At this time, we’re excited to announce that the Llama 3.3 70B from Meta is on the market in Amazon SageMaker JumpStart. Llama 3.3 70B marks an thrilling development in giant language mannequin (LLM) growth, providing comparable efficiency to bigger Llama variations with fewer computational sources.
On this submit, we discover the right way to deploy this mannequin effectively on Amazon SageMaker AI, utilizing superior SageMaker AI options for optimum efficiency and value administration.
Overview of the Llama 3.3 70B mannequin
Llama 3.3 70B represents a major breakthrough in mannequin effectivity and efficiency optimization. This new mannequin delivers output high quality akin to Llama 3.1 405B whereas requiring solely a fraction of the computational sources. In line with Meta, this effectivity achieve interprets to almost 5 occasions less expensive inference operations, making it a horny possibility for manufacturing deployments.
The mannequin’s subtle structure builds upon Meta’s optimized model of the transformer design, that includes an enhanced consideration mechanism that may assist considerably cut back inference prices. Throughout its growth, Meta’s engineering crew skilled the mannequin on an in depth dataset comprising roughly 15 trillion tokens, incorporating each web-sourced content material and over 25 million artificial examples particularly created for LLM growth. This complete coaching method leads to the mannequin’s sturdy understanding and era capabilities throughout numerous duties.
What units Llama 3.3 70B aside is its refined coaching methodology. The mannequin underwent an in depth supervised fine-tuning course of, complemented by Reinforcement Studying from Human Suggestions (RLHF). This dual-approach coaching technique helps align the mannequin’s outputs extra carefully with human preferences whereas sustaining excessive efficiency requirements. In benchmark evaluations towards its bigger counterpart, Llama 3.3 70B demonstrated exceptional consistency, trailing Llama 3.1 405B by lower than 2% in 6 out of 10 commonplace AI benchmarks and truly outperforming it in three classes. This efficiency profile makes it a great candidate for organizations searching for to stability mannequin capabilities with operational effectivity.
The next determine summarizes the benchmark outcomes (supply).

Getting began with SageMaker JumpStart
SageMaker JumpStart is a machine studying (ML) hub that may assist speed up your ML journey. With SageMaker JumpStart, you possibly can consider, examine, and choose pre-trained basis fashions (FMs), together with Llama 3 fashions. These fashions are absolutely customizable on your use case along with your knowledge, and you’ll deploy them into manufacturing utilizing both the UI or SDK.
Deploying Llama 3.3 70B by means of SageMaker JumpStart presents two handy approaches: utilizing the intuitive SageMaker JumpStart UI or implementing programmatically by means of the SageMaker Python SDK. Let’s discover each strategies that can assist you select the method that most accurately fits your wants.
Deploy Llama 3.3 70B by means of the SageMaker JumpStart UI
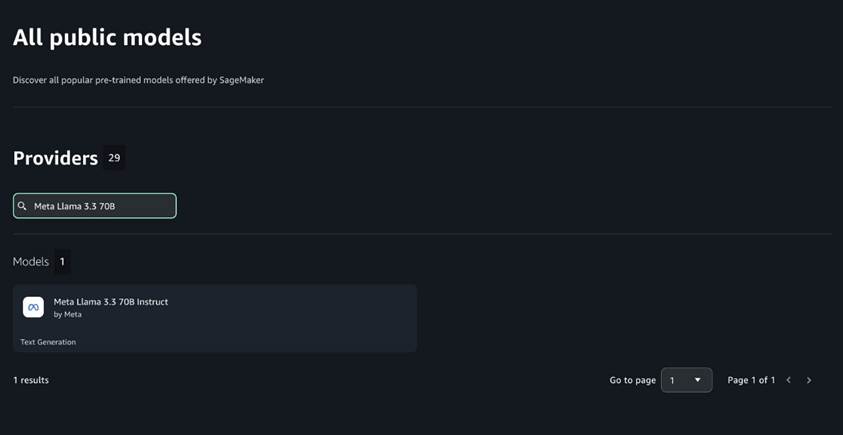
You may entry the SageMaker JumpStart UI by means of both Amazon SageMaker Unified Studio or Amazon SageMaker Studio. To deploy Llama 3.3 70B utilizing the SageMaker JumpStart UI, full the next steps:
- In SageMaker Unified Studio, on the Construct menu, select JumpStart fashions.

Alternatively, on the SageMaker Studio console, select JumpStart within the navigation pane.
- Seek for Meta Llama 3.3 70B.

- Select the Meta Llama 3.3 70B mannequin.

- Select Deploy.

- Settle for the end-user license settlement (EULA).
- For Occasion kind¸ select an occasion (ml.g5.48xlarge or ml.p4d.24xlarge).
- Select Deploy.

Wait till the endpoint standing reveals as InService. Now you can run inference utilizing the mannequin.
Deploy Llama 3.3 70B utilizing the SageMaker Python SDK
For groups trying to automate deployment or combine with present MLOps pipelines, you need to use the next code to deploy the mannequin utilizing the SageMaker Python SDK:
Arrange auto scaling and scale all the way down to zero
You may optionally arrange auto scaling to scale all the way down to zero after deployment. For extra data, consult with Unlock value financial savings with the brand new scale all the way down to zero function in SageMaker Inference.
Optimize deployment with SageMaker AI
SageMaker AI simplifies the deployment of subtle fashions like Llama 3.3 70B, providing a variety of options designed to optimize each efficiency and value effectivity. With the superior capabilities of SageMaker AI, organizations can deploy and handle LLMs in manufacturing environments, taking full benefit of Llama 3.3 70B’s effectivity whereas benefiting from the streamlined deployment course of and optimization instruments of SageMaker AI. Default deployment by means of SageMaker JumpStart makes use of accelerated deployment, which makes use of speculative decoding to enhance throughput. For extra data on how speculative decoding works with SageMaker AI, see Amazon SageMaker launches the up to date inference optimization toolkit for generative AI.
Firstly, the Quick Mannequin Loader revolutionizes the mannequin initialization course of by implementing an revolutionary weight streaming mechanism. This function essentially modifications how mannequin weights are loaded onto accelerators, dramatically decreasing the time required to get the mannequin prepared for inference. As a substitute of the normal method of loading your complete mannequin into reminiscence earlier than starting operations, Quick Mannequin Loader streams weights immediately from Amazon Easy Storage Service (Amazon S3) to the accelerator, enabling quicker startup and scaling occasions.
One SageMaker inference functionality is Container Caching, which transforms how mannequin containers are managed throughout scaling operations. This function eliminates one of many main bottlenecks in deployment scaling by pre-caching container photographs, eradicating the necessity for time-consuming downloads when including new situations. For giant fashions like Llama 3.3 70B, the place container photographs could be substantial in dimension, this optimization considerably reduces scaling latency and improves total system responsiveness.
One other key functionality is Scale to Zero. It introduces clever useful resource administration that routinely adjusts compute capability based mostly on precise utilization patterns. This function represents a paradigm shift in value optimization for mannequin deployments, permitting endpoints to scale down fully during times of inactivity whereas sustaining the flexibility to scale up shortly when demand returns. This functionality is especially helpful for organizations working a number of fashions or coping with variable workload patterns.
Collectively, these options create a robust deployment surroundings that maximizes the advantages of Llama 3.3 70B’s environment friendly structure whereas offering sturdy instruments for managing operational prices and efficiency.
Conclusion
The mixture of Llama 3.3 70B with the superior inference options of SageMaker AI gives an optimum answer for manufacturing deployments. Through the use of Quick Mannequin Loader, Container Caching, and Scale to Zero capabilities, organizations can obtain each excessive efficiency and cost-efficiency of their LLM deployments.
We encourage you to do that implementation and share your experiences.
Concerning the authors
 Marc Karp is an ML Architect with the Amazon SageMaker Service crew. He focuses on serving to prospects design, deploy, and handle ML workloads at scale. In his spare time, he enjoys touring and exploring new locations.
Marc Karp is an ML Architect with the Amazon SageMaker Service crew. He focuses on serving to prospects design, deploy, and handle ML workloads at scale. In his spare time, he enjoys touring and exploring new locations.
 Saurabh Trikande is a Senior Product Supervisor for Amazon Bedrock and SageMaker Inference. He’s enthusiastic about working with prospects and companions, motivated by the purpose of democratizing AI. He focuses on core challenges associated to deploying complicated AI purposes, inference with multi-tenant fashions, value optimizations, and making the deployment of Generative AI fashions extra accessible. In his spare time, Saurabh enjoys mountain climbing, studying about revolutionary applied sciences, following TechCrunch, and spending time along with his household.
Saurabh Trikande is a Senior Product Supervisor for Amazon Bedrock and SageMaker Inference. He’s enthusiastic about working with prospects and companions, motivated by the purpose of democratizing AI. He focuses on core challenges associated to deploying complicated AI purposes, inference with multi-tenant fashions, value optimizations, and making the deployment of Generative AI fashions extra accessible. In his spare time, Saurabh enjoys mountain climbing, studying about revolutionary applied sciences, following TechCrunch, and spending time along with his household.
 Melanie Li, PhD, is a Senior Generative AI Specialist Options Architect at AWS based mostly in Sydney, Australia, the place her focus is on working with prospects to construct options leveraging state-of-the-art AI and machine studying instruments. She has been actively concerned in a number of Generative AI initiatives throughout APJ, harnessing the facility of Giant Language Fashions (LLMs). Previous to becoming a member of AWS, Dr. Li held knowledge science roles within the monetary and retail industries.
Melanie Li, PhD, is a Senior Generative AI Specialist Options Architect at AWS based mostly in Sydney, Australia, the place her focus is on working with prospects to construct options leveraging state-of-the-art AI and machine studying instruments. She has been actively concerned in a number of Generative AI initiatives throughout APJ, harnessing the facility of Giant Language Fashions (LLMs). Previous to becoming a member of AWS, Dr. Li held knowledge science roles within the monetary and retail industries.
 Adriana Simmons is a Senior Product Advertising Supervisor at AWS.
Adriana Simmons is a Senior Product Advertising Supervisor at AWS.
 Lokeshwaran Ravi is a Senior Deep Studying Compiler Engineer at AWS, specializing in ML optimization, mannequin acceleration, and AI safety. He focuses on enhancing effectivity, decreasing prices, and constructing safe ecosystems to democratize AI applied sciences, making cutting-edge ML accessible and impactful throughout industries.
Lokeshwaran Ravi is a Senior Deep Studying Compiler Engineer at AWS, specializing in ML optimization, mannequin acceleration, and AI safety. He focuses on enhancing effectivity, decreasing prices, and constructing safe ecosystems to democratize AI applied sciences, making cutting-edge ML accessible and impactful throughout industries.
 Yotam Moss is a Software program growth Supervisor for Inference at AWS AI.
Yotam Moss is a Software program growth Supervisor for Inference at AWS AI.


{kind=link}