Twitch, the world’s main live-streaming platform, has over 105 million common month-to-month guests. As a part of Amazon, Twitch promoting is dealt with by the advert gross sales group at Amazon. New advert merchandise throughout various markets contain a fancy internet of bulletins, coaching, and documentation, making it troublesome for gross sales groups to seek out exact data rapidly. In early 2024, Amazon launched a significant push to harness the facility of Twitch for advertisers globally. This necessitated the ramping up of Twitch data to all of Amazon advert gross sales. The duty at hand was particularly difficult to inside gross sales assist groups. With a ratio of over 30 sellers per specialist, questions posed in public channels usually took a mean of two hours for an preliminary reply, with 20% of questions not being answered in any respect. All in all, the complete course of from an advertiser’s request to the primary marketing campaign launch may stretch as much as 7 days.
On this submit, we show how we innovated to construct a Retrieval Augmented Technology (RAG) utility with agentic workflow and a data base on Amazon Bedrock. We carried out the RAG pipeline in a Slack chat-based assistant to empower the Amazon Twitch advertisements gross sales workforce to maneuver rapidly on new gross sales alternatives. We focus on the answer parts to construct a multimodal data base, drive agentic workflow, use metadata to deal with hallucinations, and likewise share the teachings discovered via the answer improvement utilizing a number of massive language fashions (LLMs) and Amazon Bedrock Information Bases.
Answer overview
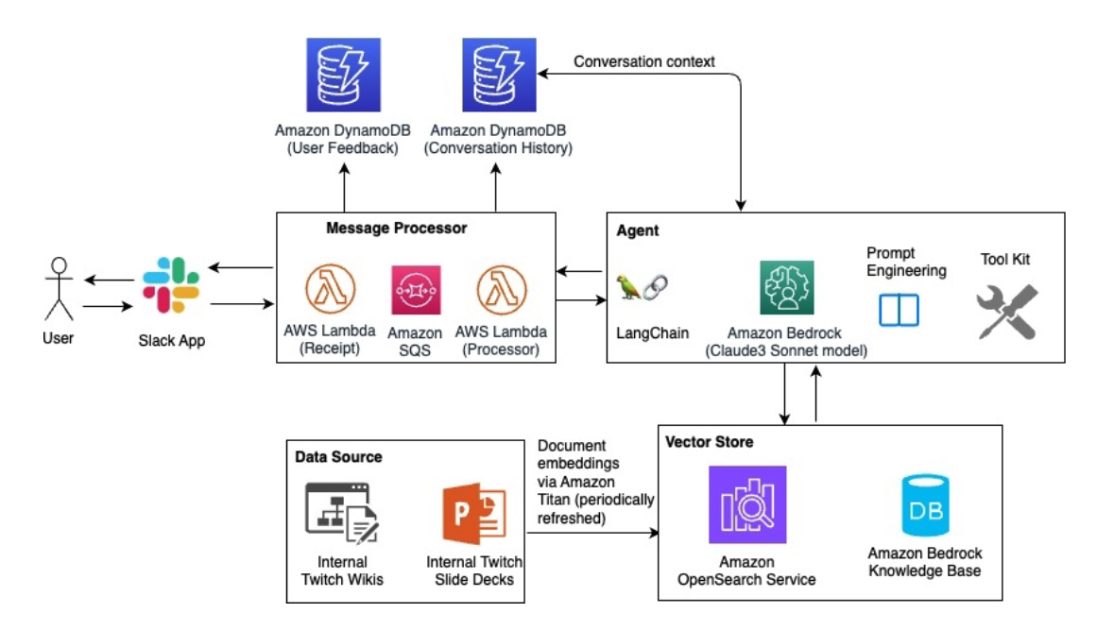
A RAG utility combines an LLM with a specialised data base to assist reply domain-specific questions. We developed an agentic workflow with RAG answer that revolves round a centralized data base that aggregates Twitch inside advertising and marketing documentation. This content material is then reworked right into a vector database optimized for environment friendly data retrieval. Within the RAG pipeline, the retriever faucets into this vector database to floor related data, and the LLM generates tailor-made responses to Twitch person queries submitted via a Slack assistant. The answer structure is offered within the following diagram.

The important thing architectural parts driving this answer embrace:
- Knowledge sources – A centralized repository containing advertising and marketing information aggregated from varied sources equivalent to wikis and slide decks, utilizing internet crawlers and periodic refreshes
- Vector database – The advertising and marketing contents are first embedded into vector representations utilizing Amazon Titan Multimodal Embeddings G1 on Amazon Bedrock, able to dealing with each textual content and picture information. These embeddings are then saved in an Amazon Bedrock data bases.
- Agentic workflow – The agent acts as an clever dispatcher. It evaluates every person question to find out the suitable plan of action, whether or not refusing to reply off-topic queries, tapping into the LLM, or invoking APIs and information sources such because the vector database. The agent makes use of chain-of-thought (CoT) reasoning, which breaks down complicated duties right into a sequence of smaller steps then dynamically generates prompts for every subtask, combines the outcomes, and synthesizes a closing coherent response.
- Slack integration – A message processor was carried out to interface with customers via a Slack assistant utilizing an AWS Lambda perform, offering a seamless conversational expertise.
Classes discovered and finest practices
The method of designing, implementing, and iterating a RAG utility with agentic workflow and a data base on Amazon Bedrock produced a number of helpful classes.
Processing multimodal supply paperwork within the data base
An early drawback we confronted was that Twitch documentation is scattered throughout the Amazon inside community. Not solely is there no centralized information retailer, however there may be additionally no consistency within the information format. Inside wikis include a combination of picture and textual content, and coaching supplies to gross sales brokers are sometimes within the type of PowerPoint shows. To make our chat assistant the simplest, we would have liked to coalesce all of this data collectively right into a single repository the LLM may perceive.
Step one was making a wiki crawler that uploaded all of the related Twitch wikis and PowerPoint slide decks to Amazon Easy Storage Service (Amazon S3). We used that because the supply to create a data base on Amazon Bedrock. To deal with the mixture of photos and textual content in our information supply, we used the Amazon Titan Multimodal Embeddings G1 mannequin. For the paperwork containing particular data equivalent to demographic context, we summarized a number of slides to make sure this data is included within the closing contexts for LLM.
In complete, our data base incorporates over 200 paperwork. Amazon Bedrock data bases are simple to amend, and we routinely add and delete paperwork primarily based on altering wikis or slide decks. Our data base is queried once in a while on daily basis, and metrics, dashboards, and alarms are inherently supported in Amazon Net Providers (AWS) via Amazon CloudWatch. These instruments present full transparency into the well being of the system and permit totally hands-off operation.
Agentic workflow for a variety of person queries
As we noticed our customers work together with our chat assistant, we observed that there have been some questions the usual RAG utility couldn’t reply. A few of these questions have been overly complicated, with a number of questions mixed, some requested for deep insights into Twitch viewers demographics, and a few had nothing to do with Twitch in any respect.
As a result of the usual RAG answer may solely reply easy questions and couldn’t deal with all these eventualities gracefully, we invested in an agentic workflow with RAG answer. On this answer, an agent breaks down the method of answering questions into a number of steps, and makes use of completely different instruments to reply various kinds of questions. We carried out an XML agent in LangChain, selecting XML as a result of the Anthropic Claude fashions out there in Amazon Bedrock are extensively skilled on XML information. As well as, we engineered our prompts to instruct the agent to undertake a specialised persona with area experience in promoting and the Twitch enterprise realm. The agent breaks down queries, gathers related data, analyzes context, and weighs potential options. The move for our chat agent is proven within the following diagram. Within the comply with, when the agent reads a person query, step one is to resolve whether or not the query is expounded to Twitch – if it isn’t, the agent politely refuses to reply. If the query is expounded to Twitch, the agent ‘thinks’ about which instrument is finest suited to reply the query. As an example, if the query is expounded to viewers forecasting, the agent will invoke Amazon inside Viewers Forecasting API. If the query is expounded to Twitch commercial merchandise, the agent will invoke its commercial data base. As soon as the agent fetches the outcomes from the suitable instrument, the agent will take into account the outcomes and suppose whether or not it now has sufficient data to reply the query. If it doesn’t, the agent will invoke its toolkit once more (most of three makes an attempt) to achieve extra context. As soon as its completed gathering data, the agent will generate a closing response and ship it to the person.
 |
One of many chief advantages of agentic AI is the flexibility to combine with a number of information sources. In our case, we use an inside forecasting API to fetch information associated to the out there Amazon and Twitch viewers provide. We additionally use Amazon Bedrock Information Bases to assist with questions on static information, equivalent to options of Twitch advert merchandise. This vastly elevated the scope of questions our chatbot may reply, which the preliminary RAG couldn’t assist. The agent is clever sufficient to know which instrument to make use of primarily based on the question. You solely want to supply high-level directions in regards to the instrument objective, and it’ll invoke the LLM to decide. For instance,
Even higher, LangChain logs the agent’s thought course of in CloudWatch. That is what a log assertion appears like when the agent decides which instrument to make use of:
The agent helps maintain our RAG versatile. Wanting in direction of the longer term, we plan to onboard extra APIs, construct new vector shops, and combine with chat assistants in different Amazon organizations. That is vital to serving to us broaden our product, maximizing its scope and influence.
Contextual compression for LLM invocation
In the course of the doc retrieval, we discovered that our inside wikis various vastly in measurement. This meant that always a wiki would include a whole lot and even hundreds of strains of textual content, however solely a small paragraph was related to answering the query. To cut back the scale of context and enter token to the LLM, we used one other LLM to carry out contextual compression to extract the related parts of the returned paperwork. Initially, we used Anthropic Claude Haiku due to its superior velocity. Nonetheless, we discovered that Anthropic Claude Sonnet boosted the consequence accuracy, whereas being solely 20% slower than Haiku (from 8 seconds to 10 seconds). Consequently, we selected Sonnet for our use case as a result of offering the very best quality solutions to our customers is a very powerful issue. We’re keen to take an extra 2 seconds latency, evaluating to the 2-day turn-around time within the conventional handbook course of.
Tackle hallucinations by doc metadata
As with all RAG answer, our chat assistant often hallucinated incorrect solutions. Whereas it is a well-recognized drawback with LLMs, it was notably pronounced in our system, due to the complexity of the Twitch promoting area. As a result of our customers relied on the chatbot responses to work together with their purchasers, they have been reluctant to belief even its right solutions, regardless of most solutions being right.
We elevated the customers’ belief by displaying them the place the LLM was getting its data from for every assertion made. This manner, if a person is skeptical of an announcement, they will examine the references the LLM used and skim via the authoritative documentation themselves. We achieved this by including the supply URL of the retrieved paperwork as metadata in our data base, which Amazon Bedrock straight helps. We then instructed the LLM to learn the metadata and append the supply URLs as clickable hyperlinks in its responses.
Right here’s an instance query and reply with citations:
Notice that the LLM responds with two sources. The primary is from a gross sales coaching PowerPoint slide deck, and the second is from an inside wiki. For the slide deck, the LLM can present the precise slide quantity it pulled the data from. That is particularly helpful as a result of some decks include over 100 slides.
After including citations, our person suggestions rating noticeably elevated. Our favorable suggestions fee elevated by 40% and total assistant utilization elevated by 20%, indicating that customers gained extra belief within the assistant’s responses because of the potential to confirm the solutions.
Human-in-the-loop suggestions assortment
Once we launched our chat assistant in Slack, we had a suggestions kind that customers may fill out. This included a number of inquiries to fee facets of the chat assistant on a 1–5 scale. Whereas the information was very wealthy, hardly anybody used it. After switching to a a lot less complicated thumb up or thumb down button {that a} person may effortlessly choose (the buttons are appended to every chatbot reply), our suggestions fee elevated by eightfold.
Conclusion
Shifting quick is vital within the AI panorama, particularly as a result of the expertise adjustments so quickly. Typically engineers may have an thought a couple of new method in AI and wish to try it out rapidly. Utilizing AWS companies helped us be taught quick about what applied sciences are efficient and what aren’t. We used Amazon Bedrock to check a number of basis fashions (FMs), together with Anthropic Claude Haiku and Sonnet, Meta Llama 3, Cohere embedding fashions, and Amazon Titan Multimodal Embeddings. Amazon Bedrock Information Bases helped us implement RAG with agentic workflow effectively with out constructing customized integrations to our varied multimodal information sources and information flows. Utilizing dynamic chunking and metadata filtering allow us to retrieve the wanted contents extra precisely. All these collectively allowed us to spin up a working prototype in a couple of days as a substitute of months. After we deployed the adjustments to our clients, we continued to undertake Amazon Bedrock and different AWS companies within the utility.
For the reason that Twitch Gross sales Bot launch in February 2024, we’ve answered over 11,000 questions in regards to the Twitch gross sales course of. As well as, Amazon sellers who used our generative AI answer delivered 25% extra Twitch income year-to-date when put next with sellers who didn’t, and delivered 120% extra income when in comparison with self-service accounts. We’ll proceed increasing our chat assistant’s agentic capabilities—utilizing Amazon Bedrock together with different AWS companies—to unravel new issues for our customers and improve Twitch backside line. We plan to include distinct Information Bases throughout Amazon portfolio of 1P Publishers like Prime Video, Alexa, and IMDb as a quick, correct, and complete generative AI answer to supercharge advert gross sales.
On your personal challenge, you possibly can comply with our structure and undertake an identical answer to construct an AI assistant to deal with your individual enterprise problem.
In regards to the Authors
 Bin Xu is a Senior Software program Engineer at Amazon Twitch Promoting and holds a Grasp’s diploma in Knowledge Science from Columbia College. Because the visionary creator behind TwitchBot, Bin efficiently launched the proof of idea in 2023. Bin is at the moment main a workforce in Twitch Advertisements Monetization, specializing in optimizing video advert supply, bettering gross sales workflows, and enhancing marketing campaign efficiency. Additionally main efforts to combine AI-driven options to additional enhance the effectivity and influence of Twitch advert merchandise. Outdoors of his skilled endeavors, Bin enjoys enjoying video video games and tennis.
Bin Xu is a Senior Software program Engineer at Amazon Twitch Promoting and holds a Grasp’s diploma in Knowledge Science from Columbia College. Because the visionary creator behind TwitchBot, Bin efficiently launched the proof of idea in 2023. Bin is at the moment main a workforce in Twitch Advertisements Monetization, specializing in optimizing video advert supply, bettering gross sales workflows, and enhancing marketing campaign efficiency. Additionally main efforts to combine AI-driven options to additional enhance the effectivity and influence of Twitch advert merchandise. Outdoors of his skilled endeavors, Bin enjoys enjoying video video games and tennis.
 Nick Mariconda is a Software program Engineer at Amazon Promoting, centered on enhancing the promoting expertise on Twitch. He holds a Grasp’s diploma in Laptop Science from Johns Hopkins College. When not staying updated with the most recent in AI developments, he enjoys getting outside for climbing and connecting with nature.
Nick Mariconda is a Software program Engineer at Amazon Promoting, centered on enhancing the promoting expertise on Twitch. He holds a Grasp’s diploma in Laptop Science from Johns Hopkins College. When not staying updated with the most recent in AI developments, he enjoys getting outside for climbing and connecting with nature.
 Frank Zhu is a Senior Product Supervisor at Amazon Promoting, positioned in New York Metropolis. With a background in programmatic ad-tech, Frank helps join the enterprise wants of advertisers and Amazon publishers via revolutionary promoting merchandise. Frank has a BS in finance and advertising and marketing from New York College and out of doors of labor enjoys digital music, poker idea, and video video games.
Frank Zhu is a Senior Product Supervisor at Amazon Promoting, positioned in New York Metropolis. With a background in programmatic ad-tech, Frank helps join the enterprise wants of advertisers and Amazon publishers via revolutionary promoting merchandise. Frank has a BS in finance and advertising and marketing from New York College and out of doors of labor enjoys digital music, poker idea, and video video games.
 Yunfei Bai is a Principal Options Architect at AWS. With a background in AI/ML, information science, and analytics, Yunfei helps clients undertake AWS companies to ship enterprise outcomes. He designs AI/ML and information analytics options that overcome complicated technical challenges and drive strategic aims. Yunfei has a PhD in Digital and Electrical Engineering. Outdoors of labor, Yunfei enjoys studying and music.
Yunfei Bai is a Principal Options Architect at AWS. With a background in AI/ML, information science, and analytics, Yunfei helps clients undertake AWS companies to ship enterprise outcomes. He designs AI/ML and information analytics options that overcome complicated technical challenges and drive strategic aims. Yunfei has a PhD in Digital and Electrical Engineering. Outdoors of labor, Yunfei enjoys studying and music.
 Cathy Willcock is a Principal Technical Enterprise Growth Supervisor positioned in Seattle, WA. Cathy leads the AWS technical account workforce supporting Amazon Advertisements adoption of AWS cloud applied sciences. Her workforce works throughout Amazon Advertisements enabling discovery, testing, design, evaluation, and deployments of AWS companies at scale, with a specific concentrate on innovation to form the panorama throughout the AdTech and MarTech trade. Cathy has led engineering, product, and advertising and marketing groups and is an inventor of ground-to-air calling (1-800-RINGSKY).
Cathy Willcock is a Principal Technical Enterprise Growth Supervisor positioned in Seattle, WA. Cathy leads the AWS technical account workforce supporting Amazon Advertisements adoption of AWS cloud applied sciences. Her workforce works throughout Amazon Advertisements enabling discovery, testing, design, evaluation, and deployments of AWS companies at scale, with a specific concentrate on innovation to form the panorama throughout the AdTech and MarTech trade. Cathy has led engineering, product, and advertising and marketing groups and is an inventor of ground-to-air calling (1-800-RINGSKY).
Acknowledgments
We’d additionally prefer to acknowledge and categorical our gratitude to our management workforce: Abhoy Bhaktwatsalam (VP, Amazon Writer Monetization), Carl Petersen (Director, Twitch, Audio & Podcast Monetization), Cindy Barker (Senior Principal Engineer, Amazon Writer Insights & Analytics), and Timothy Fagan (Principal Engineer, Twitch Monetization), for his or her invaluable insights and assist. Their experience and backing have been instrumental for the profitable improvement and implementation of this revolutionary answer.



{kind=link}