
mechanism is on the core of recent day transformers. However scaling the context window of those transformers was a serious problem, and it nonetheless is regardless that we’re within the period of one million tokens + context window (Qwen 2.5 [1]). There are each appreciable compute and reminiscence certain complexities in these fashions after we scale the context window (A naive Consideration Mechanism scales quadratically in each compute and reminiscence necessities). Revisiting Flash Consideration lets us perceive the complexities of optimizing the underlying operations on GPUs and extra importantly provides us a greater grip on considering what’s subsequent.
Let’s shortly revisit a naive consideration algorithm to see what’s happening.

As you may see if we aren’t being cautious then we’ll find yourself materializing a full NxM consideration matrix into the GPU HBM. That means the reminiscence requirement will go up quadratically to growing context size.
In the event you wanna be taught extra concerning the GPU reminiscence hierarchy and its variations, my earlier submit on Triton is an effective start line. This may even be helpful as we go alongside on this submit after we get to implementing the Flash Consideration kernel in triton. The flash consideration paper additionally has some actually good introduction to this.
Moreover, after we have a look at the steps concerned in executing this algorithm and its sample of accessing the gradual HBM, (which as defined later within the submit might be a serious bottleneck as properly) we discover a couple of issues:
- Now we have Q, Ok and V within the HBM initially
- We have to entry Q and Ok initially from the HBM to compute the dot product
- We write the output scores again to the HBM
- We entry it once more to execute the softmax, and optionally for Causal consideration, like within the case of LLMs, we must masks this output earlier than the softmax. The ensuing full consideration matrix is written once more into the HBM
- We entry the HBM once more to execute the ultimate dot product, to get each the eye weights and the Worth matrix to put in writing the output again to the gradual GPU reminiscence
I believe you get the purpose. We may neatly learn and write from the HBM to keep away from redundant operations, to make some potential positive factors. That is precisely the first motivation for the unique Flash Consideration algorithm.
Flash Consideration initially got here out in 2022 [2], after which a 12 months later got here out with some a lot wanted enhancements in 2023 as Flash Consideration v2 [3] and once more in 2024 with further enhancements for Nvidia Hopper and Blackwell GPUs [4] as Flash Consideration v3 [5]. The unique consideration paper recognized that the eye operation remains to be restricted by reminiscence bandwidth moderately than compute. (Prior to now, there have been makes an attempt to scale back the computation complexity of Consideration from O(N**2) to O(NlogN) and decrease by approximate algorithms)
Flash consideration proposed a fused kernel which does all the above consideration operations in a single go, block-wise, to get the ultimate consideration output with out ever having to comprehend the total N**2 consideration matrix in reminiscence, making the algorithm considerably sooner. The time period `fused` merely means we mix a number of operations within the GPU SRAM earlier than invoking the a lot slower journey throughout the slower GPU reminiscence, making the algorithm performant. All of the whereas offering the precise consideration output with none approximations.
This lecture, from Stanford CS139, demonstrates brilliantly how we will consider the influence of a properly thought out reminiscence entry sample can have on an algorithm. I extremely suggest you test this one out should you haven’t already.
Earlier than we begin diving into flash consideration to name it FA, we could?) in triton there’s something else that I wished to get out of the way in which.
Numerical Stability in exponents
Let’s take the instance of FP32 numbers. float32 (normal 32-bit float) makes use of 1 signal bit, 8 exponent bits, and 23 mantissa bits [6]. The most important finite base for the exponent in float32 is 2127≈1.7×1038. Which means after we have a look at exponents, e88 ≈ 1.65×1038, something near 88 (though in actuality could be a lot decrease to maintain it secure) and we’re in bother as we may simply overflow. Right here’s a very fascinating chat with OpenAI o1 shared by of us at AllenAI of their OpenInstruct repo. This though is speaking about stabilizing KL Divergence calculations within the setting of RLHF/RL, the concepts translate precisely to exponents as properly. So to cope with the softmax scenario in consideration what we do is the next:

TRICK : Let’s additionally observe the next, should you do that:

then you may rescale/readjust values with out affecting the ultimate softmax worth. That is actually helpful when you’ve an preliminary estimate for the utmost worth, however which may change after we encounter a brand new set of values. I do know I do know, stick with me and let me clarify.
Setting the scene
Let’s take a small detour into matrix multiplication.

This exhibits a toy instance of a blocked matrix multiplication besides we have now blocks solely on the rows of A (inexperienced) and columns of B (Orange? Beige?). As you may see above the output O1, O2, O3 and O4 are full (these positions want no extra calculations). We simply must fill within the remaining columns within the preliminary rows through the use of the remaining columns of B. Like under:

So we will fill these locations within the output with a block of columns from B and a block of rows from A at a time.
Connecting the dots
After I launched FA, I stated that we by no means should compute the total consideration matrix and retailer the entire thing. So right here’s what we do:
- Compute a block of the eye matrix utilizing a block of rows from Q and a block of columns from Ok. When you get the partial consideration matrix compute a couple of statistics and hold it within the reminiscence.

I’ve greyed O5 to O12 as a result of we don’t know these values but, as they should come from the next blocks. We then rework Sb like under:


Now you’ve setup for a partial softmax

However:
- What if the true most is within the Oi’s which might be but to come back?
- The sum remains to be native, so we have to replace this each time we see new Pi’s. We all know the right way to hold monitor of a sum, however what about rebasing it to the true most?
Recall the trick above. All that we have now to do is to maintain a monitor of the utmost values we encounter for every row, and iteratively replace as you see new maximums from the remaining blocks of columns from Ok for a similar set of rows from Q.


We nonetheless don’t wish to write our partial softmax matrix into HBM. We hold it for the subsequent step.
The ultimate dot product
The final step in our consideration computation is our dot product with V. To begin we’d have initialized a matrix stuffed with 0’s in our HBM as our output of form NxD. The place N is the variety of Queries as above. We use the identical block dimension for V as we had for Ok besides we will apply it row clever like under (The subscripts simply denote that that is solely a block and never the total matrix)


Discover how we’d like the eye scores from all of the blocks to get the ultimate product. But when we calculate the native rating and `accumulate` it like how we did to get the precise Ls we will type the total output on the finish of processing all of the blocks of columns (Okb) for a given row block (Qb).
Placing all of it collectively
Let’s put all these concepts collectively to type the ultimate algorithm

To grasp the notation, _ij implies that it’s the native values for a given block of columns and rows and _i implies it’s for the worldwide output rows and Question blocks. The one half we haven’t defined to date is the ultimate replace to Oi. That’s the place we use all of the concepts from above to get the correct scaling.
The entire code is accessible as a gist right here.
Let’s see what these initializations seem like in torch:
def flash_attn_v1(Q, Ok, V, Br, Bc):
"""Flash Consideration V1"""
B, N, D = Q.form
M = Ok.form[1]
Nr = int(np.ceil(N/Br))
Nc = int(np.ceil(N/Bc))
Q = Q.to('cuda')
Ok = Ok.to('cuda')
V = V.to('cuda')
batch_stride = Q.stride(0)
O = torch.zeros_like(Q).to('cuda')
lis = torch.zeros((B, Nr, int(Br)), dtype=torch.float32).to('cuda')
mis = torch.ones((B, Nr, int(Br)), dtype=torch.float32).to('cuda')*-torch.inf
grid = (B, )
flash_attn_v1_kernel[grid](
Q, Ok, V,
N, M, D,
Br, Bc,
Nr, Nc,
batch_stride,
Q.stride(1),
Ok.stride(1),
V.stride(1),
lis, mis,
O,
O.stride(1),
)
return OIn case you are uncertain concerning the launch grid, checkout my introduction to Triton
Take a more in-depth have a look at how we initialized our Ls and Ms. We’re preserving one for every row block of Output/Question, every of dimension Br. There are Nr such blocks in complete.
Within the instance above I used to be merely utilizing Br = 2 and Bc = 2. However within the above code the initialization is predicated on the machine capability. I’ve included the calculation for a T4 GPU. For some other GPU, we have to get the SRAM capability and modify these numbers accordingly. Now for the precise kernel implementation:
# Flash Consideration V1
import triton
import triton.language as tl
import torch
import numpy as np
import pdb
@triton.jit
def flash_attn_v1_kernel(
Q, Ok, V,
N: tl.constexpr, M: tl.constexpr, D: tl.constexpr,
Br: tl.constexpr,
Bc: tl.constexpr,
Nr: tl.constexpr,
Nc: tl.constexpr,
batch_stride: tl.constexpr,
q_rstride: tl.constexpr,
k_rstride: tl.constexpr,
v_rstride: tl.constexpr,
lis, mis,
O,
o_rstride: tl.constexpr):
"""Flash Consideration V1 kernel"""
pid = tl.program_id(0)
for j in vary(Nc):
k_offset = ((tl.arange(0, Bc) + j*Bc) * k_rstride)[:, None] + (tl.arange(0, D))[None, :] + pid * M * D
# Utilizing k_rstride and v_rstride as we're trying on the whole row directly, for every ok v block
v_offset = ((tl.arange(0, Bc) + j*Bc) * v_rstride)[:, None] + (tl.arange(0, D))[None, :] + pid * M * D
k_mask = k_offset < (pid + 1) * M*D
v_mask = v_offset < (pid + 1) * M*D
k_load = tl.load(Ok + k_offset, masks=k_mask, different=0)
v_load = tl.load(V + v_offset, masks=v_mask, different=0)
for i in vary(Nr):
q_offset = ((tl.arange(0, Br) + i*Br) * q_rstride)[:, None] + (tl.arange(0, D))[None, :] + pid * N * D
q_mask = q_offset < (pid + 1) * N*D
q_load = tl.load(Q + q_offset, masks=q_mask, different=0)
# Compute consideration
s_ij = tl.dot(q_load, tl.trans(k_load))
m_ij = tl.max(s_ij, axis=1, keep_dims=True)
p_ij = tl.exp(s_ij - m_ij)
l_ij = tl.sum(p_ij, axis=1, keep_dims=True)
ml_offset = tl.arange(0, Br) + Br * i + pid * Nr * Br
m = tl.load(mis + ml_offset)[:, None]
l = tl.load(lis + ml_offset)[:, None]
m_new = tl.the place(m < m_ij, m_ij, m)
l_new = tl.exp(m - m_new) * l + tl.exp(m_ij - m_new) * l_ij
o_ij = tl.dot(p_ij, v_load)
output_offset = ((tl.arange(0, Br) + i*Br) * o_rstride)[:, None] + (tl.arange(0, D))[None, :] + pid * N * D
output_mask = output_offset < (pid + 1) * N*D
o_current = tl.load(O + output_offset, masks=output_mask)
o_new = (1/l_new) * (l * tl.exp(m - m_new) * o_current + tl.exp(m_ij - m_new) * o_ij)
tl.retailer(O + output_offset, o_new, masks=output_mask)
tl.retailer(mis + ml_offset, tl.reshape(m_new, (Br,)))
tl.retailer(lis + ml_offset, tl.reshape(l_new, (Br,)))Let’s perceive whats occurring right here:
- Create 1 kernel for every NxD matrix within the batch. In actuality we’d have yet another dimension to parallelize throughout, the pinnacle dimension. However for understanding the implementation I believe this is able to suffice.
- In every kernel we do the next:
- For every block of columns in Ok and V we load up the related a part of the matrix (Bc x D) into the GPU SRAM (Present complete SRAM utilization = 2BcD). This stays within the SRAM until we’re achieved with all of the row blocks
- For every row block of Q, we load the block onto SRAM as properly (Present complete SRAM Utilization = 2BcD + BrD)
- On chip we compute the dot product (sij), compute the native row-maxes (mij), the exp (pij), and the expsum (lij)
- We load up the operating stats for the ith row block. Two vectors of dimension Br x 1, which denotes the present international row-maxes (mi) and the expsum (li). (Present SRAM utilization: 2BcD + BrD + 2Br)
- We get the brand new estimates for the worldwide mi and li.
- We load the a part of the output for this block of Q and replace it utilizing the brand new operating stats and the exponent trick, we then write this again into the HBM. (Present SRAM utilization: 2BcD + 2BrD + 2Br)
- We write the up to date operating stats additionally into the HBM.
- For a matrix of any dimension, aka any context size, at a time we’ll by no means materialize the total consideration matrix, solely part of it at all times.
- We managed to fuse collectively all of the ops right into a single kernel, decreasing HBM entry significantly.
Ultimate SRAM utilization stands though at 4BD + 2B, the place B was initially calculated as M/4d the place M is the SRAM capability. Undecided if am lacking one thing right here. Please remark if you already know why that is the case!
Block Sparse Consideration and V2 and V3
I’ll hold this quick as these variations hold the core thought however discovered higher and higher methods to do the identical.
For Block Sparse Consideration,
- Take into account we had masks for every block like within the case of causal consideration. If for a given block we have now the masks all set to zero then we will merely skip your entire block with out computing something actually. Saving FLOPs. That is the place the foremost positive factors had been seen. To place this into perspective, within the case of BERT pre-training the algorithm will get a 15% increase over the most effective performing coaching setup on the time, whereas for GPT-2 we get a 3x over huggingface coaching implementation and ~ 2x over a Megatron setup.

2. You may actually get the identical efficiency in GPT2 in a fraction of the time, actually shaving off days from the coaching run, which is superior!
In V2:
- Discover how presently we will solely do parallelization on the batch and head dimension. However should you merely simply flip the order to have a look at all of the column blocks for a given row block then we get the next benefits:
- Every row block turns into embarrassingly parallel. How you already know that is by trying on the illustrations above. You want all of the column blocks for a given row block to completely type the eye output. In the event you had been to run all of the column blocks in parallel, you’ll find yourself with a race situation that may attempt to replace the identical rows of the output on the identical time. However not should you do it the opposite approach round. Though there are atomic add operators in triton which may assist, they could probably set us again.
- We are able to keep away from hitting the HBM to get the worldwide Ms and Ls. We are able to initialize one on the chip for every kernel.
- Additionally we don’t have to scale all of the output replace phrases with the brand new estimate of L. We are able to simply compute stuff with out dividing by L and on the finish of all of the column blocks, merely divide the output with the most recent estimate of L, saving some FLOPS once more!
- A lot of the advance additionally comes within the type of the backward kernel. I’m omitting all of the backward kernels from this. However they’re a enjoyable train to try to implement, though they’re considerably extra complicated.
Listed below are some benchmarks:
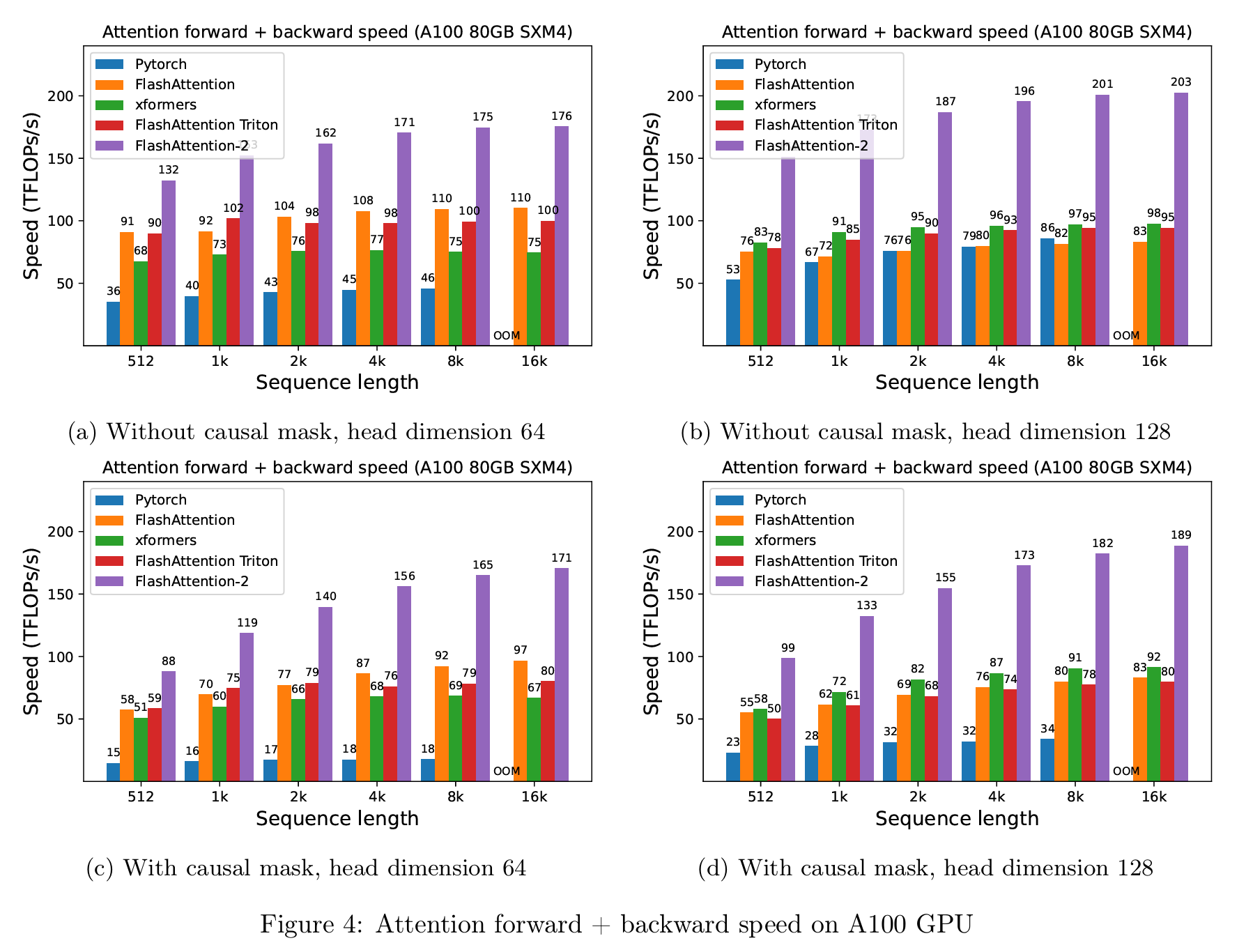
The precise implementations of those kernels must have in mind numerous nuances that we encounter in the actual world. I’ve tried to maintain it easy. However do test them out right here.
Extra lately in V3:
- Newer GPUs, particularly the Hopper and Blackwell GPUs, have low precision modes (FP8 in Hopper and GP4 in Blackwell), which may double and quadruple the throughput for a similar energy and chip space and extra specialised GEMM (Common Matrix Multiply) kernels, which the earlier model of the algorithm fails to capitalize on. It is because there are various operations that are non-GEMM, like softmax, which reduces the utilization of those specialised GPU kernels.
- The FA v1 and v2 are primarily synchronous. Recall within the v2 description I discussed that we’re restricted when column blocks attempt to write to the identical output pointers, or when we have now to go step-by-step utilizing the output from the earlier steps. Properly these fashionable GPUs could make use particular directions to interrupt this synchrony.
We overlap the comparatively low-throughput non-GEMM operations concerned in softmax, similar to floating level multiply-add and exponential, with the asynchronous WGMMA directions for GEMM. As a part of this, we rework the FlashAttention-2 algorithm to avoid sure sequential dependencies between softmax and the GEMMs. For instance, within the 2-stage model of our algorithm, whereas softmax executes on one block of the scores matrix, WGMMA executes within the asynchronous proxy to compute the subsequent block.
Flash Consideration v3, Shah et.al
- In addition they tailored the algorithm to focus on these specialised low precision Tensor cores on these new units, considerably growing the FLOPs.
Some extra benchmarks:
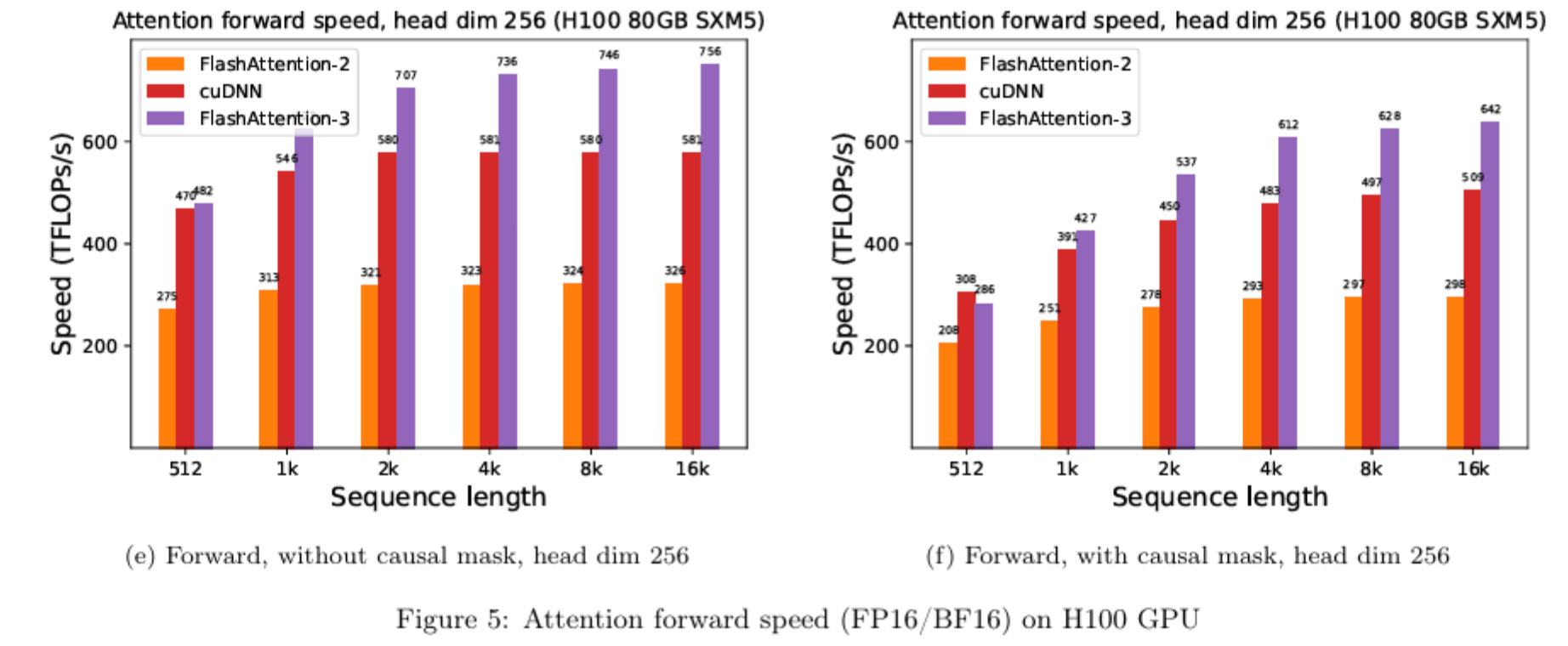
Conclusion
There may be a lot to admire of their work right here. The ground for this technical talent degree usually appeared excessive owing to the low degree particulars. However hopefully instruments like Triton may change the sport and get extra individuals into this! The longer term is vivid.
References
[1] Qwen 2.5-7B-Instruct-1M Huggingface Mannequin Web page
[2] Tri Dao, Daniel Y. Fu, Stefano Ermon, Atri Rudra, and Christopher Re, FlashAttention: Quick and Reminiscence-Environment friendly Actual Consideration with IO-Consciousness
[3] Tri Dao, FlashAttention-2: Sooner Consideration with Higher Parallelism and Work Partitioning
[4] NVIDIA Hopper Structure Web page
[5] Jay Shah, Ganesh Bikshandi, Ying Zhang, Vijay Thakkar, Pradeep Ramani, Tri Dao, FlashAttention-3: Quick and Correct Consideration with Asynchrony and Low-precision


{kind=link}