The analysis of enormous language mannequin (LLM) efficiency, notably in response to quite a lot of prompts, is essential for organizations aiming to harness the total potential of this quickly evolving know-how. The introduction of an LLM-as-a-judge framework represents a major step ahead in simplifying and streamlining the mannequin analysis course of. This strategy permits organizations to evaluate their AI fashions’ effectiveness utilizing pre-defined metrics, ensuring that the know-how aligns with their particular wants and aims. By adopting this methodology, firms can extra precisely gauge the efficiency of their AI programs, making knowledgeable selections about mannequin choice, optimization, and deployment. This not solely enhances the reliability and effectivity of AI functions, but in addition contributes to a extra strategic and knowledgeable strategy to know-how adoption throughout the group.
Amazon Bedrock, a completely managed service providing high-performing basis fashions from main AI firms by means of a single API, has not too long ago launched two important analysis capabilities: LLM-as-a-judge underneath Amazon Bedrock Mannequin Analysis and RAG analysis for Amazon Bedrock Information Bases. Each options use the LLM-as-a-judge method behind the scenes however consider various things. This weblog publish explores LLM-as-a-judge on Amazon Bedrock Mannequin Analysis, offering complete steerage on function setup, evaluating job initiation by means of each the console and Python SDK and APIs, and demonstrating how this revolutionary analysis function can improve generative AI functions throughout a number of metric classes together with high quality, person expertise, instruction following, and security.
Earlier than we discover the technical elements and implementation particulars, let’s look at the important thing options that make LLM-as-a-judge on Amazon Bedrock Mannequin Analysis notably highly effective and distinguish it from conventional analysis strategies. Understanding these core capabilities will assist illuminate why this function represents a major development in AI mannequin analysis.
Key options of LLM-as-a-judge
- Automated clever analysis: LLM-as-a-judge makes use of pre-trained fashions to judge responses robotically, offering human-like analysis high quality with as much as 98% price financial savings. The system dramatically reduces analysis time from weeks to hours whereas sustaining constant analysis requirements throughout massive datasets.
- Complete metric classes: The analysis system covers 4 key metric areas: high quality evaluation (correctness, completeness, faithfulness), person expertise (helpfulness, coherence, relevance), instruction compliance (following directions, skilled model), and security monitoring (harmfulness, stereotyping, refusal dealing with).
- Seamless integration: The function integrates instantly with Amazon Bedrock and stays suitable with present Amazon Bedrock Mannequin Analysis options. Customers can entry the performance by means of the AWS Administration Console for Amazon Bedrock and rapidly combine their customized datasets for analysis functions.
- Versatile implementation: The system helps the analysis of fashions hosted on Amazon Bedrock, customized fine-tuned fashions, and imported fashions. Customers can seamlessly join their analysis datasets by means of Amazon Easy Storage Service (Amazon S3) buckets, making the analysis course of streamlined and environment friendly.
- Curated choose fashions: Amazon Bedrock gives pre-selected, high-quality analysis fashions with optimized immediate engineering for correct assessments. Customers don’t have to convey exterior choose fashions, as a result of the Amazon Bedrock staff maintains and updates a choice of choose fashions and related analysis choose prompts.
- Price-effective scaling: The function permits organizations to carry out complete mannequin evaluations at scale with out the normal prices and time investments related to human analysis. The automated course of maintains high-quality assessments whereas considerably decreasing operational overhead.
These options create a robust analysis framework that helps organizations optimize their AI mannequin efficiency whereas sustaining excessive requirements of high quality and security, all inside their safe AWS surroundings.
Product overview
Now that you just perceive the important thing options of LLM-as-a-judge, let’s look at how you can implement and use this functionality inside Amazon Bedrock Mannequin Analysis. This part gives a complete overview of the structure and walks by means of every element, demonstrating how they work collectively to ship correct and environment friendly mannequin evaluations.
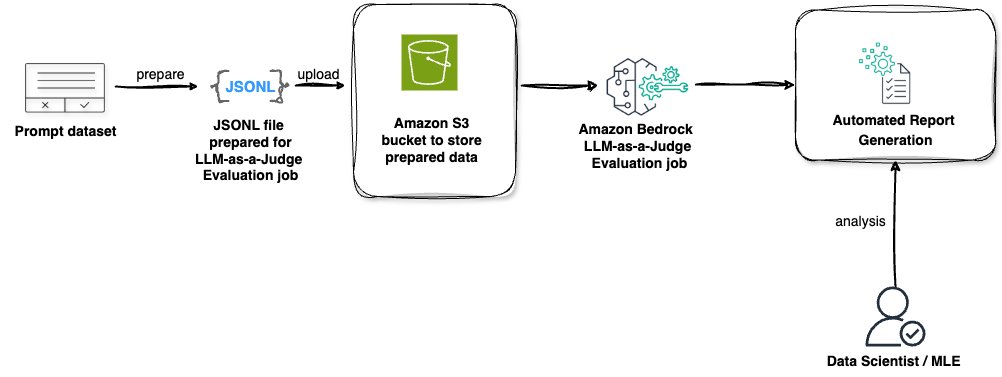
LLM-as-a-judge on Amazon Bedrock Mannequin Analysis gives a complete, end-to-end answer for assessing and optimizing AI mannequin efficiency. This automated course of makes use of the ability of LLMs to judge responses throughout a number of metric classes, providing insights that may considerably enhance your AI functions. Let’s stroll by means of the important thing parts of this answer as proven within the following diagram:

LLM-as-a-judge on Amazon Bedrock Mannequin Analysis follows a streamlined workflow that allows systematic mannequin analysis. Right here’s how every element works collectively within the analysis course of:
- Immediate dataset: The method begins with a ready dataset containing prompts that shall be used to check the mannequin’s efficiency. The analysis could be performed with or with out floor fact responses—whereas together with floor fact gives extra comparability factors, it’s solely optionally available and never required for profitable analysis.
- JSONL file preparation: The immediate dataset is transformed into JSONL format, which is particularly structured for LLM-as-a-judge analysis jobs. This format promotes correct processing of analysis information.
- Amazon S3 storage: The ready JSONL file is uploaded to an S3 bucket, serving because the safe storage location for the analysis information.
- Analysis processing: The Amazon Bedrock LLM-as-a-judge mannequin analysis job processes the saved information, working complete assessments throughout the chosen metric classes (together with high quality, person expertise, instruction following, and security).
- Automated report era: Upon completion, the system generates detailed analysis experiences containing metrics, scores, and insights at each mixture and particular person response ranges.
- Skilled evaluation: Information scientists or machine studying engineers analyze the generated experiences to derive actionable insights and make knowledgeable selections.
With this answer structure in thoughts, let’s discover how you can implement LLM-as-a-judge mannequin evaluations successfully, ensuring that you just get probably the most precious insights out of your evaluation course of.
Stipulations
To make use of the LLM-as-a-judge mannequin analysis, just be sure you have glad the next necessities:
- An energetic AWS account.
- Chosen evaluator and generator fashions enabled in Amazon Bedrock. You possibly can affirm that the fashions are enabled to your account on the Mannequin entry web page of the Amazon Bedrock console.
- Affirm the AWS Areas the place the mannequin is accessible and quotas.
- Full mannequin analysis stipulationsassociated to AWS Identification and Entry Administration (IAM) creation, and add permissions for an S3 bucket to entry and write output information.
- Should you’re utilizing a customized mannequin as a substitute of an on-demand mannequin to your generator mannequin, just be sure you have adequate quota for working a Provisioned Throughput throughout inference.
- Full the stipulations for importing a customized mannequin.
- Go to the AWS Service Quotas console, and examine the next quotas:
- Mannequin items no-commitment Provisioned Throughputs throughout customized fashions.
- Mannequin items per provisioned mannequin for [your custom model name].
- Each of those fields have to have sufficient quota to assist your Provisioned Throughput mannequin unit. Request a quota enhance if essential to accommodate your anticipated inference workload.
Put together enter dataset
When making ready your dataset for LLM-as-a-judge mannequin analysis jobs, every immediate should embody particular key-value pairs. Listed here are the required and optionally available fields:
- immediate (required): This key signifies the enter for numerous duties. It may be used for basic textual content era the place the mannequin wants to supply a response, question-answering duties the place the mannequin should reply a particular query, textual content summarization duties the place the mannequin must summarize a given textual content, or classification duties the place the mannequin should categorize the supplied textual content.
- referenceResponse (used for particular metrics with floor fact): This key accommodates the bottom fact or appropriate response. It serves because the reference level in opposition to which the mannequin’s responses shall be evaluated whether it is supplied.
- class (optionally available): This secret’s used to generate analysis scores reported by class, serving to arrange and phase analysis outcomes for higher evaluation.
Dataset necessities:
- Every line have to be a sound JSON object
- The file should use JSONL format
- The dataset ought to be saved in an Amazon S3 bucket
Instance JSONL format with out floor fact (class is optionally available):
Instance JSONL format with floor fact (class is optionally available):
Begin an LLM-as-a-judge mannequin analysis job utilizing the console
You should use LLM-as-a-judge on Amazon Bedrock Mannequin Analysis to evaluate mannequin efficiency by means of a user-friendly console interface. Observe these steps to begin an analysis job:
- Within the Amazon Bedrock console, select Inference and Evaluation after which choose Evalutaions. On the Evaluations web page, select the Fashions

- Select Create and choose Automated: LLM-as-a-judge.
- Enter a reputation and outline and choose an Evaluator mannequin. This mannequin shall be used as a choose to judge the response of a immediate or mannequin out of your generative AI software.

- Select Tags and choose the mannequin for use for producing responses on this analysis job.

- Choose the metrics you wish to use to judge the mannequin response (reminiscent of helpfulness, correctness, faithfulness, relevance, and harmfulness).

- Choose the S3 URI for Select a immediate dataset and for Analysis outcomes. You should use the Browse S3 possibility.

- Choose or create an IAM service function with the correct permissions. This consists of service entry to Amazon Bedrock, the S3 buckets within the analysis job, and the fashions getting used within the job. Should you create a brand new IAM function within the analysis setup, the service will robotically give the function the correct permissions for the job. Specify the output S3 bucket and select Create.

- It is possible for you to to see the analysis job is In Progress. Look ahead to the job standing to vary to Full.

- When full, choose the job to see its particulars. The next is the metrics abstract (reminiscent of 0.83 for helpfulness, 1.00 for correctness, 1.00 for faithfulness, 1.00 for relevance, and 0.00 for harmfulness).

- To view era metrics particulars, scroll down within the mannequin analysis report and select any particular person metric (like helpfulness or correctness) to see its detailed breakdown.

- To see every document’s immediate enter, era output, floor fact, and particular person scores, select a metric and choose “Immediate particulars”. Hover over any particular person rating to view its detailed clarification.

Begin an LLM-as-a-judge analysis job utilizing Python SDK and APIs
To make use of the Python SDK for creating an LLM-as-a-judge mannequin analysis job, use the next steps. First, arrange the required configurations:
To create an LLM-as-a-judge mannequin analysis job:
To observe the progress of your analysis job:
It’s also possible to evaluate a number of basis fashions to find out which one works greatest to your wants. By utilizing the identical evaluator mannequin throughout all comparisons, you’ll get constant benchmarking outcomes to assist determine the optimum mannequin to your use case.
Correlation evaluation for LLM-as-a-judge evaluations
You should use the Spearman’s rank correlation coefficient to match analysis outcomes between completely different generator fashions utilizing LLM-as-a-judge in Amazon Bedrock. After retrieving the analysis outcomes out of your S3 bucket, containing analysis scores throughout numerous metrics, you possibly can start the correlation evaluation.
Utilizing scipy.stats, compute the correlation coefficient between pairs of generator fashions, filtering out fixed values or error messages to have a sound statistical comparability. The ensuing correlation coefficients assist determine how equally completely different fashions reply to the identical prompts. A coefficient nearer to 1.0 signifies stronger settlement between the fashions’ responses, whereas values nearer to 0 recommend extra divergent habits. This evaluation gives precious insights into mannequin consistency and helps determine instances the place completely different fashions would possibly produce considerably completely different outputs for a similar enter.
Greatest practices for LLM-as-a-judge implementation
It’s also possible to evaluate a number of basis fashions to find out which one works greatest to your wants. By utilizing the identical evaluator mannequin throughout all comparisons, you’ll get constant, scalable outcomes. The next greatest practices will make it easier to set up standardized benchmarking when evaluating completely different basis fashions.
- Create numerous check datasets that signify real-world use instances and edge instances. For big workloads (greater than 1,000 prompts), use stratified sampling to take care of complete protection whereas managing prices and completion time. Embrace each easy and sophisticated prompts to check mannequin capabilities throughout completely different issue ranges.
- Select analysis metrics that align together with your particular enterprise aims and software necessities. Steadiness high quality metrics (correctness, completeness) with person expertise metrics (helpfulness, coherence). Embrace security metrics when deploying customer-facing functions.
- Preserve constant analysis situations when evaluating completely different fashions. Use the identical evaluator mannequin throughout comparisons for standardized benchmarking. Doc your analysis configuration and parameters for reproducibility.
- Schedule common analysis jobs to trace mannequin efficiency over time. Monitor tendencies throughout completely different metric classes to determine areas for enchancment. Arrange efficiency baselines and thresholds for every metric.
- Optimize batch sizes based mostly in your analysis wants and value constraints. Think about using smaller check units for fast iteration and bigger units for complete analysis. Steadiness analysis frequency with useful resource utilization.
- Preserve detailed information of analysis jobs, together with configurations and outcomes. Monitor enhancements and adjustments in mannequin efficiency over time. Doc any modifications made based mostly on analysis insights. The optionally available job description area may help you right here.
- Use analysis outcomes to information mannequin choice and optimization. Implement suggestions loops to constantly enhance immediate engineering. Commonly replace analysis standards based mostly on rising necessities and person suggestions.
- Design your analysis framework to accommodate rising workloads. Plan for elevated complexity as you add extra fashions or use instances. Contemplate automated workflows for normal analysis duties.
These greatest practices assist set up a sturdy analysis framework utilizing LLM-as-a-judge on Amazon Bedrock. For deeper insights into the scientific validation of those practices, together with case research and correlation with human judgments, keep tuned for our upcoming technical deep-dive weblog publish.
Conclusion
LLM-as-a-judge on Amazon Bedrock Mannequin Analysis represents a major development in automated mannequin evaluation, providing organizations a robust device to judge and optimize their AI functions systematically. This function combines the effectivity of automated analysis with the nuanced understanding usually related to human evaluation, enabling organizations to scale their high quality assurance processes whereas sustaining excessive requirements of efficiency and security.
The great metric classes, versatile implementation choices, and seamless integration with present AWS companies make it potential for organizations to determine strong analysis frameworks that develop with their wants. Whether or not you’re growing conversational AI functions, content material era programs, or specialised enterprise options, LLM-as-a-judge gives the required instruments to ensure that your fashions align with each technical necessities and enterprise aims.
We’ve supplied detailed implementation steerage, from preliminary setup to greatest practices, that will help you use this function successfully. The accompanying code samples and configuration examples on this publish display how you can implement these evaluations in follow. Via systematic analysis and steady enchancment, organizations can construct extra dependable, correct, and reliable AI functions.
We encourage you to discover LLM-as-a-judge capabilities within the Amazon Bedrock console and uncover how automated analysis can improve your AI functions. That can assist you get began, we’ve ready a Jupyter pocket book with sensible examples and code snippets that you could find on our GitHub repository.
Concerning the Authors
 Adewale Akinfaderin is a Sr. Information Scientist–Generative AI, Amazon Bedrock, the place he contributes to leading edge improvements in foundational fashions and generative AI functions at AWS. His experience is in reproducible and end-to-end AI/ML strategies, sensible implementations, and serving to world prospects formulate and develop scalable options to interdisciplinary issues. He has two graduate levels in physics and a doctorate in engineering.
Adewale Akinfaderin is a Sr. Information Scientist–Generative AI, Amazon Bedrock, the place he contributes to leading edge improvements in foundational fashions and generative AI functions at AWS. His experience is in reproducible and end-to-end AI/ML strategies, sensible implementations, and serving to world prospects formulate and develop scalable options to interdisciplinary issues. He has two graduate levels in physics and a doctorate in engineering.
 Ishan Singh is a Generative AI Information Scientist at Amazon Net Companies, the place he helps prospects construct revolutionary and accountable generative AI options and merchandise. With a powerful background in AI/ML, Ishan focuses on constructing Generative AI options that drive enterprise worth. Outdoors of labor, he enjoys taking part in volleyball, exploring native bike trails, and spending time together with his spouse and canine, Beau.
Ishan Singh is a Generative AI Information Scientist at Amazon Net Companies, the place he helps prospects construct revolutionary and accountable generative AI options and merchandise. With a powerful background in AI/ML, Ishan focuses on constructing Generative AI options that drive enterprise worth. Outdoors of labor, he enjoys taking part in volleyball, exploring native bike trails, and spending time together with his spouse and canine, Beau.
 Jesse Manders is a Senior Product Supervisor on Amazon Bedrock, the AWS Generative AI developer service. He works on the intersection of AI and human interplay with the objective of making and enhancing generative AI services and products to satisfy our wants. Beforehand, Jesse held engineering staff management roles at Apple and Lumileds, and was a senior scientist in a Silicon Valley startup. He has an M.S. and Ph.D. from the College of Florida, and an MBA from the College of California, Berkeley, Haas College of Enterprise.
Jesse Manders is a Senior Product Supervisor on Amazon Bedrock, the AWS Generative AI developer service. He works on the intersection of AI and human interplay with the objective of making and enhancing generative AI services and products to satisfy our wants. Beforehand, Jesse held engineering staff management roles at Apple and Lumileds, and was a senior scientist in a Silicon Valley startup. He has an M.S. and Ph.D. from the College of Florida, and an MBA from the College of California, Berkeley, Haas College of Enterprise.



{kind=link}