
Regardless of the AI hype, many tech firms nonetheless rely closely on machine studying to energy vital functions, from personalised suggestions to fraud detection.
I’ve seen firsthand how undetected drifts may end up in vital prices — missed fraud detection, misplaced income, and suboptimal enterprise outcomes, simply to call a number of. So, it’s essential to have strong monitoring in place if your organization has deployed or plans to deploy machine studying fashions into manufacturing.
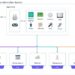
Undetected Mannequin Drift can result in vital monetary losses, operational inefficiencies, and even injury to an organization’s status. To mitigate these dangers, it’s necessary to have efficient mannequin monitoring, which entails:
- Monitoring mannequin efficiency
- Monitoring function distributions
- Detecting each univariate and multivariate drifts
A well-implemented monitoring system may also help determine points early, saving appreciable time, cash, and assets.
On this complete information, I’ll present a framework on how to consider and implement efficient Mannequin Monitoring, serving to you keep forward of potential points and guarantee stability and reliability of your fashions in manufacturing.
What’s the distinction between function drift and rating drift?
Rating drift refers to a gradual change within the distribution of mannequin scores. If left unchecked, this might result in a decline in mannequin efficiency, making the mannequin much less correct over time.
However, function drift happens when a number of options expertise modifications within the distribution. These modifications in function values can have an effect on the underlying relationships that the mannequin has realized, and finally result in inaccurate mannequin predictions.
Simulating rating shifts
To mannequin real-world fraud detection challenges, I created an artificial dataset with 5 monetary transaction options.
The reference dataset represents the unique distribution, whereas the manufacturing dataset introduces shifts to simulate a rise in high-value transactions with out PIN verification on newer accounts, indicating a rise in fraud.
Every function has totally different underlying distributions:
- Transaction Quantity: Log-normal distribution (right-skewed with an extended tail)
- Account Age (months): clipped regular distribution between 0 to 60 (assuming a 5-year-old firm)
- Time Since Final Transaction: Exponential distribution
- Transaction Depend: Poisson distribution
- Entered PIN: Binomial distribution.
To approximate mannequin scores, I randomly assigned weights to those options and utilized a sigmoid perform to constrain predictions between 0 to 1. This mimics how a logistic regression fraud mannequin generates danger scores.
As proven within the plot under:
- Drifted options: Transaction Quantity, Account Age, Transaction Depend, and Entered PIN all skilled shifts in distribution, scale, or relationships.

- Steady function: Time Since Final Transaction remained unchanged.

- Drifted scores: Because of the drifted options, the distribution in mannequin scores has additionally modified.

This setup permits us to research how function drift impacts mannequin scores in manufacturing.
Detecting mannequin rating drift utilizing PSI
To watch mannequin scores, I used inhabitants stability index (PSI) to measure how a lot mannequin rating distribution has shifted over time.
PSI works by binning steady mannequin scores and evaluating the proportion of scores in every bin between the reference and manufacturing datasets. It compares the variations in proportions and their logarithmic ratios to compute a single abstract statistic to quantify the drift.
Python implementation:
# Outline perform to calculate PSI given two datasets
def calculate_psi(reference, manufacturing, bins=10):
# Discretize scores into bins
min_val, max_val = 0, 1
bin_edges = np.linspace(min_val, max_val, bins + 1)
# Calculate proportions in every bin
ref_counts, _ = np.histogram(reference, bins=bin_edges)
prod_counts, _ = np.histogram(manufacturing, bins=bin_edges)
ref_proportions = ref_counts / len(reference)
prod_proportions = prod_counts / len(manufacturing)
# Keep away from division by zero
ref_proportions = np.clip(ref_proportions, 1e-8, 1)
prod_proportions = np.clip(prod_proportions, 1e-8, 1)
# Calculate PSI for every bin
psi = np.sum((ref_proportions - prod_proportions) * np.log(ref_proportions / prod_proportions))
return psi
# Calculate PSI
psi_value = calculate_psi(ref_data['model_score'], prod_data['model_score'], bins=10)
print(f"PSI Worth: {psi_value}")Beneath is a abstract of the best way to interpret PSI values:
- PSI < 0.1: No drift, or very minor drift (distributions are virtually an identical).
- 0.1 ≤ PSI < 0.25: Some drift. The distributions are considerably totally different.
- 0.25 ≤ PSI < 0.5: Average drift. A noticeable shift between the reference and manufacturing distributions.
- PSI ≥ 0.5: Vital drift. There’s a massive shift, indicating that the distribution in manufacturing has modified considerably from the reference information.

The PSI worth of 0.6374 suggests a major drift between our reference and manufacturing datasets. This aligns with the histogram of mannequin rating distributions, which visually confirms the shift in direction of increased scores in manufacturing — indicating a rise in dangerous transactions.
Detecting function drift
Kolmogorov-Smirnov take a look at for numeric options
The Kolmogorov-Smirnov (Ok-S) take a look at is my most popular technique for detecting drift in numeric options, as a result of it’s non-parametric, that means it doesn’t assume a traditional distribution.
The take a look at compares a function’s distribution within the reference and manufacturing datasets by measuring the utmost distinction between the empirical cumulative distribution capabilities (ECDFs). The ensuing Ok-S statistic ranges from 0 to 1:
- 0 signifies no distinction between the 2 distributions.
- Values nearer to 1 counsel a better shift.
Python implementation:
# Create an empty dataframe
ks_results = pd.DataFrame(columns=['Feature', 'KS Statistic', 'p-value', 'Drift Detected'])
# Loop via all options and carry out the Ok-S take a look at
for col in numeric_cols:
ks_stat, p_value = ks_2samp(ref_data[col], prod_data[col])
drift_detected = p_value < 0.05
# Retailer ends in the dataframe
ks_results = pd.concat([
ks_results,
pd.DataFrame({
'Feature': [col],
'KS Statistic': [ks_stat],
'p-value': [p_value],
'Drift Detected': [drift_detected]
})
], ignore_index=True)
Beneath are ECDF charts of the 4 numeric options in our dataset:

Let’s take a look at the account age function for instance: the x-axis represents account age (0-50 months), whereas the y-axis exhibits the ECDF for each reference and manufacturing datasets. The manufacturing dataset skews in direction of newer accounts, because it has a bigger proportion of observations with decrease account ages.
Chi-Sq. take a look at for categorical options
To detect shifts in categorical and boolean options, I like to make use of the Chi-Sq. take a look at.
This take a look at compares the frequency distribution of a categorical function within the reference and manufacturing datasets, and returns two values:
- Chi-Sq. statistic: The next worth signifies a better shift between the reference and manufacturing datasets.
- P-value: A p-value under 0.05 means that the distinction between the reference and manufacturing datasets is statistically vital, indicating potential function drift.
Python implementation:
# Create empty dataframe with corresponding column names
chi2_results = pd.DataFrame(columns=['Feature', 'Chi-Square Statistic', 'p-value', 'Drift Detected'])
for col in categorical_cols:
# Get normalized worth counts for each reference and manufacturing datasets
ref_counts = ref_data[col].value_counts(normalize=True)
prod_counts = prod_data[col].value_counts(normalize=True)
# Guarantee all classes are represented in each
all_categories = set(ref_counts.index).union(set(prod_counts.index))
ref_counts = ref_counts.reindex(all_categories, fill_value=0)
prod_counts = prod_counts.reindex(all_categories, fill_value=0)
# Create contingency desk
contingency_table = np.array([ref_counts * len(ref_data), prod_counts * len(prod_data)])
# Carry out Chi-Sq. take a look at
chi2_stat, p_value, _, _ = chi2_contingency(contingency_table)
drift_detected = p_value < 0.05
# Retailer ends in chi2_results dataframe
chi2_results = pd.concat([
chi2_results,
pd.DataFrame({
'Feature': [col],
'Chi-Sq. Statistic': [chi2_stat],
'p-value': [p_value],
'Drift Detected': [drift_detected]
})
], ignore_index=True)The Chi-Sq. statistic of 57.31 with a p-value of three.72e-14 confirms a big shift in our categorical function, Entered PIN. This discovering aligns with the histogram under, which visually illustrates the shift:

Detecting multivariate shifts
Spearman Correlation for shifts in pairwise interactions
Along with monitoring particular person function shifts, it’s necessary to trace shifts in relationships or interactions between options, often called multivariate shifts. Even when the distributions of particular person options stay steady, multivariate shifts can sign significant variations within the information.
By default, Pandas’ .corr() perform calculates Pearson correlation, which solely captures linear relationships between variables. Nonetheless, relationships between options are sometimes non-linear but nonetheless observe a constant pattern.
To seize this, we use Spearman correlation to measure monotonic relationships between options. It captures whether or not options change collectively in a constant route, even when their relationship isn’t strictly linear.
To evaluate shifts in function relationships, we evaluate:
- Reference correlation (
ref_corr): Captures historic function relationships within the reference dataset. - Manufacturing correlation (
prod_corr): Captures new function relationships in manufacturing. - Absolute distinction in correlation: Measures how a lot function relationships have shifted between the reference and manufacturing datasets. Increased values point out extra vital shifts.
Python implementation:
# Calculate correlation matrices
ref_corr = ref_data.corr(technique='spearman')
prod_corr = prod_data.corr(technique='spearman')
# Calculate correlation distinction
corr_diff = abs(ref_corr - prod_corr)Instance: Change in correlation
Now, let’s take a look at the correlation between transaction_amount and account_age_in_months:
- In
ref_corr, the correlation is 0.00095, indicating a weak relationship between the 2 options. - In
prod_corr, the correlation is -0.0325, indicating a weak unfavourable correlation. - Absolute distinction within the Spearman correlation is 0.0335, which is a small however noticeable shift.
Absolutely the distinction in correlation signifies a shift within the relationship between transaction_amount and account_age_in_months.
There was no relationship between these two options, however the manufacturing dataset signifies that there’s now a weak unfavourable correlation, that means that newer accounts have increased transaction quantities. That is spot on!
Autoencoder for advanced, high-dimensional multivariate shifts
Along with monitoring pairwise interactions, we are able to additionally search for shifts throughout extra dimensions within the information.
Autoencoders are highly effective instruments for detecting high-dimensional multivariate shifts, the place a number of options collectively change in ways in which might not be obvious from taking a look at particular person function distributions or pairwise correlations.
An autoencoder is a neural community that learns a compressed illustration of information via two elements:
- Encoder: Compresses enter information right into a lower-dimensional illustration.
- Decoder: Reconstructs the unique enter from the compressed illustration.
To detect shifts, we evaluate the reconstructed output to the authentic enter and compute the reconstruction loss.
- Low reconstruction loss → The autoencoder efficiently reconstructs the information, that means the brand new observations are just like what it has seen and realized.
- Excessive reconstruction loss → The manufacturing information deviates considerably from the realized patterns, indicating potential drift.
In contrast to conventional drift metrics that concentrate on particular person options or pairwise relationships, autoencoders seize advanced, non-linear dependencies throughout a number of variables concurrently.
Python implementation:
ref_features = ref_data[numeric_cols + categorical_cols]
prod_features = prod_data[numeric_cols + categorical_cols]
# Normalize the information
scaler = StandardScaler()
ref_scaled = scaler.fit_transform(ref_features)
prod_scaled = scaler.rework(prod_features)
# Cut up reference information into practice and validation
np.random.shuffle(ref_scaled)
train_size = int(0.8 * len(ref_scaled))
train_data = ref_scaled[:train_size]
val_data = ref_scaled[train_size:]
# Construct autoencoder
input_dim = ref_features.form[1]
encoding_dim = 3
# Enter layer
input_layer = Enter(form=(input_dim, ))
# Encoder
encoded = Dense(8, activation="relu")(input_layer)
encoded = Dense(encoding_dim, activation="relu")(encoded)
# Decoder
decoded = Dense(8, activation="relu")(encoded)
decoded = Dense(input_dim, activation="linear")(decoded)
# Autoencoder
autoencoder = Mannequin(input_layer, decoded)
autoencoder.compile(optimizer="adam", loss="mse")
# Prepare autoencoder
historical past = autoencoder.match(
train_data, train_data,
epochs=50,
batch_size=64,
shuffle=True,
validation_data=(val_data, val_data),
verbose=0
)
# Calculate reconstruction error
ref_pred = autoencoder.predict(ref_scaled, verbose=0)
prod_pred = autoencoder.predict(prod_scaled, verbose=0)
ref_mse = np.imply(np.energy(ref_scaled - ref_pred, 2), axis=1)
prod_mse = np.imply(np.energy(prod_scaled - prod_pred, 2), axis=1)The charts under present the distribution of reconstruction loss between each datasets.

The manufacturing dataset has a better imply reconstruction error than that of the reference dataset, indicating a shift within the general information. This aligns with the modifications within the manufacturing dataset with a better variety of newer accounts with high-value transactions.
Summarizing
Mannequin monitoring is a necessary, but typically ignored, accountability for information scientists and machine studying engineers.
All of the statistical strategies led to the identical conclusion, which aligns with the noticed shifts within the information: they detected a pattern in manufacturing in direction of newer accounts making higher-value transactions. This shift resulted in increased mannequin scores, signaling a rise in potential fraud.
On this put up, I coated strategies for detecting drift on three totally different ranges:
- Mannequin rating drift: Utilizing Inhabitants Stability Index (PSI)
- Particular person function drift: Utilizing Kolmogorov-Smirnov test for numeric options and Chi-Sq. take a look at for categorical options
- Multivariate drift: Utilizing Spearman correlation for pairwise interactions and autoencoders for high-dimensional, multivariate shifts.
These are just some of the strategies I depend on for complete monitoring — there are many different equally legitimate statistical strategies that may additionally detect drift successfully.
Detected shifts typically level to underlying points that warrant additional investigation. The foundation trigger might be as critical as a knowledge assortment bug, or as minor as a time change like daylight financial savings time changes.
There are additionally improbable python packages, like evidently.ai, that automate many of those comparisons. Nonetheless, I consider there’s vital worth in deeply understanding the statistical strategies behind drift detection, reasonably than relying solely on these instruments.
What’s the mannequin monitoring course of like at locations you’ve labored?
Wish to construct your AI expertise?
👉🏻 I run the AI Weekender and write weekly weblog posts on information science, AI weekend initiatives, profession recommendation for professionals in information.


{kind=link}