Advantageous-tuning a pre-trained giant language mannequin (LLM) permits customers to customise the mannequin to carry out higher on domain-specific duties or align extra carefully with human preferences. It’s a steady course of to maintain the fine-tuned mannequin correct and efficient in altering environments, to adapt to the information distribution shift (idea drift) and forestall efficiency degradation over time. Steady fine-tuning additionally permits fashions to combine human suggestions, deal with errors, and tailor to real-world purposes. You should use supervised fine-tuning (SFT) and instruction tuning to coach the LLM to carry out higher on particular duties utilizing human-annotated datasets and directions. When you could have consumer suggestions to the mannequin responses, it’s also possible to use reinforcement studying from human suggestions (RLHF) to information the LLM’s response by rewarding the outputs that align with human preferences.
Exact and accountable outputs from fine-tuned LLMs require huge efforts from material specialists (SMEs). The guide annotation of intensive coaching knowledge for fine-tuning by human SMEs and accumulating consumer suggestions to align LLM responses with human preferences are each resource-heavy and time-intensive. Additionally, the continual fine-tuning course of requires orchestrating the a number of steps of knowledge era, LLM coaching, suggestions assortment, and desire alignments with scalability, resiliency, and useful resource effectivity. To handle these challenges, we current an modern steady self-instruct fine-tuning framework that streamlines the LLM fine-tuning course of of coaching knowledge era and annotation, mannequin coaching and analysis, human suggestions assortment, and alignment with human desire. This framework is designed as a compound AI system to drive the fine-tuning workflow for efficiency enchancment, versatility, and reusability.
On this submit, we introduce the continual self-instruct fine-tuning framework and its pipeline, and current tips on how to drive the continual fine-tuning course of for a question-answer job as a compound AI system. We use DSPy (Declarative Self-improving Python) to display the workflow of Retrieval Augmented Era (RAG) optimization, LLM fine-tuning and analysis, and human desire alignment for efficiency enchancment.
Overview of the continual self-instruct fine-tuning framework
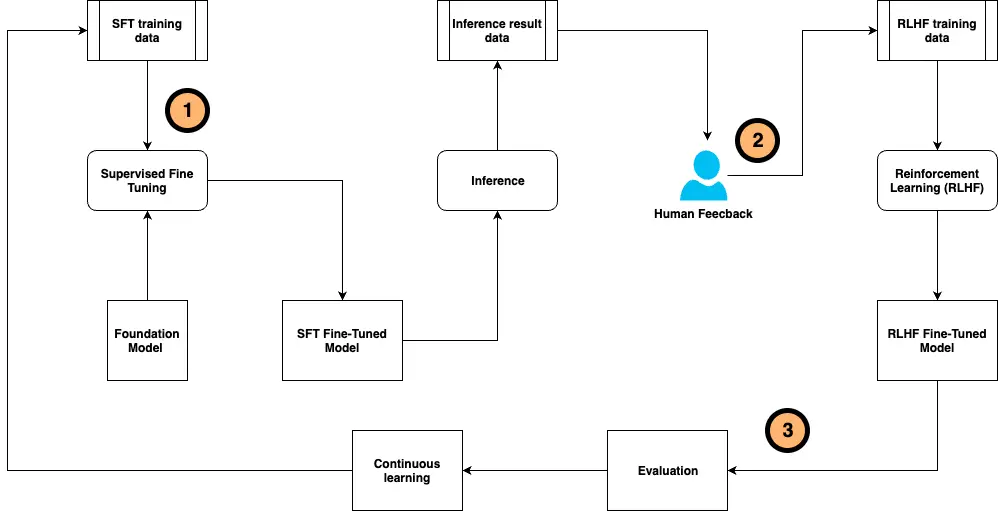
The continual self-instruct fine-tuning framework drives a workflow to customise the muse mannequin (FM) utilizing human-labeled coaching samples and human suggestions after mannequin inference. This workflow runs on a steady foundation to be adaptive to a altering setting. The next diagram illustrates the workflow.

The workflow consists of the next steps:
- Self-instruct supervised fine-tuning – First, we use a human-labeled coaching dataset to adapt the FM to duties in a particular area. Instruction tuning is a well-liked strategy in domain-specific LLM fine-tuning, which trains the FM to comply with directions for a particular job quite than producing the subsequent texts. To handle the challenges of the dearth of human efforts for knowledge labeling, annotation, and validation, we designed a self-instruct fine-tuning technique to synthetically generate coaching labels by the LLM from a small quantity of high-quality human-annotated samples. This course of scales up the coaching dataset used for fine-tuning the FM right into a customized LLM.
- Human desire alignment – After the mannequin is deployed within the manufacturing setting, the method strikes into the human-in-the-loop workflow, wherein we acquire consumer suggestions together with satisfaction scores and feedback on mannequin response. The human suggestions knowledge will not be solely used for mannequin efficiency and hallucination measurement, however can also be used to additional fine-tune the customized mannequin in Step 1 by means of RLHF. Likewise, to handle the challenges of lack of human suggestions knowledge, we use LLMs to generate AI grades and suggestions that scale up the dataset for reinforcement studying from AI suggestions (RLAIF). There are numerous strategies of desire alignment, together with proximal coverage optimization (PPO), direct desire optimization (DPO), odds ratio coverage optimization (ORPO), group relative coverage optimization (GRPO), and different algorithms, that can be utilized on this course of.
- Analysis and steady studying – The mannequin customization and desire alignment will not be a one-time effort. We have to preserve monitoring and evaluating the mannequin efficiency, and restart the method in case of idea shift or mannequin decay.
The general workflow consists of a number of steps of artificial knowledge era, LLM coaching, suggestions assortment, desire alignment, and analysis that entails a number of elements and a number of LLMs. Within the subsequent part, we talk about utilizing a compound AI system to implement this framework to attain excessive versatility and reusability.
Compound AI system and the DSPy framework
With the rise of generative AI, scientists and engineers face a way more advanced situation to develop and preserve AI options, in comparison with basic predictive AI. The paper The Shift from Fashions to Compound AI Techniques highlights that state-of-the-art AI outcomes are more and more obtained by compound methods with a number of elements, not simply monolithic fashions. Compound AI methods are methods that implement AI duties by combining a number of interacting elements. These elements can embrace a number of calls to fashions, retrievers, or exterior instruments. The next diagram compares predictive AI to generative AI.

The idea of a compound AI system permits knowledge scientists and ML engineers to design subtle generative AI methods consisting of a number of fashions and elements. You should use a module to include immediate engineering and in-context studying to enhance RAG efficiency, and in addition design an information structure with instruments to assemble exterior knowledge. You may also construct an agentic structure with a number of LLMs, fine-tune the mannequin to attain increased efficiency, and orchestrate the LLM entry. In addition to the effectivity in system design, the compound AI system additionally lets you optimize advanced generative AI methods, utilizing a complete analysis module based mostly on a number of metrics, benchmarking knowledge, and even judgements from different LLMs. The optimization is on the holistic end-to-end answer, quite than on every element individually.
To effectively construct and optimize compound AI methods, we introduce DSPy, an open supply Python framework for builders to construct LLM purposes utilizing modular and declarative programming, whether or not you’re constructing easy classifiers, subtle RAG pipelines, or agentic workflows. It supplies algorithms for optimizing LLMs’ prompts and weights, and automates the immediate tuning course of, versus the trial-and-error strategy carried out by people. DSPy helps iteratively optimizing all prompts concerned in opposition to outlined metrics for the end-to-end compound AI answer.
The DSPy lifecycle is offered within the following diagram in seven steps. It separates the circulate of your program (modules) from the parameters (language mannequin prompts and weights) of every step. These modules outline the system conduct in a conveyable, declarative manner. The primary 4 steps cowl the DSPy programming stage, together with defining your job and its constraints, exploring just a few examples, and utilizing that to tell your preliminary pipeline design. When your system works moderately nicely, you’ll be able to run the DSPy analysis stage (Steps 5 and 6) to gather an preliminary improvement set, outline your DSPy metric, and use these to iterate in your system extra systematically. Afterwards, DSPy introduces new optimizers (compilers) in Step 7, with language model-driven algorithms to tune LLM prompts and weights, based mostly on predefined analysis metrics.

RAG pipeline with steady fine-tuning in a compound AI system
On this submit, we offer an instance of a question-answer job, utilizing a RAG pipeline together with the continual self-instruct fine-tuning framework. We construct this as a compound AI system and use DSPy to drive the RAG inference, immediate optimization, LLM fine-tuning, and efficiency analysis. The general workflow is proven within the following diagram.

The circulate begins from a normal RAG pipeline, adopted by just a few optimizations on the prompts and the RAG retriever. Then we generate the artificial coaching dataset from the RAG information base to fine-tune the generator LLM utilizing RAG for efficiency enchancment. Lastly, we use a separate LLM to generate suggestions on the fine-tuned mannequin responses, and use it to conduct the desire alignment coaching by DPO and PPO. The question-answer outputs from every step are measured by the underlying LLM-as-a-judge analysis module. On this manner, we display the effectiveness of the compound AI system for the continual optimizing of the pipeline by means of RAG optimization and the fine-tuning framework.
Within the subsequent sections, we display tips on how to construct this workflow, together with the RAG pipeline, optimization, instruction fine-tuning, desire alignment, and mannequin analysis, right into a compound AI system utilizing an Amazon SageMaker pocket book occasion with the DSPy framework and LLMs on Amazon Bedrock. The code from this submit and extra examples can be found within the GitHub repository.
Conditions
To create and run this compound AI system in your AWS account, full the next conditions:
- Create an AWS account should you don’t have already got one.
- Arrange a SageMaker pocket book occasion.
- Open JupyterLab on this newly created occasion.
- Clone the GitHub repository and comply with the steps defined within the README.
- Navigate to the cloned repository and open the pocket book folder.
- Allow entry to fashions hosted on Amazon Bedrock. For this submit, we allow Anthropic’s Claude 3 Sonnet, Mistral 7B, and Meta Llama 8B.
Dataset
For the question-answering job, we use the Contract Understanding Atticus Dataset (CUAD), an open authorized contract evaluation dataset created with dozens of authorized specialists from The Atticus Undertaking, which consists of over 13,000 annotations. The artificial knowledge era pocket book robotically downloads the CUAD_v1 ZIP file and locations it within the required folder named cuad_data.
In case of any points, you’ll be able to alternately obtain the dataset your self by following the steps within the README file and retailer the dataset inside a folder inside the SageMaker pocket book occasion, and use it to carry out the steps within the subsequent part.
Put together question-answer pairs
Step one is to arrange question-answer pairs from the CUAD doc by working artificial knowledge era.
We use Anthropic’s Claude v3 Sonnet on Amazon Bedrock to synthetically generate question-answer pairs to deduce the RAG pipeline within the compound AI system, to display the improved accuracy after RAG optimization and mannequin fine-tuning. The generated datasets are within the format of question-answer pairs together with the context [context, question, answer] from the doc. We use the query to deduce the RAG pipeline and use the reply as floor fact to judge the inference accuracy. Moreover, the question-answer pairs are used as coaching samples for the mannequin fine-tuning. The next is a pattern dataset triplet with context and a question-answer pair.
| Context (Snippet from PDF file) | Query | Reply |
|
THIS STRATEGIC ALLIANCE AGREEMENT (“Settlement”) is made and entered into as of November 6, 2016 (the “Efficient Date”) by and between Dialog Semiconductor (UK) Ltd., a company organized below the legal guidelines of England and Wales, having its principal workplace at 100 Longwater Avenue, Inexperienced Park, Studying, RG2 6GP, United Kingdom (“DIALOG”) and Energous Company, a Delaware company, having its principal workplace at 3590 North First Avenue, Suite 210, San Jose, CA 95134 (“ENERGOUS”) |
What’s the date of the contract? | November 6, 2016 |
Create a RAG pipeline
We implement a normal RAG pipeline with DSPy utilizing the next elements to create the vector database, arrange context retrieval, and generate the reply:
- Configure DSPy to make use of LLMs on Amazon Bedrock because the RAG generator mannequin:
- Course of the dataset to generate logical and syntactically readable chunks. The scale and overlap proportion could be empirically decided based mostly on the dataset. For extra flexibility, you’ll be able to generate a number of information from the dataset file and make one file one chunk.
- To arrange a RAG retriever, we choose ChromaDB as a vector retailer, and use DSPy’s ChromadbRM module because the retriever mannequin:
- Utilizing these elements, we orchestrate a DSPy RAG pipeline to scrub the context, generate the reply, and use the LLM-as-a-judge to attain the generated reply with respect to the bottom fact:
RAG optimization with DSPy
The subsequent step is to carry out RAG optimization with DSPy. DSPy supplies the Optimizer module, an algorithm that may tune the parameters of a DSPy program (the prompts and language mannequin weights) to maximise the metrics you specify. It takes in a coaching set to bootstrap the selective coaching examples, and relies on a metric operate that measures proximity to or matches in opposition to the bottom fact. With these, we will compile the RAG pipeline module with an outlined optimizer occasion to conduct the optimization.
On this submit, we use DSPy Optimizer to discover ways to generate the immediate to enhance the RAG response accuracy. As a result of our dataset measurement is low (fewer than 100 examples), we choose the BootstrapFewShot teleprompter to compile the RAG prompts and general pipeline, and use the artificial dataset with floor fact and the LLM-as-a-judge metric operate we outlined within the earlier sections:
The context retrieval is essential to the general RAG accuracy. To judge the RAG optimization we’ve described, we create a retriever analysis by the LLM-as-a-judge to grasp how nicely the retriever is ready to pull out the related chunks for the incoming consumer query. The LLM choose is outlined within the RetrievalJudge class:
Then we outline the metric to measure the retrieval through the use of the RetrievalJudge, and use the DSPy Consider module to generate the accuracy rating for retrieval:
Configure the continual fine-tuning framework
After the RAG optimization, the compound AI system has the instruction tuning and desire alignment modules, pushed by the continual fine-tuning framework. This contains utilizing the synthetically generated dataset to coach the LLM to comply with question-answer directions by SFT, and producing suggestions of RAG responses by AI (one other LLM) used for RLAIF with PPO and desire alignment with DPO and ORPO. On this step, we use Parameter Environment friendly Advantageous-Tuning (PEFT) with Low-Rank Adaptation (LoRA) to cut back the requirement of compute sources and speed up the coaching course of.
On the time of writing, the DSPy Optimization module helps distillation of a prompt-based DSPy program into LLM weight updates utilizing BootstrapFinetune, and doesn’t but help the fine-tuning strategies we outlined within the compound AI system. Due to this fact, we performed the fine-tuning (instruction tuning and desire alignment) on a Meta Llama 3 8B mannequin individually; confer with the next GitHub repository for extra particulars. With the compound AI system design, we’re capable of take the fine-tuning outcomes again into the DSPy pipeline, use the LLM-as-a-judge analysis operate to generate the accuracy scores, and benchmark with the usual and optimized RAG inferences. This demonstrates the flexibleness and interoperability of the compound AI system, which permits us to seamlessly change one module with an exterior element with out requiring modifications to your complete pipeline.
The next diagram illustrates the workflow.

Outline an analysis strategy with DSPy
DSPy supplies an Consider module for evaluating the compound AI system output through the use of user-defined metrics. On this submit, we use LLM-as-a-judge to judge the system output and create the corresponding metrics for benchmarking the accuracy of normal RAG, optimized RAG, and fine-tuned fashions. Full the next steps:
- Load the dataset for analysis within the Instance knowledge kind. Examples are much like Python dictionaries however with added utilities such because the dspy.Prediction as a return worth. For instance:
- Outline the LLM-as-a-judge class to adjudicate whether or not the anticipated reply semantically matches the bottom fact of the reply. For instance, the next FactualityJudge_1 class supplies a rating between 0 and 1; 0 means a whole mismatch and 1 means an ideal match.
- Outline the analysis metrics from the LLM choose, utilizing DSPy metrics, to mark whether or not the anticipated reply is true or not. For instance, the next operate returns the accuracy rating based mostly on the output of FactualityJudge_1:
- Use the
dspy.Considermodule to generate an accuracy rating utilizing the LLM-as-a-judge metrics outlined within the earlier step:
This analysis course of ought to be performed on a steady foundation within the compound AI system pushed by self-instruct fine-tuning, to ensure the general efficiency stays steady regardless of the modifications within the setting or the introduction of recent knowledge.
Benchmark RAG and LLM fine-tuning with DSPy
We benchmark the approaches offered on this submit utilizing the LLM-as-a-judge analysis operate outlined within the earlier part with the next settings.
The benchmarking is throughout 5 strategies: customary RAG, optimized RAG, fine-tuning LLMs by instruction tuning, and fine-tuning LLMs by DPO and ORPO educated LLMs based mostly on AIF. For every technique, the LLM choose supplies a decimal accuracy rating within the vary of 0 and 1.
The usual RAG makes use of Amazon Titan Textual content Embedding V2 for the embedding mannequin, and Anthropic’s Claude 3 Haiku mannequin for the generator mannequin. The RAG compilation makes use of 32 question-answer pairs to optimize the prompts. The identical dataset is used for inference. The fine-tuning by SFT, DPO, and ORPO are carried out on the Meta Llama 3 8B FM, utilizing coaching samples synthetically generated from CUAD doc.
The outcomes are offered within the following tables and charts. The completely different strategies display completely different ranges of enchancment. The advance is calculated in proportion by (accuracy of recent technique – accuracy of normal RAG)/(accuracy of normal RAG)*100%.
The optimized RAG by DSPy improved the accuracy and decreased the hallucination.
| Normal RAG with Claude 3 Haiku | RAG with Claude 3 Haiku optimized by DSPy | Enchancment % | |
| Accuracy by LLM Decide (0-1) | 0.3969 | 0.6656 | 67.70% |
| Normal RAG with Claude 3 Sonnet | RAG with Claude 3 Sonnet optimized by DSPy | Enchancment % | |
| Accuracy by LLM Decide (0-1) | 0.3031 | 0.6375 | 110.33% |
The customized LLM educated by SFT yielded increased accuracy than the usual RAG.
| Normal RAG with Claude 3 Haiku | SFT tuned Meta Llama 3 8B | Enchancment % | |
| Accuracy by LLM Decide (0-1) | 0.3969 | 0.4813 | 21.26% |
| Normal RAG with Claude 3 Sonnet | SFT tuned Meta Llama 3 8B | Enchancment % | |
| Accuracy by LLM Decide (0-1) | 0.3031 | 0.4813 | 58.79% |
The customized LLM by means of desire alignment from human and AI suggestions (DPO and ORPO) additional improved the mannequin efficiency. The fine-tuned small measurement mannequin (Meta Llama 3 8B) outperformed the usual RAG pipeline with the medium measurement (Anthropic’s Claude Haiku) and bigger measurement (Anthropic’s Claude Sonnet) generator mannequin, and was comparable with the prompt-optimized RAG utilizing floor fact knowledge.
| Normal RAG with Claude 3 Haiku | DPO tuned Meta Llama 3 8B | Enchancment % | ORPO tuned Meta Llama 3 8B | Enchancment % | |
| Accuracy by LLM Decide (0-1) | 0.3969 | 0.6719 | 69.29% | 0.6812 | 71.63% |
| Normal RAG with Claude 3 Sonnet | DPO tuned Meta Llama 3 8B | Enchancment % | ORPO tuned Meta Llama 3 8B | Enchancment % | |
| Accuracy by LLM Decide (0-1) | 0.3031 | 0.6719 | 121.68% | 0.6812 | 124.74% |
The next charts evaluate the accuracy throughout all examined strategies.

The previous outcomes had been generated from a small dataset (32 question-answer pairs). You should use a bigger pattern set with extra question-answer pairs to conduct the benchmarking and evaluate your individual outcomes.
Clear up
Be sure that to scrub up the next sources to keep away from incurring further prices:
- Delete Amazon Easy Storage Service (Amazon S3) buckets created for knowledge storage and useful resource sharing.
- Again up the Jupyter notebooks within the SageMaker pocket book occasion.
- Shut down and delete the SageMaker pocket book occasion.
Value concerns
Contemplate the next prices from the answer deployed on AWS:
- You’ll incur costs for LLM inference on Amazon Bedrock. For extra particulars, confer with Amazon Bedrock pricing.
- You’ll incur costs for storing information in S3 buckets. For extra particulars, confer with Amazon S3 pricing.
- You’ll incur costs on your SageMaker pocket book occasion. For extra particulars, confer with Amazon SageMaker pricing.
Conclusion
On this submit, we offered the continual self-instruct fine-tuning framework as a compound AI system applied by the DSPy framework. The framework first generates an artificial dataset from the area information base and paperwork for self-instruction, then drives mannequin fine-tuning by means of SFT, and introduces the human-in-the-loop workflow to gather human and AI suggestions to the mannequin response, which is used to additional enhance the mannequin efficiency by aligning human desire by means of reinforcement studying (RLHF/RLAIF).
We demonstrated the framework for a question-answer job with a RAG pipeline, which improved the end-to-end response accuracy. The workflow is applied by the DSPy framework; the general technique is to make use of the dspy.Module to attach all of the elements (RAG pipeline, immediate optimization, LLMs fine-tuned by SFT and RLHF/RLAIF, efficiency analysis) collectively right into a compound AI system. Every module could be seamlessly maintained, up to date, and changed with out affecting different elements within the system. This strong and versatile system design strengthens management and belief by means of modular design, and will increase flexibility and flexibility to altering environments and knowledge sources.
You’ll be able to implement this steady fine-tuning framework for LLM efficiency enchancment on your personal enterprise use circumstances, with a compound AI system that gives excessive flexibility and interoperability. For extra particulars, comply with the examples in our GitHub repository.
In regards to the Authors
 Yunfei Bai is a Principal Options Architect at AWS. With a background in AI/ML, knowledge science, and analytics, Yunfei helps clients undertake AWS providers to ship enterprise outcomes. He designs AI/ML and knowledge analytics options that overcome advanced technical challenges and drive strategic targets. Yunfei has a PhD in Digital and Electrical Engineering. Exterior of labor, Yunfei enjoys studying and music.
Yunfei Bai is a Principal Options Architect at AWS. With a background in AI/ML, knowledge science, and analytics, Yunfei helps clients undertake AWS providers to ship enterprise outcomes. He designs AI/ML and knowledge analytics options that overcome advanced technical challenges and drive strategic targets. Yunfei has a PhD in Digital and Electrical Engineering. Exterior of labor, Yunfei enjoys studying and music.
 Shayan Ray is an Utilized Scientist at Amazon Internet Companies. His space of analysis is all issues pure language (like NLP, NLU, and NLG). His work has been centered on conversational AI, task-oriented dialogue methods, and LLM-based brokers. His analysis publications are on pure language processing, personalization, and reinforcement studying.
Shayan Ray is an Utilized Scientist at Amazon Internet Companies. His space of analysis is all issues pure language (like NLP, NLU, and NLG). His work has been centered on conversational AI, task-oriented dialogue methods, and LLM-based brokers. His analysis publications are on pure language processing, personalization, and reinforcement studying.
 Jose Cassio dos Santos Junior is a Senior Information Scientist member of the MLU crew. He’s liable for Curriculum Growth for Superior Modules. As a earlier Senior Information Scientist on the AWS LATAM Skilled Companies Information Science crew, he has over 20 years of expertise working as a software program engineer and greater than 10 years of educating expertise at faculties and as an teacher for Linux certification preparation and Microsoft Innovation Middle bootcamps. As a enterprise course of administration professional, he participated in BPO tasks for greater than 7 years. He holds a Grasp’s diploma in Laptop Engineering, a Bachelor’s diploma in Physics, and a Bachelor’s diploma in Enterprise Administration, specialised in IT Quantitative Strategies.
Jose Cassio dos Santos Junior is a Senior Information Scientist member of the MLU crew. He’s liable for Curriculum Growth for Superior Modules. As a earlier Senior Information Scientist on the AWS LATAM Skilled Companies Information Science crew, he has over 20 years of expertise working as a software program engineer and greater than 10 years of educating expertise at faculties and as an teacher for Linux certification preparation and Microsoft Innovation Middle bootcamps. As a enterprise course of administration professional, he participated in BPO tasks for greater than 7 years. He holds a Grasp’s diploma in Laptop Engineering, a Bachelor’s diploma in Physics, and a Bachelor’s diploma in Enterprise Administration, specialised in IT Quantitative Strategies.



{kind=link}