Giant language fashions (LLMs) have demonstrated promising capabilities in machine translation (MT) duties. Relying on the use case, they can compete with neural translation fashions corresponding to Amazon Translate. LLMs notably stand out for his or her pure potential to study from the context of the enter textual content, which permits them to choose up on cultural cues and produce extra pure sounding translations. As an example, the sentence “Did you carry out effectively?” translated in French is likely to be translated into “Avez-vous bien performé?” The goal translation can fluctuate extensively relying on the context. If the query is requested within the context of sport, corresponding to “Did you carry out effectively on the soccer event?”, the pure French translation could be very completely different. It’s important for AI fashions to seize not solely the context, but additionally the cultural specificities to provide a extra pure sounding translation. Considered one of LLMs’ most fascinating strengths is their inherent potential to know context.
Numerous our world clients wish to reap the benefits of this functionality to enhance the standard of their translated content material. Localization depends on each automation and humans-in-the-loop in a course of known as Machine Translation Publish Enhancing (MTPE). Constructing options that assist improve translated content material high quality current a number of advantages:
- Potential price financial savings on MTPE actions
- Quicker turnaround for localization tasks
- Higher expertise for content material customers and readers total with enhanced high quality
LLMs have additionally proven gaps as regards to MT duties, corresponding to:
- Inconsistent high quality over sure language pairs
- No commonplace sample to combine previous translations data, also called translation reminiscence (TM)
- Inherent danger of hallucination
Switching MT workloads from to LLM-driven translation must be thought-about on a case-by-case foundation. Nevertheless, the {industry} is seeing sufficient potential to think about LLMs as a invaluable possibility.
This weblog put up with accompanying code presents an answer to experiment with real-time machine translation utilizing basis fashions (FMs) accessible in Amazon Bedrock. It could possibly assist accumulate extra knowledge on the worth of LLMs to your content material translation use instances.
Steering the LLMs’ output
Translation reminiscence and TMX information are vital ideas and file codecs used within the discipline of computer-assisted translation (CAT) instruments and translation administration programs (TMSs).
Translation reminiscence
A translation reminiscence is a database that shops beforehand translated textual content segments (usually sentences or phrases) together with their corresponding translations. The principle objective of a TM is to help human or machine translators by offering them with strategies for segments which have already been translated earlier than. This will considerably enhance translation effectivity and consistency, particularly for tasks involving repetitive content material or comparable subject material.
Translation Reminiscence eXchange (TMX) is a extensively used open commonplace for representing and exchanging TM knowledge. It’s an XML-based file format that permits for the alternate of TMs between completely different CAT instruments and TMSs. A typical TMX file comprises a structured illustration of translation models, that are groupings of a similar textual content translated into a number of languages.
Integrating TM with LLMs
The usage of TMs together with LLMs could be a highly effective method for bettering the standard and effectivity of machine translation. The next are a couple of potential advantages:
- Improved accuracy and consistency – LLMs can profit from the high-quality translations saved in TMs, which may help enhance the general accuracy and consistency of the translations produced by the LLM. The TM can present the LLM with dependable reference translations for particular segments, decreasing the probabilities of errors or inconsistencies.
- Area adaptation – TMs typically include translations particular to a specific area or subject material. By utilizing a domain-specific TM, the LLM can higher adapt to the terminology, model, and context of that area, resulting in extra correct and pure translations.
- Environment friendly reuse of human translations – TMs retailer human-translated segments, that are usually of upper high quality than machine-translated segments. By incorporating these human translations into the LLM’s coaching or inference course of, the LLM can study from and reuse these high-quality translations, probably bettering its total efficiency.
- Lowered post-editing effort – When the LLM can precisely use the translations saved within the TM, the necessity for human post-editing may be lowered, resulting in elevated productiveness and price financial savings.
One other method to integrating TM knowledge with LLMs is to make use of fine-tuning in the identical means you’d fine-tune a mannequin for enterprise area content material technology, as an illustration. For purchasers working in world industries, probably translating to and from over 10 languages, this method can show to be operationally complicated and expensive. The answer proposed on this put up depends on LLMs’ context studying capabilities and immediate engineering. It lets you use an off-the-shelf mannequin as is with out involving machine studying operations (MLOps) exercise.
Resolution overview
The LLM translation playground is a pattern software offering the next capabilities:
- Experiment with LLM translation capabilities utilizing fashions accessible in Amazon Bedrock
- Create and examine numerous inference configurations
- Consider the impression of immediate engineering and Retrieval Augmented Technology (RAG) on translation with LLMs
- Configure supported language pairs
- Import, course of, and take a look at translation utilizing your present TMX file with A number of LLMS
- Customized terminology conversion
- Efficiency, high quality, and utilization metrics together with BLEU, BERT, METEOR and, CHRF
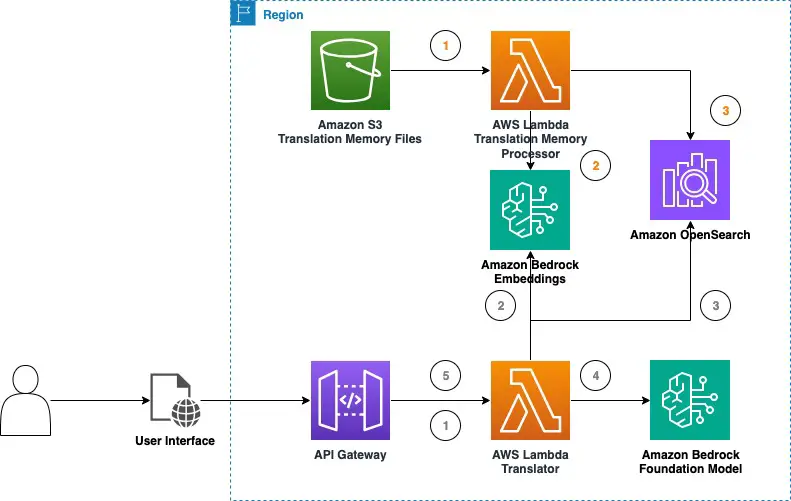
The next diagram illustrates the interpretation playground structure. The numbers are color-coded to characterize two flows: the interpretation reminiscence ingestion movement (orange) and the textual content translation movement (grey). The answer gives two TM retrieval modes for customers to select from: vector and doc search. That is lined intimately later within the put up.

The TM ingestion movement (orange) consists of the next steps:
- The person uploads a TMX file to the playground UI.
- Relying on which retrieval mode is getting used, the suitable adapter is invoked.
- When utilizing the Amazon OpenSearch Service adapter (doc search), translation unit groupings are parsed and saved into an index devoted to the uploaded file. When utilizing the FAISS adapter (vector search), translation unit groupings are parsed and became vectors utilizing the chosen embedding mannequin from Amazon Bedrock.
- When utilizing the FAISS adapter, translation models are saved into an area FAISS index together with the metadata.
The textual content translation movement (grey) consists of the next steps:
- The person enters the textual content they need to translate together with supply and goal language.
- The request is distributed to the immediate generator.
- The immediate generator invokes the suitable data base in response to the chosen mode.
- The immediate generator receives the related translation models.
- Amazon Bedrock is invoked utilizing the generated immediate as enter together with customization parameters.
The interpretation playground could possibly be tailored right into a scalable serverless answer as represented by the next diagram utilizing AWS Lambda, Amazon Easy Storage Service (Amazon S3), and Amazon API Gateway.

Technique for TM data base
The LLM translation playground gives two choices to include the interpretation reminiscence into the immediate. Every possibility is obtainable by means of its personal web page throughout the software:
- Vector retailer utilizing FAISS – On this mode, the appliance processes the .tmx file the person uploaded, indexes it, and shops it regionally right into a vector retailer (FAISS).
- Doc retailer utilizing Amazon OpenSearch Serverless – Solely commonplace doc search utilizing Amazon OpenSearch Serverless is supported. To check vector search, use the vector retailer possibility (utilizing FAISS).
In vector retailer mode, the interpretation segments are processed as follows:
- Embed the supply section.
- Extract metadata:
- Section language
- System generated
- Retailer supply section vectors together with metadata and the section itself in plain textual content as a doc
The interpretation customization part permits you to choose the embedding mannequin. You may select both Amazon Titan Embeddings Textual content V2 or Cohere Embed Multilingual v3. Amazon Titan Textual content Embeddings V2 contains multilingual assist for over 100 languages in pre-training. Cohere Embed helps 108 languages.
In doc retailer mode, the language segments usually are not embedded and are saved following a flat construction. Two metadata attributes are maintained throughout the paperwork:
- Section Language
- System generated

Immediate engineering
The applying makes use of immediate engineering methods to include a number of kinds of inputs for the inference. The next pattern XML illustrates the immediate’s template construction:
Conditions
The mission code makes use of the Python model of the AWS Cloud Improvement Equipment (AWS CDK). To run the mission code, just remember to have fulfilled the AWS CDK stipulations for Python.
The mission additionally requires that the AWS account is bootstrapped to permit the deployment of the AWS CDK stack.
Set up the UI
To deploy the answer, first set up the UI (Streamlit software):
- Clone the GitHub repository utilizing the next command:
git clone https://github.com/aws-samples/llm-translation-playground.git- Navigate to the deployment listing:
cd llm-translation-playground- Set up and activate a Python digital atmosphere:
python3 -m venv .venv
supply .venv/bin/activate- Set up Python libraries:
python -m pip set up -r necessities.txtDeploy the AWS CDK stack
Full the next steps to deploy the AWS CDK stack:
- Transfer into the deployment folder:
cd deployment/cdk- Configure the AWS CDK context parameters file
context.json. Forcollection_name, use the OpenSearch Serverless assortment title. For instance:
"collection_name": "search-subtitles"
- Deploy the AWS CDK stack:
cdk deploy- Validate profitable deployment by reviewing the
OpsServerlessSearchStackstack on the AWS CloudFormation The standing ought to learn CREATE_COMPLETE. - On the Outputs tab, make word of the
OpenSearchEndpointattribute worth.

Configure the answer
The stack creates an AWS Identification and Entry Administration (IAM) position with the precise degree of permission wanted to run the appliance. The LLM translation playground assumes this position mechanically in your behalf. To attain this, modify the position or principal beneath which you’re planning to run the appliance so you’re allowed to imagine the newly created position. You should utilize the pre-created coverage and fix it to your position. The coverage Amazon Useful resource Title (ARN) may be retrieved as a stack output beneath the important thing LLMTranslationPlaygroundAppRoleAssumePolicyArn, as illustrated within the previous screenshot. You are able to do so from the IAM console after choosing your position and selecting Add permissions. If you happen to choose to make use of the AWS Command Line Interface (AWS CLI), consult with the next pattern command line:
aws iam attach-role-policy --role-name <role-name> --policy-arn <policy-arn>Lastly, configure the .env file within the utils folder as follows:
- APP_ROLE_ARN – The ARN of the position created by the stack (stack output
LLMTranslationPlaygroundAppRoleArn) - HOST – OpenSearch Serverless assortment endpoint (with out https)
- REGION – AWS Area the gathering was deployed into
- INGESTION_LIMIT – Most quantity of translation models (
Run the answer
To begin the interpretation playground, run the next instructions:
cd llm-translation-playground/supply
streamlit run LLM_Translation_Home.pyYour default browser ought to open a brand new tab or window displaying the Dwelling web page.

Easy take a look at case
Let’s run a easy translation take a look at utilizing the phrase talked about earlier: “Did you carry out effectively?”
As a result of we’re not utilizing a data base for this take a look at case, we will use both a vector retailer or doc retailer. For this put up, we use a doc retailer.
- Select With Doc Retailer.
- For Supply Textual content, enter the textual content to be translated.
- Select your supply and goal languages (for this put up, English and French, respectively).
- You may experiment with different parameters, corresponding to mannequin, most tokens, temperature, and top-p.
- Select Translate.

The translated textual content seems within the backside part. For this instance, the translated textual content, though correct, is near a literal translation, which isn’t a standard phrasing in French.

- We are able to rerun the identical take a look at after barely modifying the preliminary textual content: “Did you carry out effectively on the soccer event?”
We’re now introducing some situational context within the enter. The translated textual content must be completely different and nearer to a extra pure translation. The brand new output actually means “Did you play effectively on the soccer event?”, which is in step with the preliminary intent of the query.

Additionally word the completion metrics on the left pane, displaying latency, enter/output tokens, and high quality scores.
This instance highlights the power of LLMs to naturally adapt the interpretation to the context.
Including translation reminiscence
Let’s take a look at the impression of utilizing a translation reminiscence TMX file on the interpretation high quality.
- Copy the textual content contained inside
take a look at/source_text.txtand paste into the Supply textual content - Select French because the goal language and run the interpretation.
- Copy the textual content contained inside
take a look at/target_text.txtand paste into the reference translation discipline.

- Select Consider and spot the standard scores on the left.
- Within the Translation Customization part, select Browse information and select the file
take a look at/subtitles_memory.tmx.
This can index the interpretation reminiscence into the OpenSearch Service assortment beforehand created. The indexing course of can take a couple of minutes.
- When the indexing is full, choose the created index from the index dropdown.
- Rerun the interpretation.
You must see a noticeable enhance within the high quality rating. As an example, we’ve seen as much as 20 share factors enchancment in BLEU rating with the previous take a look at case. Utilizing immediate engineering, we have been capable of steer the mannequin’s output by offering pattern phrases immediately pulled from the TMX file. Be at liberty to discover the generated immediate for extra particulars on how the interpretation pairs have been launched.
You may replicate an analogous take a look at case with Amazon Translate by launching an asynchronous job custom-made utilizing parallel knowledge.

Right here we took a simplistic retrieval method, which consists of loading all the samples as a part of the identical TMX file, matching the supply and goal language. You may improve this method by utilizing metadata-driven filtering to gather the related pairs in response to the supply textual content. For instance, you possibly can classify the paperwork by theme or enterprise area, and use class tags to pick out language pairs related to the textual content and desired output.
Semantic similarity for translation reminiscence choice
In vector retailer mode, the appliance permits you to add a TMX and create an area index that makes use of semantic similarity to pick out the interpretation reminiscence segments. First, we retrieve the section with the very best similarity rating primarily based on the textual content to be translated and the supply language. Then we retrieve the corresponding section matching the goal language and mother or father translation unit ID.
To attempt it out, add the file in the identical means as proven earlier. Relying on the scale of the file, this may take a couple of minutes. There’s a most restrict of 200 MB. You should utilize the pattern file as within the earlier instance or one of many different samples supplied within the code repository.
This method differs from the static index search as a result of it’s assumed that the supply textual content is semantically near segments consultant sufficient of the anticipated model and tone.

Including customized terminology
Customized terminology permits you to guarantee that your model names, character names, mannequin names, and different distinctive content material get translated to the specified outcome. On condition that LLMs are pre-trained on huge quantities of knowledge, they’ll probably already establish distinctive names and render them precisely within the output. If there are names for which you need to implement a strict and literal translation, you possibly can attempt the customized terminology characteristic of this translate playground. Merely present the supply and goal language pairs separated by semicolon within the Translation Customization part. As an example, if you wish to hold the phrase “Gen AI” untranslated whatever the language, you possibly can configure the customized terminology as illustrated within the following screenshot.

Clear up
To delete the stack, navigate to the deployment folder and run:cdk destroy.
Additional issues
Utilizing present TMX information with generative AI-based translation programs can probably enhance the standard and consistency of translations. The next are some steps to make use of TMX information for generative AI translations:
- TMX knowledge pipeline – TMX information include structured translation models, however the format would possibly should be preprocessed to extract the supply and goal textual content segments in a format that may be consumed by the generative AI mannequin. This includes extract, rework, and cargo (ETL) pipelines capable of parse the XML construction, deal with encoding points, and add metadata.
- Incorporate high quality estimation and human assessment – Though generative AI fashions can produce high-quality translations, it is strongly recommended to include high quality estimation methods and human assessment processes. You should utilize automated high quality estimation fashions to flag probably low-quality translations, which might then be reviewed and corrected by human translators.
- Iterate and refine – Translation tasks typically contain iterative cycles of translation, assessment, and enchancment. You may periodically retrain or fine-tune the generative AI mannequin with the up to date TMX file, making a virtuous cycle of steady enchancment.
Conclusion
The LLM translation playground introduced on this put up allows you consider the usage of LLMs to your machine translation wants. The important thing options of this answer embrace:
- Capability to make use of translation reminiscence – The answer permits you to combine your present TM knowledge, saved within the industry-standard TMX format, immediately into the LLM translation course of. This helps enhance the accuracy and consistency of the translations by utilizing high-quality human-translated content material.
- Immediate engineering capabilities – The answer showcases the facility of immediate engineering, demonstrating how LLMs may be steered to provide extra pure and contextual translations by rigorously crafting the enter prompts. This contains the power to include customized terminology and domain-specific data.
- Analysis metrics – The answer contains commonplace translation high quality analysis metrics, corresponding to BLEU, BERT Rating, METEOR, and CHRF, that can assist you assess the standard and effectiveness of the LLM-powered translations in comparison with their your present machine translation workflows.
Because the {industry} continues to discover the usage of LLMs, this answer may help you acquire invaluable insights and knowledge to find out if LLMs can change into a viable and invaluable possibility to your content material translation and localization workloads.
To dive deeper into the fast-moving discipline of LLM-based machine translation on AWS, take a look at the next assets:
In regards to the Authors
 Narcisse Zekpa is a Sr. Options Architect primarily based in Boston. He helps clients within the Northeast U.S. speed up their enterprise transformation by means of revolutionary, and scalable options, on the AWS Cloud. He’s obsessed with enabling organizations to remodel rework their enterprise, utilizing superior analytics and AI. When Narcisse isn’t constructing, he enjoys spending time along with his household, touring, working, cooking and taking part in basketball.
Narcisse Zekpa is a Sr. Options Architect primarily based in Boston. He helps clients within the Northeast U.S. speed up their enterprise transformation by means of revolutionary, and scalable options, on the AWS Cloud. He’s obsessed with enabling organizations to remodel rework their enterprise, utilizing superior analytics and AI. When Narcisse isn’t constructing, he enjoys spending time along with his household, touring, working, cooking and taking part in basketball.
 Ajeeb Peter is a Principal Options Architect with Amazon Net Companies primarily based in Charlotte, North Carolina, the place he guides world monetary companies clients to construct extremely safe, scalable, dependable, and cost-efficient purposes on the cloud. He brings over 20 years of expertise expertise on Software program Improvement, Structure and Analytics from industries like finance and telecom
Ajeeb Peter is a Principal Options Architect with Amazon Net Companies primarily based in Charlotte, North Carolina, the place he guides world monetary companies clients to construct extremely safe, scalable, dependable, and cost-efficient purposes on the cloud. He brings over 20 years of expertise expertise on Software program Improvement, Structure and Analytics from industries like finance and telecom



{kind=link}