Generative AI has emerged as a transformative power, fascinating industries with its potential to create, innovate, and clear up advanced issues. Nevertheless, the journey from a proof of idea to a production-ready software comes with challenges and alternatives. Transferring from proof of idea to manufacturing is about creating scalable, dependable, and impactful options that may drive enterprise worth and consumer satisfaction.
Some of the promising developments on this area is the rise of Retrieval Augmented Technology (RAG) functions. RAG is the method of optimizing the output of a basis mannequin (FM), so it references a information base exterior of its coaching knowledge sources earlier than producing a response.
The next diagram illustrates a pattern structure.

On this put up, we discover the motion of RAG functions from their proof of idea or minimal viable product (MVP) part to full-fledged manufacturing programs. When transitioning a RAG software from a proof of idea to a production-ready system, optimization turns into essential to ensure the answer is dependable, cost-effective, and high-performing. Let’s discover these optimization methods in higher depth, setting the stage for future discussions on internet hosting, scaling, safety, and observability concerns.
Optimization methods
The diagram under illustrates the tradeoffs to contemplate for a production-ready RAG software.

The success of a production-ready RAG system is measured by its high quality, price, and latency. Machine studying (ML) engineers should make trade-offs and prioritize crucial components for his or her particular use case and enterprise necessities. For instance, take into account the use case of producing customized advertising content material for a luxurious vogue model. The model is perhaps keen to soak up the upper prices of utilizing a extra highly effective and costly FMs to realize the highest-quality classifications, as a result of misclassifications may result in buyer dissatisfaction and injury the model’s popularity. Think about one other use case of producing customized product descriptions for an ecommerce web site. The retailer is perhaps keen to just accept barely longer latency to scale back infrastructure and operational prices, so long as the generated descriptions stay fairly correct and compelling. The optimum stability of high quality, price, and latency can fluctuate considerably throughout completely different functions and industries.
Let’s look into sensible pointers on how one can improve the general high quality of your RAG workflow, together with the standard of the retriever and high quality of the outcome generator utilizing Amazon Bedrock Information Bases and different options of Amazon Bedrock. Amazon Bedrock Information Bases supplies a totally managed functionality that helps you implement your complete RAG workflow from ingestion to retrieval and immediate augmentation with out having to construct customized integrations to knowledge sources and handle knowledge flows.
Analysis framework
An efficient analysis framework is essential for assessing and optimizing RAG programs as they transfer from proof of idea to manufacturing. These frameworks sometimes embody general metrics for a holistic evaluation of your complete RAG pipeline, in addition to particular diagnostic metrics for each the retrieval and technology elements. This permits for focused enhancements in every part of the system. By implementing a sturdy analysis framework, builders can repeatedly monitor, diagnose, and improve their RAG programs, reaching optimum efficiency throughout high quality, price, and latency dimensions as the appliance scales to manufacturing ranges. Amazon Bedrock Evaluations may help you consider your retrieval or end-to-end RAG workflow in Amazon Bedrock Information Bases. Within the following sections, we focus on these particular metrics in several phases of the RAG workflow in additional element.
Retriever high quality
For higher retrieval efficiency, the way in which the information is saved within the vector retailer has a huge impact. For instance, your enter doc would possibly embody tables throughout the PDF. In such instances, utilizing an FM to parse the information will present higher outcomes. You need to use superior parsing choices supported by Amazon Bedrock Information Bases for parsing non-textual info from paperwork utilizing FMs. Many organizations retailer their knowledge in structured codecs inside knowledge warehouses and knowledge lakes. Amazon Bedrock Information Bases gives a function that permits you to join your RAG workflow to structured knowledge shops. This absolutely managed out-of-the-box RAG answer may help you natively question structured knowledge from the place it resides.
One other necessary consideration is the way in which your supply doc is cut up up into chunks. In case your doc would profit from inherent relationships inside your doc, it is perhaps sensible to make use of hierarchical chunking, which permits for extra granular and environment friendly retrieval. Some paperwork profit from semantic chunking by preserving the contextual relationship within the chunks, serving to ensure that the associated info stays collectively in logical chunks. It’s also possible to use your individual customized chunking technique to your RAG software’s distinctive necessities.
RAG functions course of consumer queries by looking out throughout a big set of paperwork. Nevertheless, in lots of conditions, you would possibly must retrieve paperwork with particular attributes or content material. You need to use metadata filtering to slender down search outcomes by specifying inclusion and exclusion standards. Amazon Bedrock Information Bases now additionally helps auto generated question filters, which prolong the prevailing functionality of handbook metadata filtering by permitting you to slender down search outcomes with out the necessity to manually assemble advanced filter expressions. This improves retrieval accuracy by ensuring the paperwork are related to the question.
Generator high quality
Writing an efficient question is simply as necessary as some other consideration for technology accuracy. You may add a immediate offering directions to the FM to offer an acceptable reply to the consumer. For instance, a authorized tech firm would wish to present directions to limit the solutions to be primarily based on the enter paperwork and never primarily based on basic info identified to the FM. Question decomposition by splitting the enter question into a number of queries can be useful in retrieval accuracy. On this course of, the subqueries with much less semantic complexity would possibly discover extra focused chunks. These chunks can then be pooled and ranked collectively earlier than passing them to the FM to generate a response.
Reranking, as a post-retrieval step, can considerably enhance response high quality. This system makes use of LLMs to investigate the semantic relevance between the question and retrieved paperwork, reordering them primarily based on their pertinence. By incorporating reranking, you ensure that solely essentially the most contextually related info is used for technology, resulting in extra correct and coherent responses.
Adjusting inference parameters, corresponding to temperature and top-k/p sampling, may help in additional refining the output.
You need to use Amazon Bedrock Information Bases to configure and customise queries and response technology. It’s also possible to enhance the relevance of your question responses with a reranker mannequin in Amazon Bedrock.
General high quality
The important thing metrics for retriever high quality are context precision, context recall, and context relevance. Context precision measures how properly the system ranks related items of knowledge from the given context. It considers the query, floor reality, and context. Context recall supplies the proportion of floor reality claims or key info coated by the retrieved context. Context relevance measures whether or not the retrieved passages or chunks are related for answering the given question, excluding extraneous particulars. Collectively, these three metrics supply perception into how successfully the retriever is ready to floor essentially the most related and targeted supply materials to assist a high-quality response.
Generator high quality will be assessed by way of a number of key metrics. Context utilization examines how successfully the generator makes use of related info from the offered supply materials. Noise sensitivity gauges the generator’s propensity to incorporate inaccurate particulars from the retrieved content material. Hallucination measures the extent to which the generator produces incorrect claims not current within the supply knowledge. Self-knowledge displays the proportion of correct statements generated that may’t be discovered within the retrieved chunks. Lastly, faithfulness evaluates how intently the generator’s output aligns with the data contained within the supply materials.
For measuring the general technology high quality, the important thing metrics embody measuring the precision, recall, and reply similarity. Precision suggests the proportion of the right claims in mannequin’s response, whereas recall suggests the proportion of the bottom reality claims coated by the mannequin’s response. Reply similarity compares the that means and content material of a generated reply with a reference or floor reality reply. It evaluates how intently the generated reply matches the supposed that means of the bottom reality reply.
Establishing a suggestions loop with an analysis framework in opposition to these high quality metrics permits for steady enchancment, the place the system can be taught from consumer interactions and refine its efficiency over time. By optimizing these high quality metrics, the RAG system will be designed to ship dependable, cost-effective, and high-performing outcomes for customers.
For an illustration on how you should utilize a RAG analysis framework in Amazon Bedrock to compute RAG high quality metrics, confer with New RAG analysis and LLM-as-a-judge capabilities in Amazon Bedrock.
Accountable AI
Implementing accountable AI practices is essential for sustaining moral and secure deployment of RAG programs. This contains utilizing guardrails to filter dangerous content material, deny sure matters, masks delicate info, and floor responses in verified sources to scale back hallucinations.
You need to use Amazon Bedrock Guardrails for implementing accountable AI insurance policies. Together with defending in opposition to toxicity and dangerous content material, it may also be used for Automated Reasoning checks, which helps you shield in opposition to hallucinations.
Price and latency
Price considers the compute sources and infrastructure required to run the system, and latency evaluates the response occasions skilled by end-users. To optimize price and latency, implement caching methods to scale back the necessity for costly mannequin inferences. Environment friendly question batching can even enhance general throughput and cut back useful resource utilization. Steadiness efficiency and useful resource utilization to search out the perfect configuration that meets your software’s necessities.
Use instruments like Amazon Bedrock Information Bases so you may benefit from absolutely managed assist for the end-to-end RAG workflow. It helps lots of the superior RAG capabilities we mentioned earlier. By addressing these optimization methods, you may transition your RAG-powered proof of idea to a sturdy, production-ready system that delivers high-quality, cost-effective, and low-latency responses to your customers.
For extra info on constructing RAG functions utilizing Amazon Bedrock Information Bases, confer with Constructing scalable, safe, and dependable RAG functions utilizing Amazon Bedrock Information Bases.
Internet hosting and scaling
In terms of internet hosting your net software or service, there are a number of approaches to contemplate. The hot button is to decide on an answer that may successfully host your database and compute infrastructure. This might embody server-based choices like Amazon Elastic Compute Cloud (Amazon EC2), managed providers like Amazon Relational Database Service (Amazon RDS) and Amazon DynamoDB, or serverless approaches corresponding to AWS Amplify and Amazon Elastic Container Service (Amazon ECS). For a sensible method to constructing an automatic AI assistant utilizing Amazon ECS, see Develop a totally automated chat-based assistant through the use of Amazon Bedrock brokers and information bases.
Along with the server or compute layer, additionally, you will want to contemplate an orchestration instrument, testing environments, and a steady integration and supply (CI/CD) pipeline to streamline your software deployment. Having a suggestions loop established primarily based on the standard metrics together with a CI/CD pipeline is a crucial first step to creating self-healing architectures.
As your software grows, you have to to ensure your infrastructure can scale to satisfy the rising demand. This may contain containerization with Docker or selecting serverless choices, implementing load balancing, organising auto scaling, and selecting between on-premises, cloud, or hybrid options. It additionally contains distinctive scaling necessities of your frontend software and backend generative AI workflow, in addition to using content material supply networks (CDNs) and catastrophe restoration and backup methods.
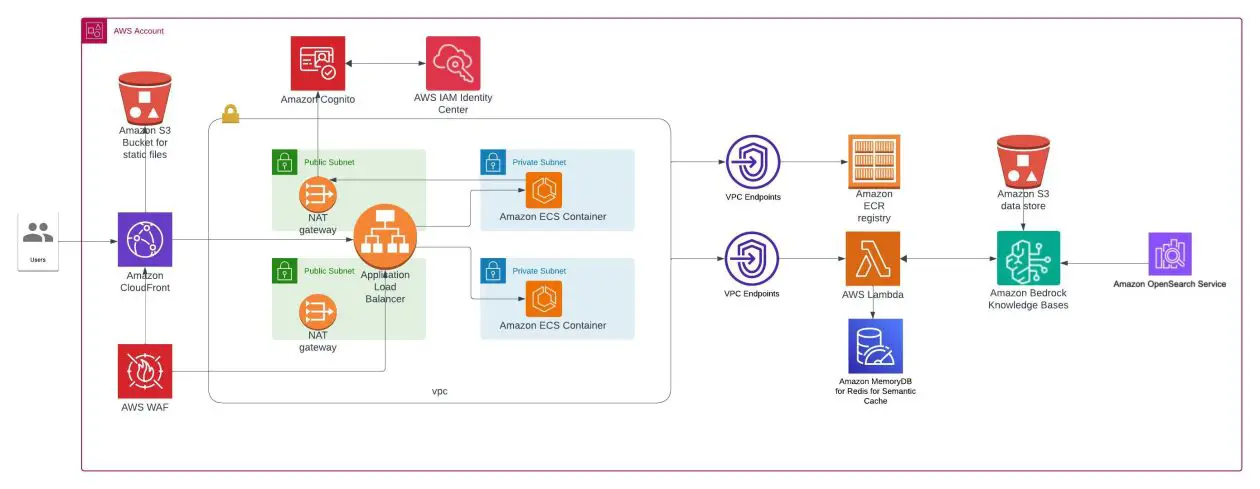
The next is a pattern structure for a safe and scalable RAG-based net software. This structure makes use of Amazon ECS for internet hosting the service, Amazon CloudFront as a CDN, AWS WAF as a firewall, and Amazon MemoryDB for offering a semantic cache.

By fastidiously contemplating these features of internet hosting and scaling your infrastructure, you may construct a resilient and adaptable system to assist your rising net software or service. Keep tuned for extra detailed info on these matters in upcoming weblog posts.
Information privateness, safety, and observability
Sustaining knowledge privateness and safety is of utmost significance. This contains implementing safety measures at every layer of your software, from encrypting knowledge in transit to organising sturdy authentication and authorization controls. It additionally entails specializing in compute and storage safety, in addition to community safety. Compliance with related rules and common safety audits are important. Securing your generative AI system is one other essential side. By default, Amazon Bedrock Information Bases encrypts the site visitors utilizing AWS managed AWS Key Administration Service (AWS KMS) keys. It’s also possible to select buyer managed KMS keys for extra management over encryption keys. For extra info on software safety, confer with Safeguard a generative AI journey agent with immediate engineering and Amazon Bedrock Guardrails.
Complete logging, monitoring, and upkeep are essential to sustaining a wholesome infrastructure. This contains organising structured logging, centralized log administration, real-time monitoring, and methods for system updates and migrations.
By addressing these vital areas, you may construct a safe and resilient infrastructure to assist your rising net software or service. Keep tuned for extra in-depth protection of those matters in upcoming weblog posts.
Conclusion
To efficiently transition a RAG software from a proof of idea to a production-ready system, you must deal with optimizing the answer for reliability, cost-effectiveness, and excessive efficiency. Key areas to handle embody enhancing retriever and generator high quality, balancing price and latency, and establishing a sturdy and safe infrastructure.
By utilizing purpose-built instruments like Amazon Bedrock Information Bases to streamline the end-to-end RAG workflow, organizations can efficiently transition their RAG-powered proofs of idea into high-performing, cost-effective, safe production-ready options that ship enterprise worth.
References
In regards to the Writer
 Vivek Mittal is a Resolution Architect at Amazon Internet Providers, the place he helps organizations architect and implement cutting-edge cloud options. With a deep ardour for Generative AI, Machine Studying, and Serverless applied sciences, he focuses on serving to prospects harness these improvements to drive enterprise transformation. He finds explicit satisfaction in collaborating with prospects to show their formidable technological visions into actuality.
Vivek Mittal is a Resolution Architect at Amazon Internet Providers, the place he helps organizations architect and implement cutting-edge cloud options. With a deep ardour for Generative AI, Machine Studying, and Serverless applied sciences, he focuses on serving to prospects harness these improvements to drive enterprise transformation. He finds explicit satisfaction in collaborating with prospects to show their formidable technological visions into actuality.
 Nitin Eusebius is a Sr. Enterprise Options Architect at AWS, skilled in Software program Engineering, Enterprise Structure, and AI/ML. He’s deeply keen about exploring the probabilities of generative AI. He collaborates with prospects to assist them construct well-architected functions on the AWS platform, and is devoted to fixing expertise challenges and aiding with their cloud journey.
Nitin Eusebius is a Sr. Enterprise Options Architect at AWS, skilled in Software program Engineering, Enterprise Structure, and AI/ML. He’s deeply keen about exploring the probabilities of generative AI. He collaborates with prospects to assist them construct well-architected functions on the AWS platform, and is devoted to fixing expertise challenges and aiding with their cloud journey.
 Mani Khanuja is a Tech Lead – Generative AI Specialists, writer of the guide Utilized Machine Studying and Excessive-Efficiency Computing on AWS, and a member of the Board of Administrators for Girls in Manufacturing Schooling Basis Board. She leads machine studying initiatives in varied domains corresponding to pc imaginative and prescient, pure language processing, and generative AI. She speaks at inner and exterior conferences such AWS re:Invent, Girls in Manufacturing West, YouTube webinars, and GHC 23. In her free time, she likes to go for lengthy runs alongside the seaside.
Mani Khanuja is a Tech Lead – Generative AI Specialists, writer of the guide Utilized Machine Studying and Excessive-Efficiency Computing on AWS, and a member of the Board of Administrators for Girls in Manufacturing Schooling Basis Board. She leads machine studying initiatives in varied domains corresponding to pc imaginative and prescient, pure language processing, and generative AI. She speaks at inner and exterior conferences such AWS re:Invent, Girls in Manufacturing West, YouTube webinars, and GHC 23. In her free time, she likes to go for lengthy runs alongside the seaside.



{kind=link}