This ChatGPT immediate and its corresponding (incorrect) response had been not too long ago shared and re-posted on LinkedIn numerous instances. They got as a stable proof that the AGI is simply not there but. Additional re-posts additionally identified that re-arranging the immediate to: “Which one is greater: 9.11 or 9.9?”, ensures an accurate reply, and additional emphasizes the brittleness of LLMs.
After evaluating each prompts in opposition to a random group of ChatGPT customers, we discovered that in each instances the reply is incorrect about 50% of the time. As some customers have accurately identified, there’s a delicate ambiguity with the query, i.e. are we referring to mathematical inequality of two actual numbers, or are we referring to 2 dates (e.g. September 11 vs September 9), or two sub-sections in a doc (e.g. chapter 9.11 or 9.9)?
We determined to carry out a extra managed experiment through the use of OpenAI APIs. This fashion now we have full management over each the system immediate and the person immediate; we are able to additionally take out the sampling uncertainty out of the equation so far as attainable by e.g. setting the temperature low.
The ultimate outcomes are very fascinating!
Our hypotheses could be said as follows:
- Given the identical immediate, with none extra context, and with temperature stored near zero, we must always practically at all times receive the identical output, with secure log chances. Whereas folks consult with LLMs as “stochastic”, for a given enter, LLM ought to at all times generate the identical output; the “hallucinations” or variance comes from the sampling mechanism outdoors of the LLM, and this we are able to dampen considerably by setting a really low temperature worth.
- Based mostly on our random person checks with ChatGPT, we might anticipate each the unique immediate, and the re-worded model to provide incorrect reply 50% of the time — in different phrases, with out additional disambiguation or context, we wouldn’t anticipate one immediate to carry out higher than the opposite.
For our experiment design, we carry out the next:
- We conduct a lot of experiments, beginning with the unique immediate, adopted by a collection of “interventions”
- For every experiment/intervention, we execute 1 000 trials
- We use OpenAI’s most superior GPT-4o mannequin
- We set the temperature to 0.1 to basically eradicate the randomness resulting from sampling; we experiment with each random seed in addition to mounted seed
- To gauge the “confidence” of the reply, we acquire the log chance and calculate the linear chance of the reply in every trial; we plot the Kernel Density Estimate (KDE) of the linear chances throughout the 1 000 trials for every of the experiments
The complete code for our experimental design is out there right here.
The person immediate is ready to “9.11 or 9.9 — which one is greater?”.
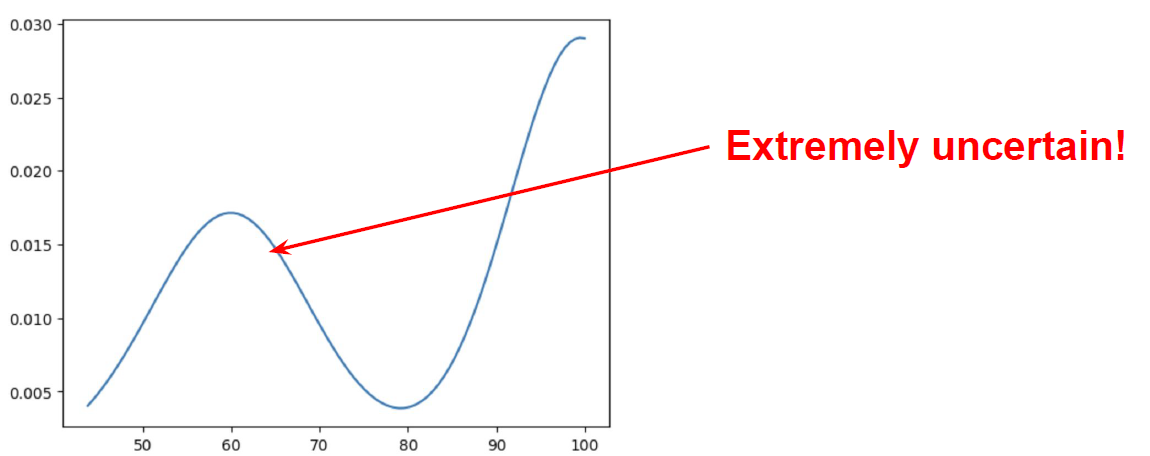
In keeping with what social media customers have reported, GPT-4o offers the proper reply 55% of the time ☹️. The mannequin can be not very sure — on massive variety of trials, its “confidence” within the reply is ~80%.

Within the re-worded person immediate, no extra context/disambiguation is offered, however the wording is barely modified to: “Which one is greater, 9.11 or 9.9?”
Amazingly, and opposite to our ChatGPT person checks, the right reply is reached 100% of the time throughout 1 000 trials. Moreover, the mannequin reveals very excessive confidence in its reply 🤔.

There was vital work not too long ago in attempting to induce improved “reasoning” capabilities in LLMs with chain-of-thought (CoT) prompting being the most well-liked. Huang et al have printed a really complete survey on LLM reasoning capabilities.
As such, we modify the unique person immediate by additionally telling the LLM to elucidate its reasoning. Apparently sufficient, the chance of right reply improves to 62%, nevertheless the solutions include even higher uncertainty.

The ultimate experiment is similar as experiment “C”, nevertheless we as an alternative bootstrap the system immediate by telling the LLM to “clarify its reasoning”. Extremely, we now see the right reply 100% of the time, with very excessive confidence. We see an identical outcomes if we use the re-worded person immediate as properly.

What began off as a easy experiment to validate a few of the statements seen on social media, ended up with some very fascinating findings. Let’s summarize the important thing takeaways:
- For an an identical immediate, with each temperature set very low (basically eliminating sampling uncertainty), and a set seed worth, we see very massive variance in log chances. Slight variance could be defined by {hardware} precision, however variance this huge may be very troublesome to elucidate. It signifies that both (1) sampling mechanism is a LOT extra sophisticated, or (2) there are extra layers/fashions upstream past our management.
- In keeping with earlier literature, merely instructing the LLM to “clarify its reasoning” improves its efficiency.
- There’s clearly a definite dealing with between the system immediate and the person immediate. Bootstrapping a task within the system immediate versus the person immediate, appears to end in considerably higher efficiency.
- We will clearly see how brittle the prompts could be. The important thing takeaway right here is that we must always at all times purpose to offer disambiguation and clear context in our prompts.



{kind=link}