This publish is cowritten with Isaac Cameron and Alex Gnibus from Tecton.
Companies are beneath strain to indicate return on funding (ROI) from AI use instances, whether or not predictive machine studying (ML) or generative AI. Solely 54% of ML prototypes make it to manufacturing, and solely 5% of generative AI use instances make it to manufacturing.
ROI isn’t nearly attending to manufacturing—it’s about mannequin accuracy and efficiency. You want a scalable, dependable system with excessive accuracy and low latency for the real-time use instances that immediately affect the underside line each millisecond.
Fraud detection, for instance, requires extraordinarily low latency as a result of choices have to be made within the time it takes to swipe a bank card. With fraud on the rise, extra organizations are pushing to implement profitable fraud detection techniques. The US nationwide fraud losses topped $10 billion in 2023, a 14% improve from 2022. International ecommerce fraud is predicted to exceed $343 billion by 2027.
However constructing and managing an correct, dependable AI software that may make a dent in that $343 billion downside is overwhelmingly advanced.
ML groups typically begin by manually stitching collectively totally different infrastructure parts. It appears easy at first for batch knowledge, however the engineering will get much more difficult when you might want to go from batch knowledge to incorporating real-time and streaming knowledge sources, and from batch inference to real-time serving.
Engineers must construct and orchestrate the information pipelines, juggle the totally different processing wants for every knowledge supply, handle the compute infrastructure, construct dependable serving infrastructure for inference, and extra. With out the capabilities of Tecton, the structure would possibly appear like the next diagram.

Speed up your AI improvement and deployment with Amazon SageMaker and Tecton
All that guide complexity will get simplified with Tecton and Amazon SageMaker. Collectively, Tecton and SageMaker summary away the engineering wanted for manufacturing, real-time AI purposes. This permits sooner time to worth, and engineering groups can deal with constructing new options and use instances as a substitute of struggling to handle the prevailing infrastructure.
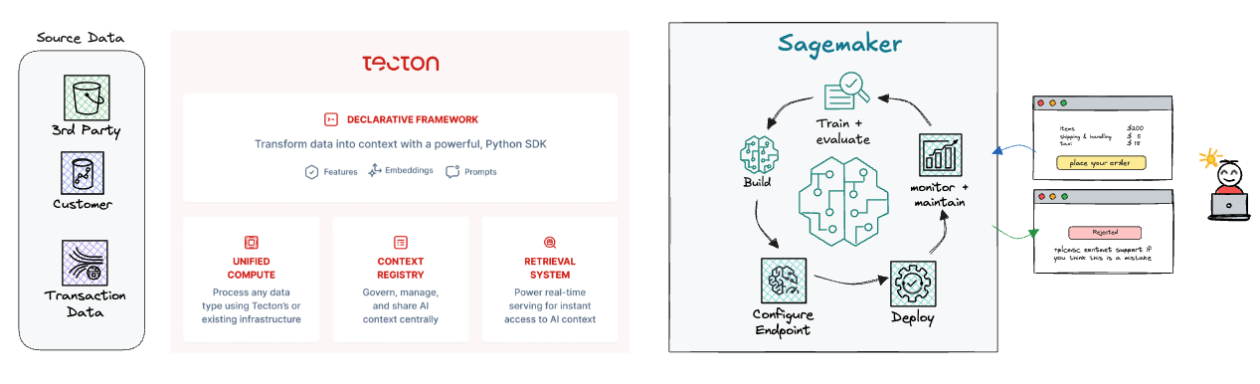
Utilizing SageMaker, you possibly can construct, practice and deploy ML fashions. In the meantime, Tecton makes it easy to compute, handle, and retrieve options to energy fashions in SageMaker, each for offline coaching and on-line serving. This streamlines the end-to-end characteristic lifecycle for production-scale use instances, leading to an easier structure, as proven within the following diagram.

How does it work? With Tecton’s simple-to-use declarative framework, you outline the transformations in your options in a couple of strains of code, and Tecton builds the pipelines wanted to compute, handle, and serve the options. Tecton takes care of the total deployment into manufacturing and on-line serving.
It doesn’t matter if it’s batch, streaming, or real-time knowledge or whether or not it’s offline or on-line serving. It’s one widespread framework for each knowledge processing want in end-to-end characteristic manufacturing.
This framework creates a central hub for characteristic administration and governance with enterprise characteristic retailer capabilities, making it easy to watch the information lineage for every characteristic pipeline, monitor knowledge high quality, and reuse options throughout a number of fashions and groups.
The next diagram reveals the Tecton declarative framework.

The following part examines a fraud detection instance to indicate how Tecton and SageMaker speed up each coaching and real-time serving for a manufacturing AI system.
Streamline characteristic improvement and mannequin coaching
First, you might want to develop the options and practice the mannequin. Tecton’s declarative framework makes it easy to outline options and generate correct coaching knowledge for SageMaker fashions:
- Experiment and iterate on options in SageMaker notebooks – You should use Tecton’s software program improvement equipment (SDK) to work together with Tecton immediately by SageMaker pocket book cases, enabling versatile experimentation and iteration with out leaving the SageMaker setting.
- Orchestrate with Tecton-managed EMR clusters – After options are deployed, Tecton robotically creates the scheduling, provisioning, and orchestration wanted for pipelines that may run on Amazon EMR compute engines. You’ll be able to view and create EMR clusters immediately by the SageMaker pocket book.
- Generate correct coaching knowledge for SageMaker fashions – For mannequin coaching, knowledge scientists can use Tecton’s SDK inside their SageMaker notebooks to retrieve historic options. The identical code is used to backfill the offline retailer and regularly replace the net retailer, decreasing coaching/serving skew.
Subsequent, the options have to be served on-line for the ultimate mannequin to devour in manufacturing.
Serve options with sturdy, real-time on-line inference
Tecton’s declarative framework extends to on-line serving. Tecton’s real-time infrastructure is designed to assist meet the calls for of intensive purposes and may reliably run 100,000 requests per second.
For crucial ML apps, it’s arduous to fulfill demanding service degree agreements (SLAs) in a scalable and cost-efficient method. Actual-time use instances corresponding to fraud detection sometimes have a p99 latency price range between 100 to 200 milliseconds. Meaning 99% of requests have to be sooner than 200ms for the end-to-end course of from characteristic retrieval to mannequin scoring and post-processing.
Characteristic serving solely will get a fraction of that end-to-end latency price range, which suggests you want your answer to be particularly fast. Tecton accommodates these latency necessities by integrating with each disk-based and in-memory knowledge shops, supporting in-memory caching, and serving options for inference by a low-latency REST API, which integrates with SageMaker endpoints.
Now we are able to full our fraud detection use case. In a fraud detection system, when somebody makes a transaction (corresponding to shopping for one thing on-line), your app would possibly observe these steps:
- It checks with different companies to get extra data (for instance, “Is that this service provider recognized to be dangerous?”) from third-party APIs
- It pulls vital historic knowledge concerning the consumer and their habits (for instance, “How typically does this particular person normally spend this a lot?” or “Have they made purchases from this location earlier than?”), requesting the ML options from Tecton
- It’ll possible use streaming options to check the present transaction with latest spending exercise over the previous few hours or minutes
- It sends all this data to the mannequin hosted on Amazon SageMaker that predicts whether or not the transaction appears to be like fraudulent.
This course of is proven within the following diagram.

Develop to generative AI use instances along with your present AWS and Tecton structure
After you’ve developed ML options utilizing the Tecton and AWS structure, you possibly can lengthen your ML work to generative AI use instances.
For example, within the fraud detection instance, you would possibly wish to add an LLM-powered buyer help chat that helps a consumer reply questions on their account. To generate a helpful response, the chat would wish to reference totally different knowledge sources, together with the unstructured paperwork in your data base (corresponding to coverage documentation about what causes an account suspension) and structured knowledge corresponding to transaction historical past and real-time account exercise.
When you’re utilizing a Retrieval Augmented Technology (RAG) system to supply context to your LLM, you should utilize your present ML characteristic pipelines as context. With Tecton, you possibly can both enrich your prompts with contextual knowledge or present options as instruments to your LLM—all utilizing the identical declarative framework.
To decide on and customise the mannequin that can greatest fit your use case, Amazon Bedrock gives a variety of pre-trained basis fashions (FMs) for inference, or you should utilize SageMaker for extra intensive mannequin constructing and coaching.
The next graphic reveals how Amazon Bedrock is included to help generative AI capabilities within the fraud detection system structure.

Construct worthwhile AI apps sooner with AWS and Tecton
On this publish, we walked by how SageMaker and Tecton allow AI groups to coach and deploy a high-performing, real-time AI software—with out the advanced knowledge engineering work. Tecton combines manufacturing ML capabilities with the comfort of doing every part from inside SageMaker, whether or not that’s on the improvement stage for coaching fashions or doing real-time inference in manufacturing.
To get began, check with Getting Began with Amazon SageMaker & Tecton’s Characteristic Platform, a extra detailed information on methods to use Tecton with Amazon SageMaker. And when you can’t wait to strive it your self, try the Tecton interactive demo and observe a fraud detection use case in motion.
You too can discover Tecton at AWS re:Invent. Attain out to arrange a gathering with specialists onsite about your AI engineering wants.
In regards to the Authors
 Isaac Cameron is Lead Options Architect at Tecton, guiding clients in designing and deploying real-time machine studying purposes. Having beforehand constructed a customized ML platform from scratch at a serious U.S. airline, he brings firsthand expertise of the challenges and complexities concerned—making him a robust advocate for leveraging fashionable, managed ML/AI infrastructure.
Isaac Cameron is Lead Options Architect at Tecton, guiding clients in designing and deploying real-time machine studying purposes. Having beforehand constructed a customized ML platform from scratch at a serious U.S. airline, he brings firsthand expertise of the challenges and complexities concerned—making him a robust advocate for leveraging fashionable, managed ML/AI infrastructure.
 Alex Gnibus is a technical evangelist at Tecton, making technical ideas accessible and actionable for engineering groups. Via her work educating practitioners, Alex has developed deep experience in figuring out and addressing the sensible challenges groups face when productionizing AI techniques.
Alex Gnibus is a technical evangelist at Tecton, making technical ideas accessible and actionable for engineering groups. Via her work educating practitioners, Alex has developed deep experience in figuring out and addressing the sensible challenges groups face when productionizing AI techniques.
 Arnab Sinha is a Senior Options Architect at AWS, specializing in designing scalable options that drive enterprise outcomes in AI, machine studying, large knowledge, digital transformation, and software modernization. With experience throughout industries like power, healthcare, retail and manufacturing, Arnab holds all AWS Certifications, together with the ML Specialty, and has led know-how and engineering groups earlier than becoming a member of AWS.
Arnab Sinha is a Senior Options Architect at AWS, specializing in designing scalable options that drive enterprise outcomes in AI, machine studying, large knowledge, digital transformation, and software modernization. With experience throughout industries like power, healthcare, retail and manufacturing, Arnab holds all AWS Certifications, together with the ML Specialty, and has led know-how and engineering groups earlier than becoming a member of AWS.



{kind=link}