
Utilizing information graphs and AI to retrieve, filter, and summarize medical journal articles
The accompanying code for the app and pocket book are right here.
Data graphs (KGs) and Massive Language Fashions (LLMs) are a match made in heaven. My earlier posts focus on the complementarities of those two applied sciences in additional element however the quick model is, “among the primary weaknesses of LLMs, that they’re black-box fashions and battle with factual information, are a few of KGs’ biggest strengths. KGs are, basically, collections of details, and they’re absolutely interpretable.”
This text is all about constructing a easy Graph RAG app. What’s RAG? RAG, or Retrieval-Augmented Technology, is about retrieving related info to increase a immediate that’s despatched to an LLM, which generates a response. Graph RAG is RAG that makes use of a information graph as a part of the retrieval portion. In the event you’ve by no means heard of Graph RAG, or desire a refresher, I’d watch this video.
The essential concept is that, moderately than sending your immediate on to an LLM, which was not educated in your information, you may complement your immediate with the related info wanted for the LLM to reply your immediate precisely. The instance I exploit usually is copying a job description and my resume into ChatGPT to write down a canopy letter. The LLM is ready to present a way more related response to my immediate, ‘write me a canopy letter,’ if I give it my resume and the outline of the job I’m making use of for. Since information graphs are constructed to retailer information, they’re an ideal method to retailer inner information and complement LLM prompts with further context, bettering the accuracy and contextual understanding of the responses.
This know-how has many, many, purposes such customer support bots, drug discovery, automated regulatory report technology in life sciences, expertise acquisition and administration for HR, authorized analysis and writing, and wealth advisor assistants. Due to the broad applicability and the potential to enhance the efficiency of LLM instruments, Graph RAG (that’s the time period I’ll use right here) has been blowing up in reputation. Here’s a graph displaying curiosity over time based mostly on Google searches.

Graph RAG has skilled a surge in search curiosity, even surpassing phrases like information graphs and retrieval-augmented technology. Notice that Google Developments measures relative search curiosity, not absolute variety of searches. The spike in July 2024 for searches of Graph RAG coincides with the week Microsoft introduced that their GraphRAG utility could be accessible on GitHub.
The thrill round Graph RAG is broader than simply Microsoft, nonetheless. Samsung acquired RDFox, a information graph firm, in July of 2024. The article saying that acquisition didn’t point out Graph RAG explicitly, however in this text in Forbes printed in November 2024, a Samsung spokesperson acknowledged, “We plan to develop information graph know-how, one of many primary applied sciences of personalised AI, and organically join with generated AI to assist user-specific companies.”
In October 2024, Ontotext, a number one graph database firm, and Semantic Net firm, the maker of PoolParty, a information graph curation platform, merged to type Graphwise. In keeping with the press launch, the merger goals to “democratize the evolution of Graph RAG as a class.”
Whereas among the buzz round Graph RAG might come from the broader pleasure surrounding chatbots and generative AI, it displays a real evolution in how information graphs are being utilized to resolve complicated, real-world issues. One instance is that LinkedIn utilized Graph RAG to enhance their customer support technical assist. As a result of the software was in a position to retrieve the related information (like beforehand solved related tickets or questions) to feed the LLM, the responses have been extra correct and the imply decision time dropped from 40 hours to fifteen hours.
This submit will undergo the development of a fairly easy, however I feel illustrative, instance of how Graph RAG can work in observe. The tip result’s an app {that a} non-technical person can work together with. Like my final submit, I’ll use a dataset consisting of medical journal articles from PubMed. The concept is that that is an app that somebody within the medical discipline may use to do literature overview. The identical ideas could be utilized to many use circumstances nonetheless, which is why Graph RAG is so thrilling.
The construction of the app, together with this submit is as follows:
Step zero is making ready the info. I’ll clarify the main points beneath however the general aim is to vectorize the uncooked information and, individually, flip it into an RDF graph. So long as we maintain URIs tied to the articles earlier than we vectorize, we are able to navigate throughout a graph of articles and a vector house of articles. Then, we are able to:
- Search Articles: use the facility of the vector database to do an preliminary search of related articles given a search time period. I’ll use vector similarity to retrieve articles with essentially the most related vectors to that of the search time period.
- Refine Phrases: discover the Medical Topic Headings (MeSH) biomedical vocabulary to pick phrases to make use of to filter the articles from step 1. This managed vocabulary incorporates medical phrases, different names, narrower ideas, and lots of different properties and relationships.
- Filter & Summarize: use the MeSH phrases to filter the articles to keep away from ‘context poisoning’. Then ship the remaining articles to an LLM together with a further immediate like, “summarize in bullets.”
Some notes on this app and tutorial earlier than we get began:
- This set-up makes use of information graphs completely for metadata. That is solely potential as a result of every article in my dataset has already been tagged with phrases which can be a part of a wealthy managed vocabulary. I’m utilizing the graph for construction and semantics and the vector database for similarity-based retrieval, making certain every know-how is used for what it does greatest. Vector similarity can inform us “esophageal most cancers” is semantically just like “mouth most cancers”, however information graphs can inform us the main points of the connection between “esophageal most cancers” and “mouth most cancers.”
- The information I used for this app is a group of medical journal articles from PubMed (extra on the info beneath). I selected this dataset as a result of it’s structured (tabular) but in addition incorporates textual content within the type of abstracts for every article, and since it’s already tagged with topical phrases which can be aligned with a well-established managed vocabulary (MeSH). As a result of these are medical articles, I’ve referred to as this app ‘Graph RAG for Drugs.’ However this identical construction could be utilized to any area and isn’t particular to the medical discipline.
- What I hope this tutorial and app exhibit is you can enhance the outcomes of your RAG utility by way of accuracy and explainability by incorporating a information graph into the retrieval step. I’ll present how KGs can enhance the accuracy of RAG purposes in two methods: by giving the person a method of filtering the context to make sure the LLM is just being fed essentially the most related info; and through the use of area particular managed vocabularies with dense relationships which can be maintained and curated by area consultants to do the filtering.
- What this tutorial and app don’t immediately showcase are two different vital methods KGs can improve RAG purposes: governance, entry management, and regulatory compliance; and effectivity and scalability. For governance, KGs can do greater than filter content material for relevancy to enhance accuracy — they will implement information governance insurance policies. For example, if a person lacks permission to entry sure content material, that content material could be excluded from their RAG pipeline. On the effectivity and scalability aspect, KGs will help guarantee RAG purposes don’t die on the shelf. Whereas it’s straightforward to create a powerful one-off RAG app (that’s actually the aim of this tutorial), many corporations battle with a proliferation of disconnected POCs that lack a cohesive framework, construction, or platform. Which means lots of these apps usually are not going to outlive lengthy. A metadata layer powered by KGs can break down information silos, offering the muse wanted to construct, scale, and preserve RAG purposes successfully. Utilizing a wealthy managed vocabulary like MeSH for the metadata tags on these articles is a method of making certain this Graph RAG app could be built-in with different techniques and lowering the danger that it turns into a silo.
The code to organize the info is in this pocket book.
As talked about, I’ve once more determined to make use of this dataset of fifty,000 analysis articles from the PubMed repository (License CC0: Public Area). This dataset incorporates the title of the articles, their abstracts, in addition to a discipline for metadata tags. These tags are from the Medical Topic Headings (MeSH) managed vocabulary thesaurus. The PubMed articles are actually simply metadata on the articles — there are abstracts for every article however we don’t have the complete textual content. The information is already in tabular format and tagged with MeSH phrases.
We are able to vectorize this tabular dataset immediately. We may flip it right into a graph (RDF) earlier than we vectorize, however I didn’t do this for this app and I don’t know that it will assist the ultimate outcomes for this sort of information. A very powerful factor about vectorizing the uncooked information is that we add Distinctive Useful resource Identifiers (URIs) to every article first. A URI is a singular ID for navigating RDF information and it’s vital for us to commute between vectors and entities in our graph. Moreover, we’ll create a separate assortment in our vector database for the MeSH phrases. It will permit the person to seek for related phrases with out having prior information of this managed vocabulary. Beneath is a diagram of what we’re doing to organize our information.

We now have two collections in our vector database to question: articles and phrases. We even have the info represented as a graph in RDF format. Since MeSH has an API, I’m simply going to question the API on to get different names and narrower ideas for phrases.
Vectorize information in Weaviate
First import the required packages and arrange the Weaviate shopper:
import weaviate
from weaviate.util import generate_uuid5
from weaviate.lessons.init import Auth
import os
import json
import pandas as pdshopper = weaviate.connect_to_weaviate_cloud(
cluster_url="XXX", # Change along with your Weaviate Cloud URL
auth_credentials=Auth.api_key("XXX"), # Change along with your Weaviate Cloud key
headers={'X-OpenAI-Api-key': "XXX"} # Change along with your OpenAI API key
)
Learn within the PubMed journal articles. I’m utilizing Databricks to run this pocket book so you might want to vary this, relying on the place you run it. The aim right here is simply to get the info right into a pandas DataFrame.
df = spark.sql("SELECT * FROM workspace.default.pub_med_multi_label_text_classification_dataset_processed").toPandas()
In the event you’re operating this regionally, simply do:
df = pd.read_csv("PubMed Multi Label Textual content Classification Dataset Processed.csv")
Then clear the info up a bit:
import numpy as np
# Change infinity values with NaN after which fill NaN values
df.exchange([np.inf, -np.inf], np.nan, inplace=True)
df.fillna('', inplace=True)# Convert columns to string sort
df['Title'] = df['Title'].astype(str)
df['abstractText'] = df['abstractText'].astype(str)
df['meshMajor'] = df['meshMajor'].astype(str)
Now we have to create a URI for every article and add that in as a brand new column. That is necessary as a result of the URI is the way in which we are able to join the vector illustration of an article with the information graph illustration of the article.
import urllib.parse
from rdflib import Graph, RDF, RDFS, Namespace, URIRef, Literal# Operate to create a sound URI
def create_valid_uri(base_uri, textual content):
if pd.isna(textual content):
return None
# Encode textual content for use in URI
sanitized_text = urllib.parse.quote(textual content.strip().exchange(' ', '_').exchange('"', '').exchange('<', '').exchange('>', '').exchange("'", "_"))
return URIRef(f"{base_uri}/{sanitized_text}")
# Operate to create a sound URI for Articles
def create_article_uri(title, base_namespace="http://instance.org/article/"):
"""
Creates a URI for an article by changing non-word characters with underscores and URL-encoding.
Args:
title (str): The title of the article.
base_namespace (str): The bottom namespace for the article URI.
Returns:
URIRef: The formatted article URI.
"""
if pd.isna(title):
return None
# Change non-word characters with underscores
sanitized_title = re.sub(r'W+', '_', title.strip())
# Condense a number of underscores right into a single underscore
sanitized_title = re.sub(r'_+', '_', sanitized_title)
# URL-encode the time period
encoded_title = quote(sanitized_title)
# Concatenate with base_namespace with out including underscores
uri = f"{base_namespace}{encoded_title}"
return URIRef(uri)
# Add a brand new column to the DataFrame for the article URIs
df['Article_URI'] = df['Title'].apply(lambda title: create_valid_uri("http://instance.org/article", title))
We additionally wish to create a DataFrame of all the MeSH phrases which can be used to tag the articles. This can be useful later after we wish to seek for related MeSH phrases.
# Operate to scrub and parse MeSH phrases
def parse_mesh_terms(mesh_list):
if pd.isna(mesh_list):
return []
return [
term.strip().replace(' ', '_')
for term in mesh_list.strip("[]'").cut up(',')
]# Operate to create a sound URI for MeSH phrases
def create_valid_uri(base_uri, textual content):
if pd.isna(textual content):
return None
sanitized_text = urllib.parse.quote(
textual content.strip()
.exchange(' ', '_')
.exchange('"', '')
.exchange('<', '')
.exchange('>', '')
.exchange("'", "_")
)
return f"{base_uri}/{sanitized_text}"
# Extract and course of all MeSH phrases
all_mesh_terms = []
for mesh_list in df["meshMajor"]:
all_mesh_terms.prolong(parse_mesh_terms(mesh_list))
# Deduplicate phrases
unique_mesh_terms = checklist(set(all_mesh_terms))
# Create a DataFrame of MeSH phrases and their URIs
mesh_df = pd.DataFrame({
"meshTerm": unique_mesh_terms,
"URI": [create_valid_uri("http://example.org/mesh", term) for term in unique_mesh_terms]
})
# Show the DataFrame
print(mesh_df)
Vectorize the articles DataFrame:
from weaviate.lessons.config import Configure#outline the gathering
articles = shopper.collections.create(
identify = "Article",
vectorizer_config=Configure.Vectorizer.text2vec_openai(), # If set to "none" you will need to at all times present vectors your self. Might be another "text2vec-*" additionally.
generative_config=Configure.Generative.openai(), # Make sure the `generative-openai` module is used for generative queries
)
#add ojects
articles = shopper.collections.get("Article")
with articles.batch.dynamic() as batch:
for index, row in df.iterrows():
batch.add_object({
"title": row["Title"],
"abstractText": row["abstractText"],
"Article_URI": row["Article_URI"],
"meshMajor": row["meshMajor"],
})
Now vectorize the MeSH phrases:
#outline the gathering
phrases = shopper.collections.create(
identify = "time period",
vectorizer_config=Configure.Vectorizer.text2vec_openai(), # If set to "none" you will need to at all times present vectors your self. Might be another "text2vec-*" additionally.
generative_config=Configure.Generative.openai(), # Make sure the `generative-openai` module is used for generative queries
)#add ojects
phrases = shopper.collections.get("time period")
with phrases.batch.dynamic() as batch:
for index, row in mesh_df.iterrows():
batch.add_object({
"meshTerm": row["meshTerm"],
"URI": row["URI"],
})
You possibly can, at this level, run semantic search, similarity search, and RAG immediately in opposition to the vectorized dataset. I received’t undergo all of that right here however you may take a look at the code in my accompanying pocket book to try this.
Flip information right into a information graph
I’m simply utilizing the identical code we used within the final submit to do that. We’re principally turning each row within the information into an “Article” entity in our KG. Then we’re giving every of those articles properties for title, summary, and MeSH phrases. We’re additionally turning each MeSH time period into an entity as properly. This code additionally provides random dates to every article for a property referred to as date printed and a random quantity between 1 and 10 to a property referred to as entry. We received’t use these properties on this demo. Beneath is a visible illustration of the graph we’re creating from the info.

Right here is how one can iterate by means of the DataFrame and switch it into RDF information:
from rdflib import Graph, RDF, RDFS, Namespace, URIRef, Literal
from rdflib.namespace import SKOS, XSD
import pandas as pd
import urllib.parse
import random
from datetime import datetime, timedelta
import re
from urllib.parse import quote# --- Initialization ---
g = Graph()
# Outline namespaces
schema = Namespace('http://schema.org/')
ex = Namespace('http://instance.org/')
prefixes = {
'schema': schema,
'ex': ex,
'skos': SKOS,
'xsd': XSD
}
for p, ns in prefixes.objects():
g.bind(p, ns)
# Outline lessons and properties
Article = URIRef(ex.Article)
MeSHTerm = URIRef(ex.MeSHTerm)
g.add((Article, RDF.sort, RDFS.Class))
g.add((MeSHTerm, RDF.sort, RDFS.Class))
title = URIRef(schema.identify)
summary = URIRef(schema.description)
date_published = URIRef(schema.datePublished)
entry = URIRef(ex.entry)
g.add((title, RDF.sort, RDF.Property))
g.add((summary, RDF.sort, RDF.Property))
g.add((date_published, RDF.sort, RDF.Property))
g.add((entry, RDF.sort, RDF.Property))
# Operate to scrub and parse MeSH phrases
def parse_mesh_terms(mesh_list):
if pd.isna(mesh_list):
return []
return [term.strip() for term in mesh_list.strip("[]'").cut up(',')]
# Enhanced convert_to_uri perform
def convert_to_uri(time period, base_namespace="http://instance.org/mesh/"):
"""
Converts a MeSH time period right into a standardized URI by changing areas and particular characters with underscores,
making certain it begins and ends with a single underscore, and URL-encoding the time period.
Args:
time period (str): The MeSH time period to transform.
base_namespace (str): The bottom namespace for the URI.
Returns:
URIRef: The formatted URI.
"""
if pd.isna(time period):
return None # Deal with NaN or None phrases gracefully
# Step 1: Strip present main and trailing non-word characters (together with underscores)
stripped_term = re.sub(r'^W+|W+$', '', time period)
# Step 2: Change non-word characters with underscores (a number of)
formatted_term = re.sub(r'W+', '_', stripped_term)
# Step 3: Change a number of consecutive underscores with a single underscore
formatted_term = re.sub(r'_+', '_', formatted_term)
# Step 4: URL-encode the time period to deal with any remaining particular characters
encoded_term = quote(formatted_term)
# Step 5: Add single main and trailing underscores
term_with_underscores = f"_{encoded_term}_"
# Step 6: Concatenate with base_namespace with out including an additional underscore
uri = f"{base_namespace}{term_with_underscores}"
return URIRef(uri)
# Operate to generate a random date throughout the final 5 years
def generate_random_date():
start_date = datetime.now() - timedelta(days=5*365)
random_days = random.randint(0, 5*365)
return start_date + timedelta(days=random_days)
# Operate to generate a random entry worth between 1 and 10
def generate_random_access():
return random.randint(1, 10)
# Operate to create a sound URI for Articles
def create_article_uri(title, base_namespace="http://instance.org/article"):
"""
Creates a URI for an article by changing non-word characters with underscores and URL-encoding.
Args:
title (str): The title of the article.
base_namespace (str): The bottom namespace for the article URI.
Returns:
URIRef: The formatted article URI.
"""
if pd.isna(title):
return None
# Encode textual content for use in URI
sanitized_text = urllib.parse.quote(title.strip().exchange(' ', '_').exchange('"', '').exchange('<', '').exchange('>', '').exchange("'", "_"))
return URIRef(f"{base_namespace}/{sanitized_text}")
# Loop by means of every row within the DataFrame and create RDF triples
for index, row in df.iterrows():
article_uri = create_article_uri(row['Title'])
if article_uri is None:
proceed
# Add Article occasion
g.add((article_uri, RDF.sort, Article))
g.add((article_uri, title, Literal(row['Title'], datatype=XSD.string)))
g.add((article_uri, summary, Literal(row['abstractText'], datatype=XSD.string)))
# Add random datePublished and entry
random_date = generate_random_date()
random_access = generate_random_access()
g.add((article_uri, date_published, Literal(random_date.date(), datatype=XSD.date)))
g.add((article_uri, entry, Literal(random_access, datatype=XSD.integer)))
# Add MeSH Phrases
mesh_terms = parse_mesh_terms(row['meshMajor'])
for time period in mesh_terms:
term_uri = convert_to_uri(time period, base_namespace="http://instance.org/mesh/")
if term_uri is None:
proceed
# Add MeSH Time period occasion
g.add((term_uri, RDF.sort, MeSHTerm))
g.add((term_uri, RDFS.label, Literal(time period.exchange('_', ' '), datatype=XSD.string)))
# Hyperlink Article to MeSH Time period
g.add((article_uri, schema.about, term_uri))
# Path to save lots of the file
file_path = "/Workspace/PubMedGraph.ttl"
# Save the file
g.serialize(vacation spot=file_path, format='turtle')
print(f"File saved at {file_path}")
OK, so now we’ve a vectorized model of the info, and a graph (RDF) model of the info. Every vector has a URI related to it, which corresponds to an entity within the KG, so we are able to commute between the info codecs.
I made a decision to make use of Streamlit to construct the interface for this graph RAG app. Just like the final weblog submit, I’ve stored the person movement the identical.
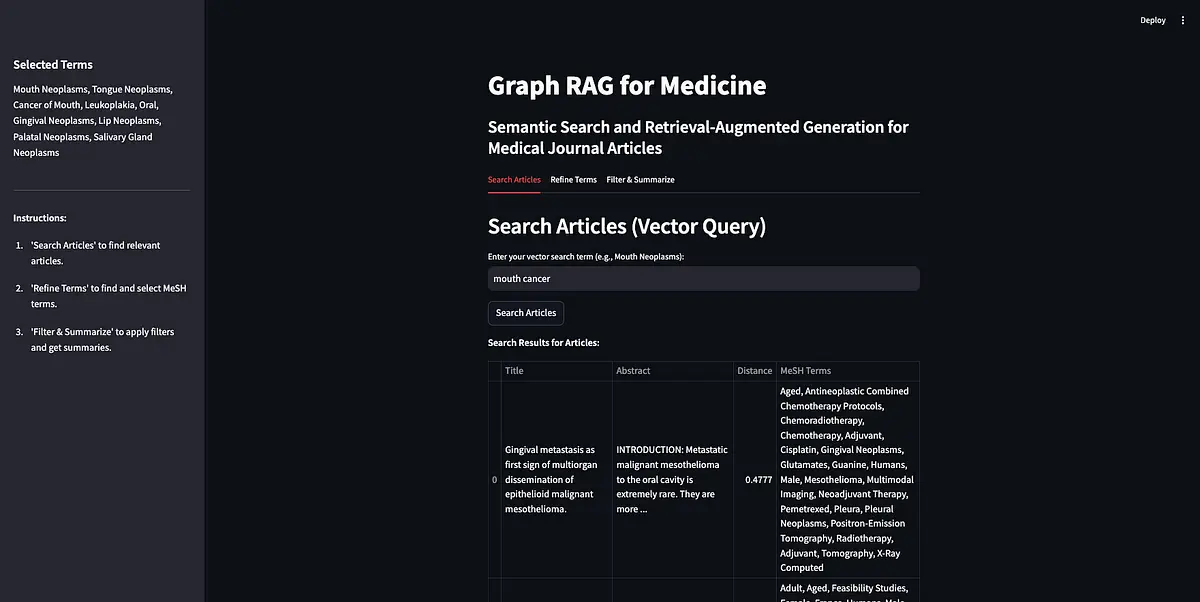
- Search Articles: First, the person searches for articles utilizing a search time period. This depends completely on the vector database. The person’s search time period(s) is distributed to the vector database and the ten articles nearest the time period in vector house are returned.
- Refine Phrases: Second, the person decides the MeSH phrases to make use of to filter the returned outcomes. Since we additionally vectorized the MeSH phrases, we are able to have the person enter a pure language immediate to get essentially the most related MeSH phrases. Then, we permit the person to broaden these phrases to see their different names and narrower ideas. The person can choose as many phrases as they need for his or her filter standards.
- Filter & Summarize: Third, the person applies the chosen phrases as filters to the unique ten journal articles. We are able to do that because the PubMed articles are tagged with MeSH phrases. Lastly, we let the person enter a further immediate to ship to the LLM together with the filtered journal articles. That is the generative step of the RAG app.
Let’s undergo these steps one by one. You possibly can see the complete app and code on my GitHub, however right here is the construction:
-- app.py (a python file that drives the app and calls different capabilities as wanted)
-- query_functions (a folder containing python information with queries)
-- rdf_queries.py (python file with RDF queries)
-- weaviate_queries.py (python file containing weaviate queries)
-- PubMedGraph.ttl (the pubmed information in RDF format, saved as a ttl file)
Search Articles
First, wish to do is implement Weaviate’s vector similarity search. Since our articles are vectorized, we are able to ship a search time period to the vector database and get related articles again.

The primary perform that searches for related journal articles within the vector database is in app.py:
# --- TAB 1: Search Articles ---
with tab_search:
st.header("Search Articles (Vector Question)")
query_text = st.text_input("Enter your vector search time period (e.g., Mouth Neoplasms):", key="vector_search")if st.button("Search Articles", key="search_articles_btn"):
attempt:
shopper = initialize_weaviate_client()
article_results = query_weaviate_articles(shopper, query_text)
# Extract URIs right here
article_uris = [
result["properties"].get("article_URI")
for end in article_results
if consequence["properties"].get("article_URI")
]
# Retailer article_uris within the session state
st.session_state.article_uris = article_uris
st.session_state.article_results = [
{
"Title": result["properties"].get("title", "N/A"),
"Summary": (consequence["properties"].get("abstractText", "N/A")[:100] + "..."),
"Distance": consequence["distance"],
"MeSH Phrases": ", ".be part of(
ast.literal_eval(consequence["properties"].get("meshMajor", "[]"))
if consequence["properties"].get("meshMajor") else []
),
}
for end in article_results
]
shopper.shut()
besides Exception as e:
st.error(f"Error throughout article search: {e}")
if st.session_state.article_results:
st.write("**Search Outcomes for Articles:**")
st.desk(st.session_state.article_results)
else:
st.write("No articles discovered but.")
This perform makes use of the queries saved in weaviate_queries to determine the Weaviate shopper (initialize_weaviate_client) and seek for articles (query_weaviate_articles). Then we show the returned articles in a desk, together with their abstracts, distance (how shut they’re to the search time period), and the MeSH phrases that they’re tagged with.
The perform to question Weaviate in weaviate_queries.py appears to be like like this:
# Operate to question Weaviate for Articles
def query_weaviate_articles(shopper, query_text, restrict=10):
# Carry out vector search on Article assortment
response = shopper.collections.get("Article").question.near_text(
question=query_text,
restrict=restrict,
return_metadata=MetadataQuery(distance=True)
)# Parse response
outcomes = []
for obj in response.objects:
outcomes.append({
"uuid": obj.uuid,
"properties": obj.properties,
"distance": obj.metadata.distance,
})
return outcomes
As you may see, I put a restrict of ten outcomes right here simply to make it easier, however you may change that. That is simply utilizing vector similarity search in Weaviate to return related outcomes.
The tip consequence within the app appears to be like like this:



{kind=link}