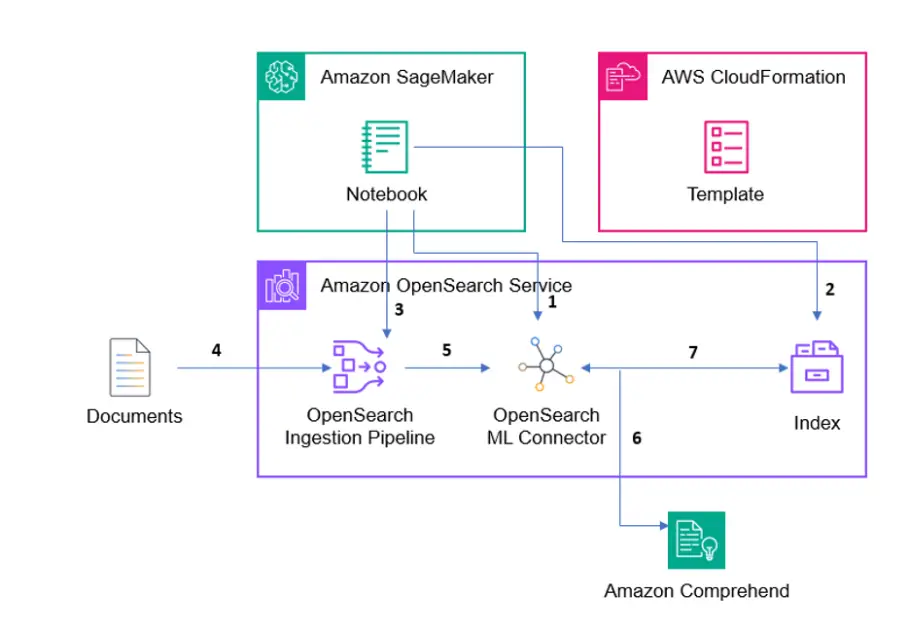
The reference structure proven within the previous determine exhibits the parts used on this answer. A SageMaker pocket book is used as a handy technique to execute the code that’s offered within the Github repository offered above.
Conditions
To run the total demo utilizing the sample-opensearch-ml-rest-api, ensure you have an AWS account with entry to:
Half 1: The Amazon Comprehend ML connector
Arrange OpenSearch to entry Amazon Comprehend
Earlier than you need to use Amazon Comprehend, you’ll want to make it possible for OpenSearch can name Amazon Comprehend. You do that by supplying OpenSearch with an IAM function that has entry to invoke the DetectDominantLanguage API. This requires the OpenSearch Cluster to have advantageous grained entry management enabled. The CloudFormation template creates a task for this referred to as
- Open the OpenSearch Dashboard console—you could find the URL within the output of the CloudFormation template—and sign up utilizing the username and password you offered.

- Select Safety within the left-hand menu (in case you don’t see the menu, select the three horizontal strains icon on the prime left of the dashboard).

- From the safety menu, choose Roles to handle the OpenSearch roles.

- Within the search field. enter
ml_full_accessfunction.
- Choose the Mapped customers hyperlink to map the IAM function to this OpenSearch function.

- On the Mapped customers display, select Handle mapping to edit the present mappings.

- Add the IAM function talked about beforehand to map it to the
ml_full_accessfunction, it will permit OpenSearch to entry the wanted AWS sources from the ml-commons plugin. Enter your IAM function Amazon Useful resource Title (ARN) (arn:aws:iam::) within the backend roles subject and select Map.:function/ - -SageMaker-OpenSearch-demo-role
Arrange the OpenSearch ML connector to Amazon Comprehend
On this step, you arrange the ML connector to attach Amazon Comprehend to OpenSearch.
- Get an authorization token to make use of when making the decision to OpenSearch from the SageMaker pocket book. The token makes use of an IAM function hooked up to the pocket book by the CloudFormation template that has permissions to name OpenSearch. That very same function is mapped to the OpenSearch admin function in the identical method you simply mapped the function to entry Amazon Comprehend. Use the next code to set this up:
- Create the connector. It wants a couple of items of knowledge:
- It wants a protocol. For this instance, use
aws_sigv4, which permits OpenSearch to make use of an IAM function to name Amazon Comprehend. - Present the ARN for this function, which is identical function you used to arrange permissions for the
ml_full_accessfunction. - Present
comprehendbecause theservice_name, andDetectDominateLanguagebecause theapi_name. - Present the URL to Amazon Comprehend and arrange name the API and what information to move to it.
- It wants a protocol. For this instance, use
The ultimate name seems to be like:
Register the Amazon Comprehend API connector
The following step is to register the Amazon Comprehend API connector with OpenSearch utilizing the Register Mannequin API from OpenSearch.
- Use the
comprehend_connectorthat you just saved from the final step.
As of OpenSearch 2.13, when the mannequin is first invoked, it’s robotically deployed. Previous to 2.13 you would need to manually deploy the mannequin inside OpenSearch.
Take a look at the Amazon Comprehend API in OpenSearch
With the connector in place, you’ll want to take a look at the API to ensure it was arrange and configured appropriately.
- Make the next name to OpenSearch.
- It is best to get the next end result from the decision, displaying the language code as
zhwith a rating of1.0:
Create an ingest pipeline that makes use of the Amazon Comprehend API to annotate the language
The following step is to create a pipeline in OpenSearch that calls the Amazon Comprehend API and provides the outcomes of the decision to the doc being listed. To do that, you present each an input_map and an output_map. You employ these to inform OpenSearch what to ship to the API and deal with what comes again from the decision.
You may see from the previous code that you’re pulling again each the highest language end result and its rating from Amazon Comprehend and including these fields to the doc.
Half 2: The Amazon Bedrock ML connector
On this part, you employ Amazon OpenSearch with Amazon Bedrock by way of the ml-commons plugin to carry out a multilingual semantic search. Just remember to have the answer conditions in place earlier than making an attempt this part.
Within the SageMaker occasion that was deployed for you, you may see the next information: english.json, french.json, german.json.
These paperwork have sentences of their respective languages that discuss concerning the time period spring in numerous contexts. These contexts embody spring as a verb which means to maneuver all of a sudden, as a noun which means the season of spring, and eventually spring as a noun which means a mechanical half. On this part, you deploy Amazon Titan Textual content Embeddings mannequin v2 utilizing the ml connector for Amazon Bedrock. You then use this embeddings mannequin to create vectors of textual content in three languages by ingesting the totally different language JSON information. Lastly, these vectors are saved in Amazon OpenSearch to allow semantic searches for use throughout the language units.
Amazon Bedrock supplies streamlined entry to varied highly effective AI basis fashions by way of a single API interface. This managed service consists of fashions from Amazon and different main AI corporations. You may take a look at totally different fashions to seek out the perfect match to your particular wants, whereas sustaining safety, privateness, and accountable AI practices. The service lets you customise these fashions with your individual information by way of strategies similar to fine-tuning and Retrieval Augmented Technology (RAG). Moreover, you need to use Amazon Bedrock to create AI brokers that may work together with enterprise methods and information, making it a complete answer for growing generative AI purposes.

The reference structure within the previous determine exhibits the parts used on this answer.
(1) First we should create the OpenSearch ML connector by way of operating code inside the Amazon SageMaker pocket book. The connector basically creates a Relaxation API name to any mannequin, we particularly need to create a connector to name the Titan Embeddings mannequin inside Amazon Bedrock.
(2) Subsequent, we should create an index to later index our language paperwork into. When creating an index, you may specify its mappings, settings, and aliases.
(3) After creating an index inside Amazon OpenSearch, we need to create an OpenSearch Ingestion pipeline that may permit us to streamline information processing and preparation for indexing, making it simpler to handle and make the most of the info. (4) Now that now we have created an index and arrange a pipeline, we are able to begin indexing our paperwork into the pipeline.
(5 – 6) We use the pipeline in OpenSearch that calls the Titan Embeddings mannequin API. We ship our language paperwork to the titan embeddings mannequin, and the mannequin returns vector embeddings of the sentences.
(7) We retailer the vector embeddings inside our index and carry out vector semantic search.
Whereas this publish highlights solely particular areas of the general answer, the SageMaker pocket book has the code and directions to run the total demo your self.
Earlier than you need to use Amazon Bedrock, you’ll want to make it possible for OpenSearch can name Amazon Bedrock. .
Load sentences from the JSON paperwork into dataframes
Begin by loading the JSON doc sentences into dataframes for extra structured group. Every row can comprise the textual content, embeddings, and extra contextual data:
Create the OpenSearch ML connector to Amazon Bedrock
After loading the JSON paperwork into dataframes, you’re able to arrange the OpenSearch ML connector to attach Amazon Bedrock to OpenSearch.
- The connector wants the next data.
- It wants a protocol. For this answer, use
aws_sigv4, which permits OpenSearch to make use of an IAM function to name Amazon Bedrock. - Present the identical function used earlier to arrange permissions for the
ml_full_accessfunction. - Present the
service_name, mannequin, dimensions of the mannequin, and embedding sort.
- It wants a protocol. For this answer, use
The ultimate name seems to be like the next:
Take a look at the Amazon Titan Embeddings mannequin in OpenSearch
After registering and deploying the Amazon Titan Embeddings mannequin utilizing the Amazon Bedrock connector, you may take a look at the API to confirm that it was arrange and configured appropriately. To do that, make the next name to OpenSearch:
It is best to get a formatted end result, much like the next, from the decision that exhibits the generated embedding from the Amazon Titan Embeddings mannequin:
The preceding result is significantly shortened compared to the actual embedding result you might receive. The purpose of this snippet is to show you the format.
Create the index pipeline that uses the Amazon Titan Embeddings model
Create a pipeline in OpenSearch. You use this pipeline to tell OpenSearch to send the fields you want embeddings for to the embeddings model.
pipeline_name = "titan_embedding_pipeline_v2"
url = f"{host}/_ingest/pipeline/{pipeline_name}"
pipeline_body = {
"description": "Titan embedding pipeline",
"processors": [
{
"text_embedding": {
"model_id": bedrock_model_id,
"field_map": {
"sentence": "sentence_vector"
}
}
}
]
}
response = requests.put(url, auth=awsauth, json=pipeline_body, headers={"Content material-Sort": "software/json"})
print(response.textual content)
Create an index
With the pipeline in place, the subsequent step is to create an index that may use the pipeline. There are three fields within the index:
sentence_vector– That is the place the vector embedding will probably be saved when returned from Amazon Bedrock.sentence– That is the non-English language sentence.sentence_english– that is the English translation of the sentence. Embody this to see how nicely the mannequin is translating the unique sentence.
Load dataframes into the index
Earlier on this part, you loaded the sentences from the JSON paperwork into dataframes. Now, you may index the paperwork and generate embeddings for them utilizing the Amazon Titan Textual content Embeddings Mannequin v2. The embeddings will probably be saved within the sentence_vector subject.
Carry out semantic k-NN throughout the paperwork
The ultimate step is to carry out a k-nearest neighbor (k-NN) search throughout the paperwork.
The instance question is in French and might be translated to the solar is shining. Holding in thoughts that the JSON paperwork have sentences that use spring in numerous contexts, you’re in search of question outcomes and vector matches of sentences that use spring within the context of the season of spring.
Listed below are a number of the outcomes from this question:
This exhibits that the mannequin can present outcomes throughout all three languages. It is very important notice that the boldness scores for these outcomes is likely to be low since you’ve solely ingested a pair paperwork with a handful of sentences in every for this demo. To extend confidence scores and accuracy, ingest a strong dataset with a number of languages and loads of sentences for reference.
Clear Up
To keep away from incurring future expenses, go to the AWS Administration Console for CloudFormation console and delete the stack you deployed. It will terminate the sources used on this answer.
Advantages of utilizing the ML connector for machine studying mannequin integration with OpenSearch
There are a lot of methods you may carry out k-nn semantic vector searches; a preferred strategies is to deploy exterior Hugging Face sentence transformer fashions to a SageMaker endpoint. The next are the advantages of utilizing the ML connector method we confirmed on this publish, and why must you use it as an alternative of deploying fashions to a SageMaker endpoint:
- Simplified structure
- Single system to handle
- Native OpenSearch integration
- Easier deployment
- Unified monitoring
- Operational advantages
- Much less infrastructure to keep up
- Constructed-in scaling with OpenSearch
- Simplified safety mannequin
- Easy updates and upkeep
- Value effectivity
- Single system prices
- Pay-per-use Amazon Bedrock pricing
- No endpoint administration prices
- Simplified billing
Conclusion
Now that you just’ve seen how you need to use the OpenSearch ML connector to reinforce your information with exterior REST calls, we advocate that you just go to the GitHub repo in case you haven’t already and stroll by way of the total demo yourselves. The complete demo exhibits how you need to use Amazon Comprehend for language detection and use Amazon Bedrock for multilingual semantic vector search, utilizing the ml-connector plugin for each use circumstances. It additionally has pattern textual content and JSON paperwork to ingest so you may see how the pipeline works.
Concerning the Authors

John Trollinger is a Principal Options Architect supporting the World Broad Public Sector with a give attention to OpenSearch and Knowledge Analytics. John has been working with public sector prospects over the previous 25 years serving to them ship mission capabilities. Exterior of labor, John likes to gather AWS certifications and compete in triathlons.

Shwetha Radhakrishnan is a Options Architect for Amazon Net Companies (AWS) with a spotlight in Knowledge Analytics & Machine Studying. She has been constructing options that drive cloud adoption and assist empower organizations to make data-driven selections inside the public sector. Exterior of labor, she loves dancing, spending time with family and friends, and touring.



{kind=link}