Suggestion Methods
Present ML fashions can advocate comparable merchandise, however how about complementary?
Within the area of AI Suggestion Methods, Machine Studying fashions have been closely used to advocate comparable samples, whether or not merchandise, content material and even suggesting comparable contacts. Most of those pre-trained fashions are open-source and can be utilized with out coaching a mannequin from scratch. Nonetheless, with the dearth of Huge Knowledge, there is no such thing as a open-source expertise we will depend on for the advice of complementary merchandise.
Within the following article, I’m proposing a framework (with code within the type of a user-friendly library) that exploits LLM for the invention of complementary merchandise in a non-expensive method.
My purpose for introducing this framework is for it to be:
- Scalable
It’s a framework that ought to not require supervision when working, that doesn’t threat breaking, and the output ought to be simply structured for use together with further instruments. - Reasonably priced
It ought to be inexpensive to search out the complementary of 1000’s of merchandise with minimal spending (approx. 1 USD per 1000 computed merchandise — utilizing groq pricing), as well as, with out requiring any fine-tuning (which means that it might even be examined on a single product).
***Full zeroCPR code is open-source and accessible at my Github repo, be at liberty to contact me for help or characteristic requests. On this article, I’m introducing each the framework (and its respective library) zeroCPR and a brand new prompting approach that I name Chain-of-DataFrame for listing reasoning.
Earlier than digging into the idea of the zeroCPR framework, allow us to perceive why present expertise is proscribed on this very area:
Why do neural networks excel at recommending comparable merchandise?
These fashions excel at this job as a result of neural networks innately group samples with widespread options in the identical house area. To simplify, if, for instance, a neural community is educated on high of the human language, it should allocate in the identical house area phrases or sentences which have comparable meanings. Following the identical precept, if educated on high of buyer habits, prospects sharing comparable habits can be organized in comparable house areas.

The fashions able to recommending comparable sentences are known as semantic fashions, and they’re each mild and accessible, permitting the creation of advice techniques that depend on language similarity somewhat than buyer habits.
A retail firm that lacks buyer information can simply advocate comparable merchandise by exploiting the capabilities of a semantic mannequin.
What about complementary merchandise?
Nonetheless, recommending complementary merchandise is a completely completely different job. To my data, no open-source mannequin is able to performing such an enterprise. Retail corporations practice their customized complementary recommender techniques primarily based on their information, leading to fashions which can be troublesome to generalize, and which can be industry-specific.
zeroCPR stands for zero-shot complementary product recommender. The functioning is straightforward. By receiving a listing of your accessible merchandise and reference merchandise, it tried to search out if in your listing there are complementary merchandise that may be advisable.
Massive Language Fashions can simply advocate complementary merchandise. You may ask ChatGPT to output what merchandise may be paired with a toothbrush, and it’ll probably advocate dental floss and toothpaste.
Nonetheless, my purpose is to create an enterprise-grade instrument that may work with our customized information. ChatGPT could also be appropriate, however it’s producing an unstructured output that can not be built-in with our listing of merchandise.
The zeroCPR framework may be outlined as follows, the place we apply the next 3 steps for every product in our product listing:

1. Record complementary merchandise
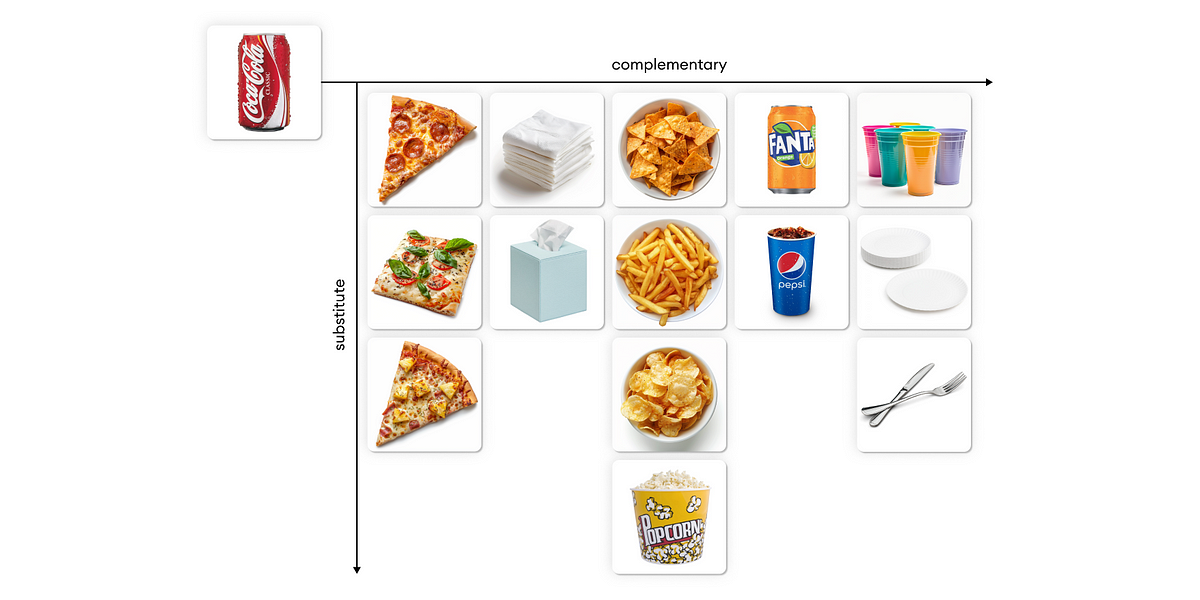
As defined, the primary bottleneck to resolve is discovering precise complementary merchandise. As a result of similarity fashions are out of the query, we have to use a LLM. The execution of step one is sort of easy. Given an enter product (ex. Coca-Cola), produce a listing of legitimate complementary merchandise a person could buy with it.
I’ve requested the LLM to output a superbly parsable listing utilizing Python: as soon as parsed, we will visualize the output.

The outcomes usually are not dangerous in any respect: these are all merchandise which can be prone to be bought in pairs with Coca-Cola. There’s, nonetheless, a small concern: THESE PRODUCTS MAY NOT BE IN OUR DATA.
2. Matching the accessible merchandise in our information
The following step is making an attempt to match each complementary product urged by the LLM with a corresponding product in our dataset. For instance, we wish to match “Nachos” with the closest doable product in our dataset.
We are able to carry out this matching utilizing vector search. For every LLM product, we are going to match it with probably the most semantically comparable in our dataset.

As we will see, the outcomes are removed from correct. “Nachos” can be matched with “SET OF SALT AND PEPPER TOADSTOOLS”, whereas the closest match with “Burgers” is “S/2 BEACH HUT STOOLS”. A number of the matches are legitimate (we will have a look at Napkins), but when there aren’t any legitimate matches, a semantic search will nonetheless match it with an irrelevant candidate. Utilizing a cosine similarity threshold is, by expertise, a horrible technique for choosing legitimate decisions. As an alternative, I’ll use an LLM once more to validate the information.
3. Choose appropriate enhances utilizing Chain-of-DataFrame
The purpose is now to validate the matching of the earlier step. My first makes an attempt to match the merchandise advisable by an LLM have been annoyed by the dearth of coherence within the output. Although being a 70B mannequin, once I was passing within the immediate a listing of merchandise to match, the output was lower than fascinating (with combos of errors within the formatting and extremely unrealistic output).
Nonetheless, I’ve seen that by inputting a listing of merchandise and asking the mannequin to purpose on every pattern and output a rating (0 or 1): (following the format of a pandas dataframe and making use of a change to a single column), the mannequin is way more dependable (when it comes to format and output). I name this prompting paradigm Chain-of-Dataframe, in reference to the well-known pandas information construction:

To offer you an concept of the Chain-of-Dataframe prompting. Within the following instance, the {product_name} is coca-cola, whereas the {complementary_list} is the column known as recommended_product we will see within the picture under:
A buyer is doing procuring and buys the next product
product_name: {product_name}A junior procuring knowledgeable recommends the next merchandise to be purchased collectively, nonetheless he nonetheless has to study:
given the next
complementary_list: {complementary_list}
Output a parsable python listing utilizing python, no feedback or further textual content, within the following format:
[
[, , <0 or 1>],
[, , <0 or 1>],
[, , <0 or 1>],
...
]
the shopper is just thinking about **merchandise that may be paired with the prevailing one** to complement his expertise, not substitutes
THE ORDER OF THE OUTPUT MUST EQUAL THE ORDER OF ELEMENTS IN complementary_list
Take it straightforward, take an enormous breath to chill out and be correct. Output should begin with [, end with ], no further textual content
The output is a multidimensional listing that may be parsed simply and instantly transformed once more right into a pandas dataframe.

Discover the reasoning and rating columns generated by the mannequin to search out the greatest complementary merchandise. With this final step, now we have been capable of filter out a lot of the irrelevant matches.
***The algorithm could look just like CHAIN-OF-TABLE: EVOLVING TABLES IN THE REASONING CHAIN FOR TABLE UNDERSTANDING, however I deem the one proposed above is far less complicated and makes use of a special construction. Be happy to remark when you suppose in any other case.
4. Coping with little information: Nearest Substitute Filling
There’s one final concern we have to deal with. It’s probably that, because of the lack of information, the variety of advisable merchandise is minimal. Within the instance above, we will advocate 6 complementary merchandise, however there is perhaps instances the place we will solely advocate 2 or 3. How can we enhance the person expertise, and broaden the variety of legitimate suggestions, given the restrictions imposed by our information?



{kind=link}